
This article is the part of the series related to mastering DP-500 certification exam: Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI
Table of contents
During the evolution of Microsoft Power BI as an independent product (2015), from a shy challenger in the BI analytics space to an undeniable leader, there were many “game changers” – features that brought revolution instead of evolution! Composite models, Dataflows, AI-powered visuals, Hybrid tables, Bookmarks…You name it!
However, one of the features that truly opened a whole new world of possibilities, but which is probably still “under the radar” outside of the community of the experienced Power BI practitioners is – using XMLA endpoint to access the underlying Power BI datasets!
Although a lot of people consider Power BI as a data visualization tool, I have to admit that Power BI is a data modeling tool in the first place! And, that’s why it’s extremely important to understand what are XMLA endpoints and why should you care about them.
What is XMLA?
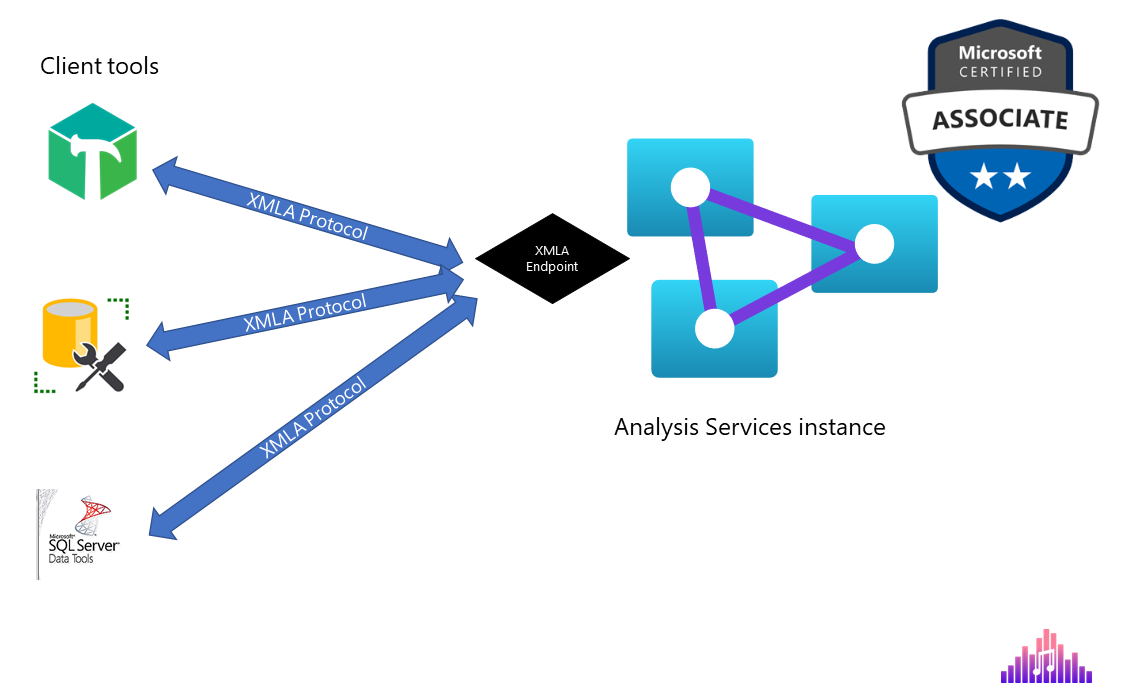
Let’s start with the basics. You’ve maybe heard about XML, but what on Earth is now XMLA?! Don’t be afraid – it’s just that – XML for Analysis! Instead of citing the dry definition of XMLA, let me try to illustrate how this “thing” works:
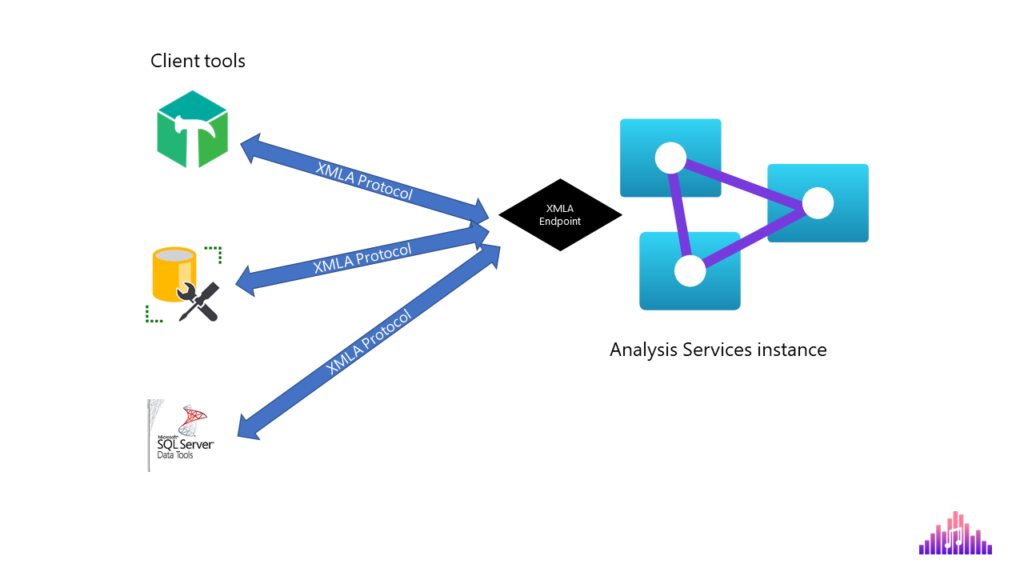
Simply said, the instance of Analysis Services “exposes” an endpoint, which can be then used by various client tools, such as Tabular Editor, SSMS, Azure Data Studio, SQL Server Data Tools, etc. to “talk” with Analysis Services instance. If you’re wondering – ok, Nikola, what’s so special about being able to “talk” to AS instance…Well, like in regular real-life talk, where you can instruct someone what to do, the same applies to a “talk” with Analysis Services instance: using a client tool you may read the content of the AS instance, but what’s even more important, you can also manipulate the TOM (Tabular Object Model) stored in Analysis Services instance, and modify its default behavior!
History lessons – SSAS and Co.
If you think of XMLA endpoint as some brand-new, Power BI-exclusive feature, you can’t be more wrong! For us who used to work with SSAS Multidimensional, using XMLA is a well-known concept. So, it’s a long-lasting relationship between the Analysis Services and XMLA…Now, you’re probably asking yourselves: why does he persistently repeat “Analysis Services”, “Analysis Services”? I’m a Power BI developer and I’m interested to find out how this “XMLA thing” works in Power BI!
Fair point, so let’s explain this one. When you open Power BI Desktop to create a solution (I’ve intentionally used word solution instead of the report), Power BI will spin up a local instance of Analysis Services (there you go again with Analysis Services!) behind the scenes, to store the data you’re using in your solution – of course, assuming that you are using Import mode for your data. Once you’re done, you’ll deploy your solution to Power BI Service – and you’ll probably notice that two artifacts are deployed together – report and dataset.
Power BI Dataset is nothing else than a database in the Analysis Services instance!
Similarly, the Power BI workspace is nothing else than an Analysis Services instance that takes care of all your different databases (Power BI datasets).
Why does XMLA endpoint availability matter for Power BI?
Ok, so we’ve explained what is an XMLA and how it relates to Power BI. Now, let’s try to understand why having this feature is really a game-changer!
Before XMLA endpoint availability for Power BI solutions, the usual development process looked something like this:
You create a solution in Power BI Desktop, and once you’re done you deploy it to the Service. In case some changes have to be applied, you would have taken this file again in the Power BI Desktop, make desired changes, and publish it again.
And, it was an “all or nothing” approach before XMLA endpoint availability – you couldn’t have changed one table without reprocessing the whole dataset! But, we could somehow live with that… However, certain data model properties were completely unaccessible from the Power BI Desktop and there was no way to change their default behavior.
Now, let’s imagine this scenario: you have a giant Power BI report, with 20 tables, and you just need to apply a minor change to one of them. Instead of reprocessing the whole model, by leveraging the XMLA endpoint, you can reprocess only the table you modified!
Before I show you how it’s done, some settings on your Power BI tenant need to be done in advance. First of all, at the moment of writing, XMLA Read/Write requires some kind of Premium license, either per capacity or per user.
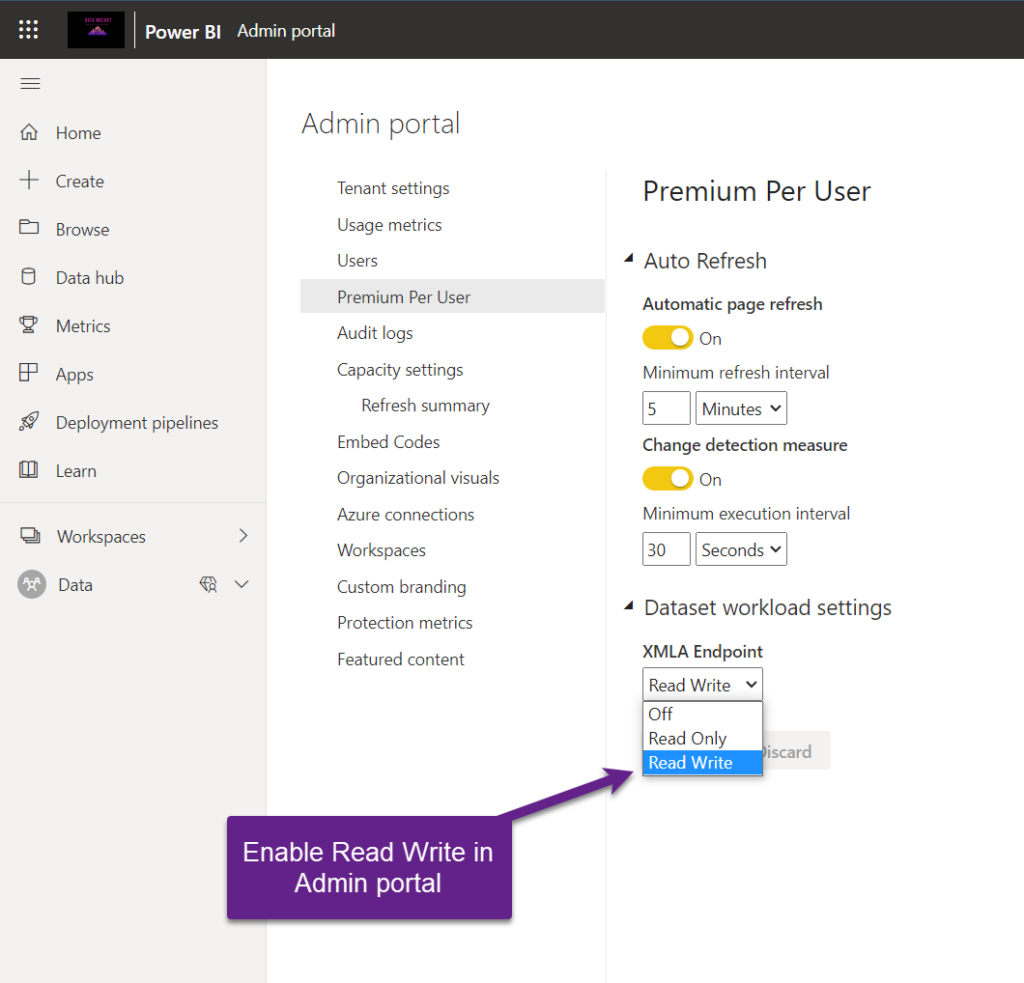
Once it’s enabled, I’ll go and grab the connection string of my premium workspace:
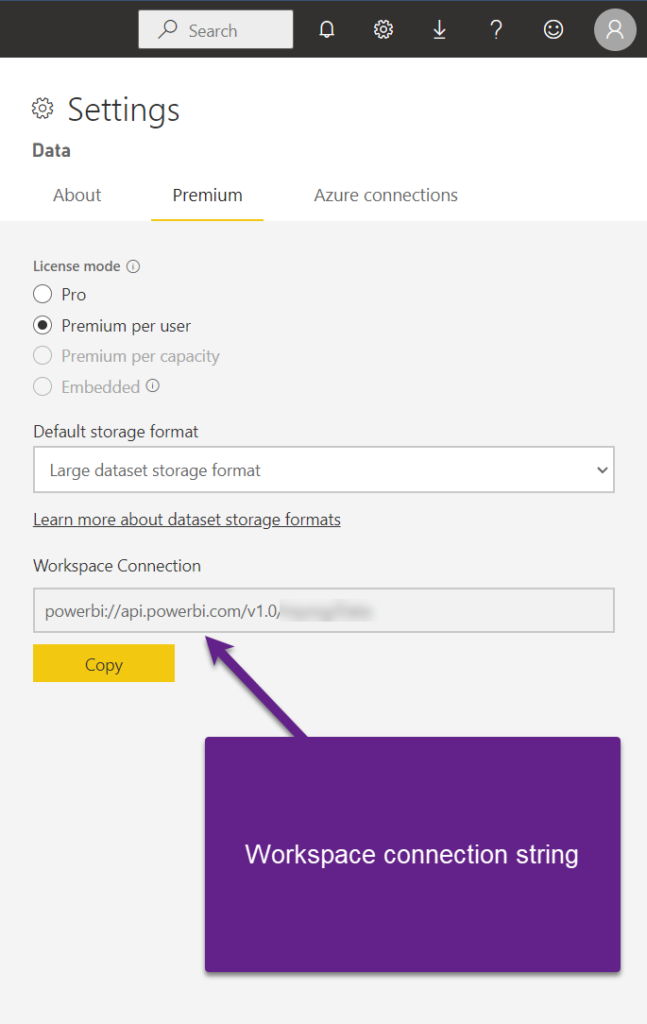
I’ll now open a client tool, in this example I’ll use Tabular Editor 2 (free version), but you can also use SSMS and obtain the same results. Once I connect to the Analysis Services instance (don’t forget, the Power BI workspace is nothing else but the instance of Analysis Services), I’ll be able to choose one of the databases (Power BI datasets) that I want to connect to:
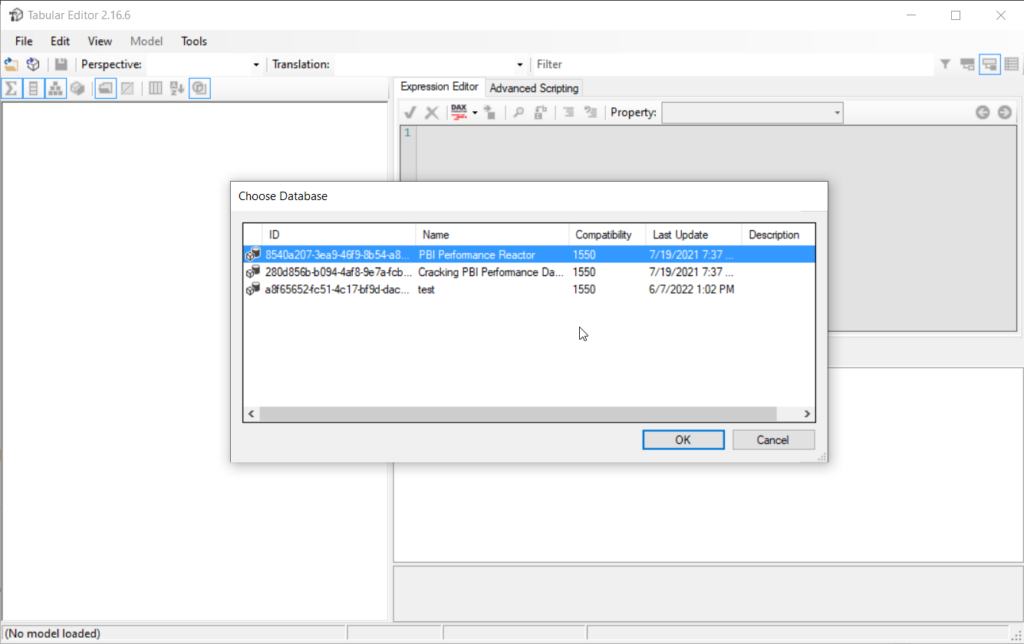
I’ll choose the third one, called test. Once I connect to the database, I can access a whole myriad of properties, not just on a model level, but also on a single table level.
Let’s imagine that I want to create a new measure in my FactInternetSales table, but instead of processing the whole data model, I’d like to process only the table I’ve changed:
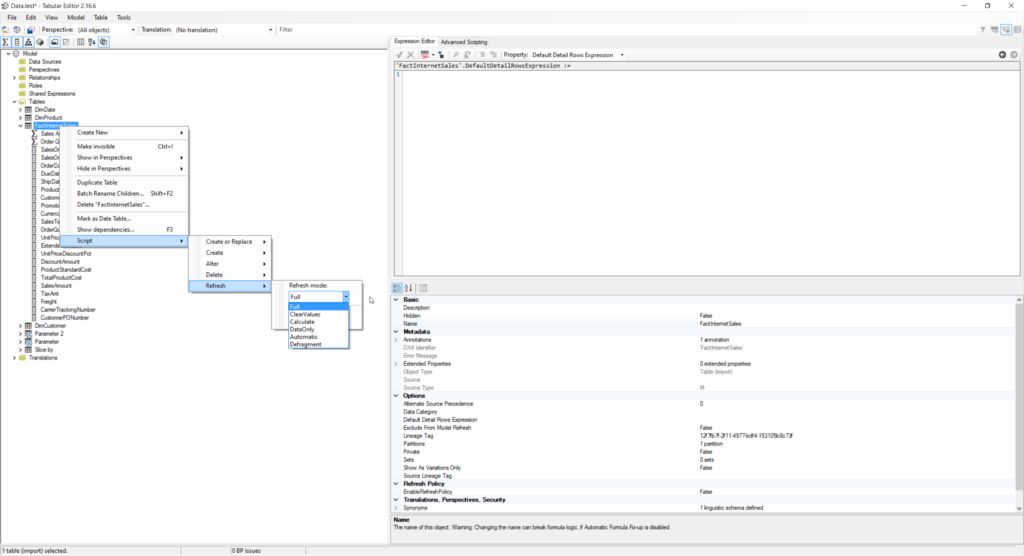
You can choose between different refresh modes. Explaining refresh modes is out of the scope of this article, but I suggest you check the details in the Tabular Editor documentation. This will trigger reprocessing of the selected table only, not the whole data model!
Obviously, by being able to use scripting to refresh the data on a fine-grain, you may even further enhance the whole process by leveraging PowerShell, Azure Functions, and similar.
Imagine the scenario where you have a table with a huge amount of historical data and you don’t want to refresh the whole table each and every time. You can split the table into multiple partitions (again, using XMLA endpoint), and then set incremental refresh for the latest partition(s), while not reloading older partitions again!
When to use XMLA endpoints?
Honestly, possibilities are really limitless! Except for the example I’ve previously shown for processing on a more granular level, you may also use XMLA endpoints to query the data, add new columns, or modify existing ones programmatically:
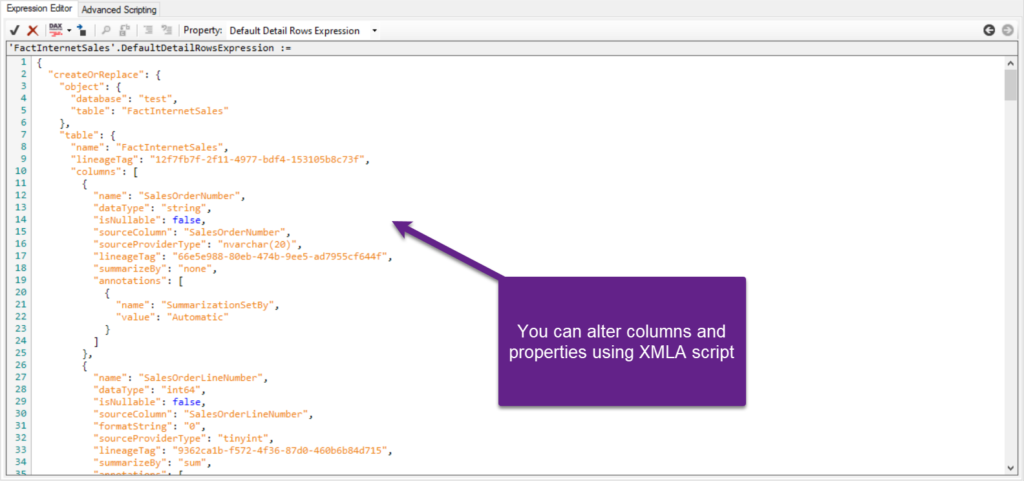
You can also switch data sources for your Power BI report, or add an explicit data source definition, as described here.
Additionally, all of the things you’re performing from, let’s say Tabular Editor, such as defining Object Level Security, Calculation groups, creating partitions, perspectives, etc. are done via XMLA endpoint!
Obviously, possibilities are limitless and probably a whole book can be written covering all the available use cases when using XMLA endpoints with Power BI…
Important remark: Keep in mind that once you made changes via XMLA endpoint and deploy the updated “version” of the Power BI solution to a Service, you WILL NOT be able to download the pbix file anymore! So, always keep the backup version of the file, in case you need to apply some additional modifications.
Conclusion
There were many “game-changers” during the Power BI evolution. Some of them lived up to their high expectations, and some of them did not. But, if you ask me, enabling XMLA endpoint for Power BI datasets is one of probably the Top 3 game-changers so far! Even though it’s (still) Premium feature only, and even though it has a serious limitation regarding the pbix download once the modified versions had been deployed, this is still one of the features that give you enormous power to customize Power BI datasets according to your needs.
Thanks for reading!
Last Updated on January 20, 2023 by Nikola


