

Do you know these nice new cars that will take you through the city jam by using electric power, while on the highway they help you to unleash the full power of the engine, by leveraging the traditional gasoline system? Sometimes the electric motor does all the work, sometimes it’s the gasoline engine, and sometimes they work together. The result is less gasoline burned and, therefore, better fuel economy (and, of course, a cleaner environment). Adding electric power can even boost performance in certain circumstances.
If you had hybrid cars on your mind, you were right…

Now, what do hybrid cars have in common with Power BI?! Well, since recently, they do – not the “cars” themselves, but this hybrid logic.
Hybrid tables – short retrospective
Microsoft announced the concept of the hybrid table in May, at the Business Application Summit. And, I have to admit that this was one of the features I was eagerly awaiting since then. Don’t get me wrong, all those cool sparklines, new formatting options, AI built-in features are nice…But, I’m simply a guy who cares more about the performance than about nice-looking dashboards and visuals:)
Disclaimer: At the moment of writing, Hybrid tables are still the preview feature, so it may happen that some of the functionalities are different once it becomes generally available.
So, what are the hybrid tables in the first place?
Well, before we answer this simple question, we need to go back and reiterate one of the basic concepts in Power BI – Storage mode. Once you start building your solution, you can choose between three different storage modes for your table: Import mode (which is a default, and most commonly used), DirectQuery (data resides out of the Power BI Tabular model before, during, and after the query execution), or Dual (data is imported into cache memory, but can also be served directly from the data source at the query time).
This specific consideration: “Should I use Import mode or DirectQuery?” was always a trade-off between the performance and requirements for the real-time data in the reports.
And, let’s now answer the original question: Hybrid tables combine Import and DirectQuery mode within a single table! Before we dive deeper and try to understand how hybrid tables behave in multiple different scenarios, let’s explain how hybrid tables may help you to achieve the best possible balance between the performance and real-time data requirements.
Scenario #1 – “Cold” data in Import mode, “Hot” data in DirectQuery
With this approach, you are basically prioritizing real-time requirements, but hybrid tables should help you achieve a better performance ratio than with a “pure” DirectQuery scenario. How’s that working? Well, let’s say that you have a giant fact table with 500 million rows. And, the business request is to have the data with the maximum latency of 1 minute – obviously, even if you’re able to load 500 million rows into the memory, there is no way to set the scheduled refresh so frequently!
So, the only viable option is to keep the table in DirectQuery mode and live with users’ complaints that the report is utterly slow. Not anymore! Here is what the hybrid table can do to save your day:

Let’s briefly examine the logic behind the illustration above. Imagine that most of your analytical queries are targeting figures from the last 7 days, but with an additional requirement to have the latest data in real-time! Historical data is not of particular interest, and it is just occasionally needed.
What are the benefits that the Hybrid table brings in this scenario? First of all, instead of keeping the whole “500 million rows” table in DirectQuery mode, only the “hottest” data stays in the partition that will be served using DirectQuery mode. And, I guess you can assume what would be the difference in the performance of the query that needs to scan 10.000 instead of 500 million rows…
Next, you can gain an additional performance boost for querying “recent” data (data from the last X days in the current month), as you may configure incremental refresh for this data and serve the queries from the cache memory…We’ll come later to see how to configure Hybrid tables to be used in this scenario, but I have great news: you basically don’t need to do anything specifically, except check a few checkboxes!
Scenario #2 – “Hot” data in Import mode, “cold” data in DirectQuery
The second scenario is 180 degrees from the previous one! And, this scenario is reminiscent of what we are doing now with aggregations and composite models to get the best of both worlds. Essentially, we’re keeping historical, low-level data in the original DirectQuery fact table, while aggregating “hot” data and importing it into Power BI to get the best performance provided by the VertiPaq engine.

With this setup, we’re prioritizing performance and reducing the data model size over real-time requirements. This scenario is suitable for those situations where most of the analytical queries target recent data, but without a specific requirement to have the real-time data! The idea is to reduce the memory footprint of the table, as the majority of data would not be imported into Power BI and will continue to “live” in the SQL database.
For this requirement, there is no out-of-the-box solution that will handle a Hybrid scenario for you, and some additional effort is needed to configure the table. Stay tuned, I’ll show you later how it’s done…
Setting the stage for Scenario #1
Ok, enough theory, it’s time to get our hands dirty and check how Hybrid tables work in reality. Let’s first examine scenario #1. But, before we configure Hybrid tables, I’ll first run a few test queries over the “regular” table, so we can compare the performance later.
I’ll be using a FactOnlineSales SQL Server table from the sample Contoso database, that contains 12.6 million rows. Imagine that our report users want to see the latest data in real-time, so we’ll keep our table in the pure DirectQuery mode.
I’ll just create a simple DAX measure to calculate the number of total rows:
Total Rows = COUNTROWS(FactOnlineSales)
I’ll also turn on the Performance Analyzer tool to capture the times generated by Power BI, as our table uses “pure” DirectQuery storage mode.
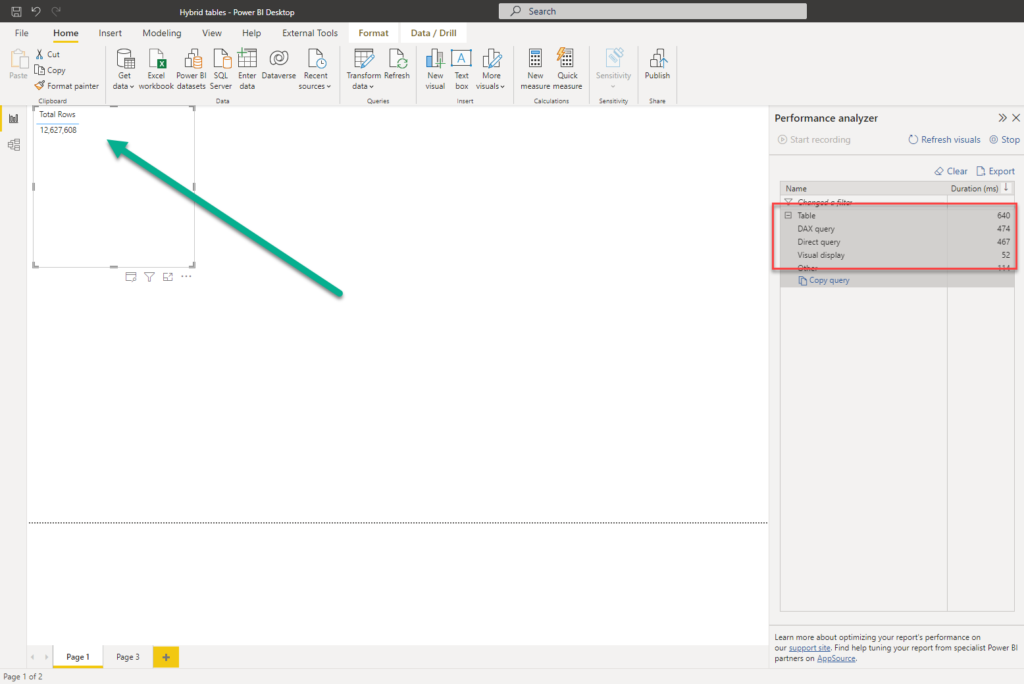
As you may see, there are 12.6 million rows in the table, and Power BI needed about 0.5 seconds to return the result. As my users need to see real-time data, I’ll turn on Auto Page refresh feature and set that my page refreshes every 30 seconds.
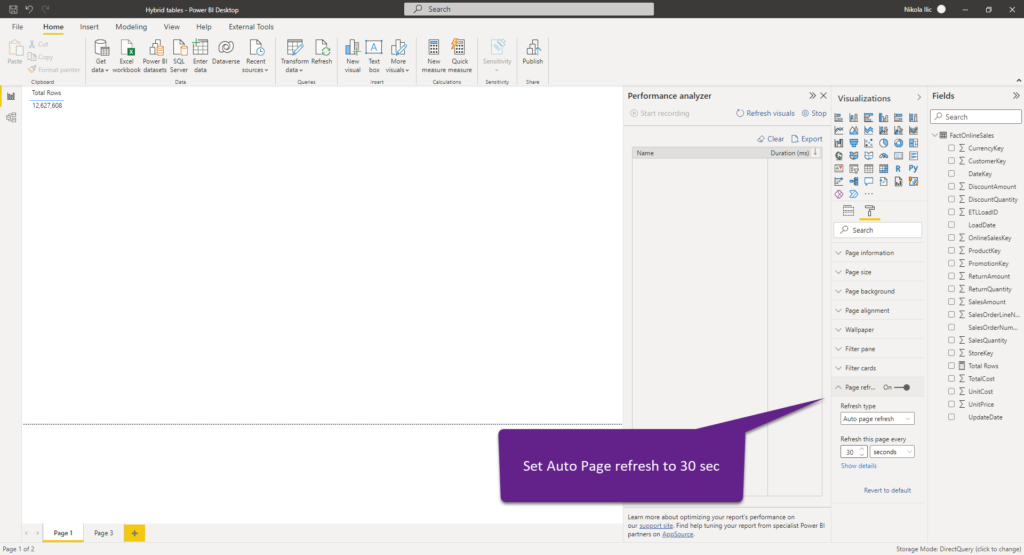
At the same time, I’ll run the following SQL query on the FactOnlineSales table:
WHILE 1=1
BEGIN
WAITFOR DELAY '00:00:05' -- Wait 5 seconds
INSERT INTO dbo.FactOnlineSales
(
DateKey,
StoreKey,
ProductKey,
PromotionKey,
CurrencyKey,
CustomerKey,
SalesOrderNumber,
SalesOrderLineNumber,
SalesQuantity,
SalesAmount,
ReturnQuantity,
ReturnAmount,
DiscountQuantity,
DiscountAmount,
TotalCost,
UnitCost,
UnitPrice,
ETLLoadID,
LoadDate,
UpdateDate
)
VALUES
( GETDATE(), -- DateKey - datetime
1, -- StoreKey - int
1, -- ProductKey - int
1, -- PromotionKey - int
1, -- CurrencyKey - int
1, -- CustomerKey - int
N'', -- SalesOrderNumber - nvarchar(20)
NULL, -- SalesOrderLineNumber - int
0, -- SalesQuantity - int
10, -- SalesAmount - money
0, -- ReturnQuantity - int
NULL, -- ReturnAmount - money
NULL, -- DiscountQuantity - int
NULL, -- DiscountAmount - money
5, -- TotalCost - money
NULL, -- UnitCost - money
NULL, -- UnitPrice - money
NULL, -- ETLLoadID - int
NULL, -- LoadDate - datetime
NULL -- UpdateDate - datetime
)
END
This statement will basically simulate a real transactional database, and insert a new row every 5 seconds. Please, don’t pay attention to all the values provided in the statement, as this is just a dummy table. Once I executed this statement and with Auto page refresh set to every 30 seconds, in each of the three runs, a query took around 0.5 seconds to return the total number of rows. You may notice how the number of rows is changing in the visual:

It’s time to configure our Hybrid table and see what happens then. The first step is to switch the table from DirectQuery to Import mode, as Hybrid tables work only for Import mode – essentially, by adding the “real-time” partition on top of it for the latest data using DirectQuery. Then I’ll publish the dataset to a premium workspace (I’m using PPU in this demo). Once I did that, I’ll go back and choose Incremental refresh for my table:
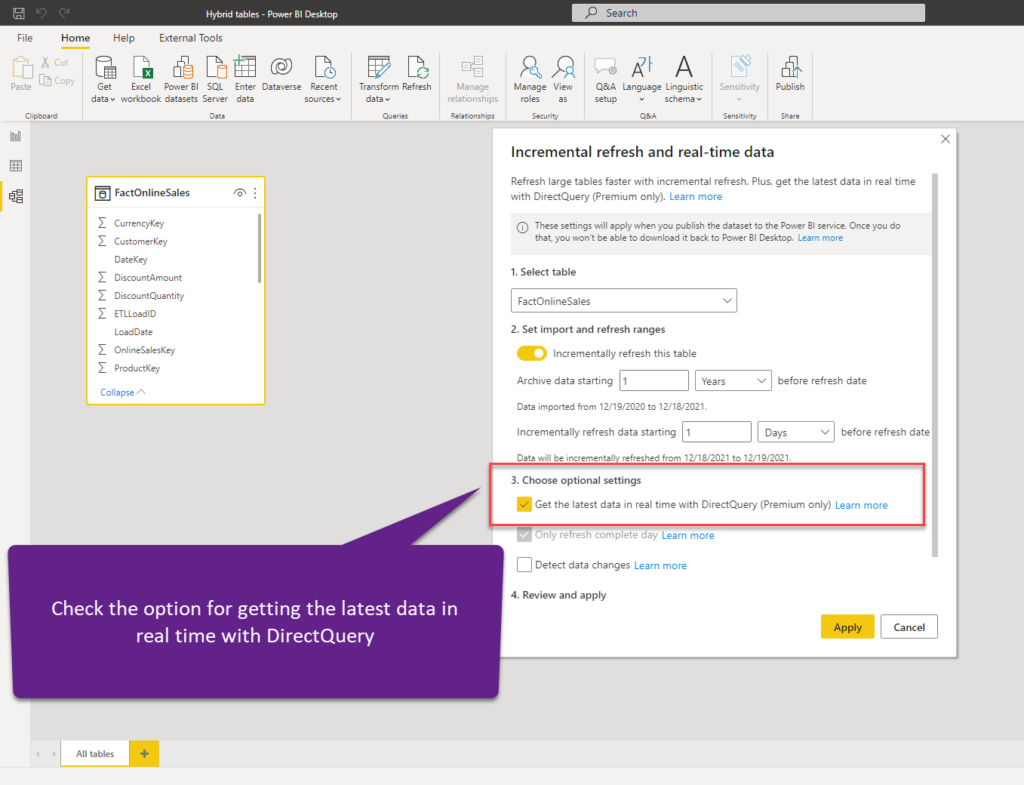
I’ll publish my dataset to Power BI Service and wait for the first refresh to complete (it may take a while, as table partitions need to be created and “cold” historical data loaded). Once it’s completed, here is our report:
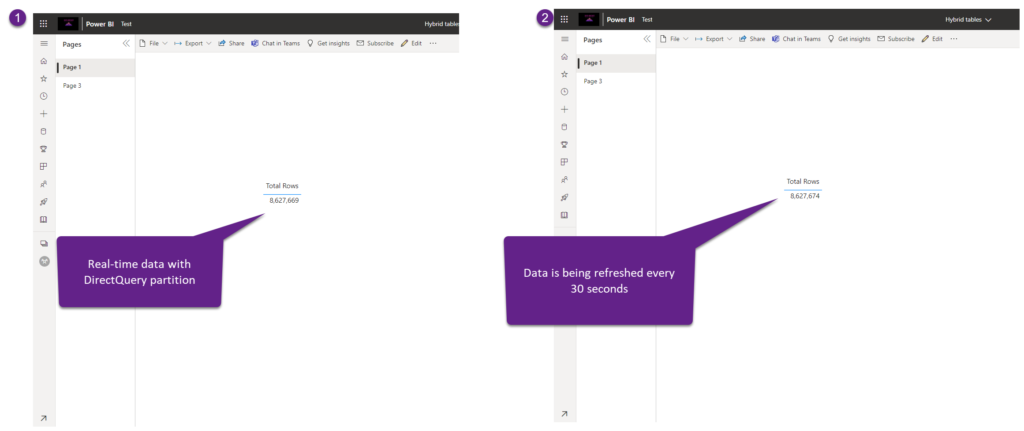
As you may spot, data changes in real-time, as we set Auto Page refresh to 30 seconds, and the DirectQuery partition scans only the latest data to satisfy this query request.
The key takeaway here is: by leveraging Hybrid tables, we managed to get the best from both worlds – keeping the blazing fast performance of the VertiPaq engine, while at the same enabling report consumers to have real-time updates of the data!
Configuring Scenario #2
In the second scenario, we can’t rely on Power BI to automatically apply the DirectQuery partition on top of the partitions with Import data. As already mentioned, in this case, we need some additional effort to set things up. The general idea is to flip the requirements and keep the “hot” data in Import mode, while leaving “cold” data in DirectQuery.
The first caveat here is that you can’t use Power BI Desktop for this scenario, as Power BI Desktop doesn’t let you create custom partitions. But, the great news here is that we can use external tools to manipulate TOM (Tabular Object Model) via the XMLA endpoint. The most popular tool for this purpose is Tabular Editor.
In a nutshell, we want to split “hot” and “cold” data into separate partitions:
SELECT * FROM FactOnlineSales WHERE DateKey >= DATEADD(MONTH, -3, CONVERT(DATE,GETDATE()))
This is the partition that will contain “hot” data, from the previous 3 months. You can adjust this threshold according to your needs.
This is how my partition definition looks in Tabular Editor:
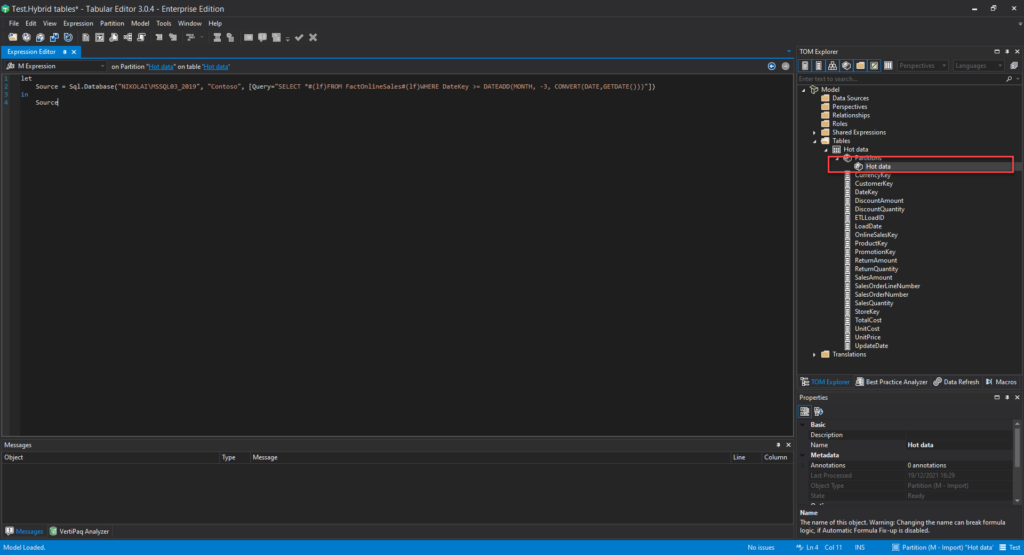
I’ve renamed the existing partition to Hot data. The next step is to duplicate this partition and adjust the source query to target only “cold” data (in my case, data older than 3 months):
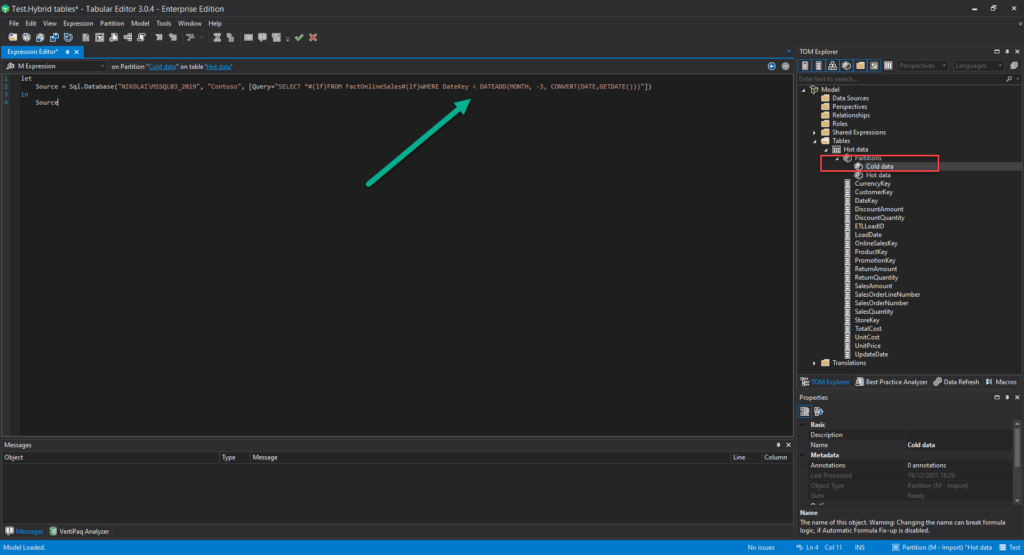
I’ll now switch the Mode property of this query from Import to DirectQuery:
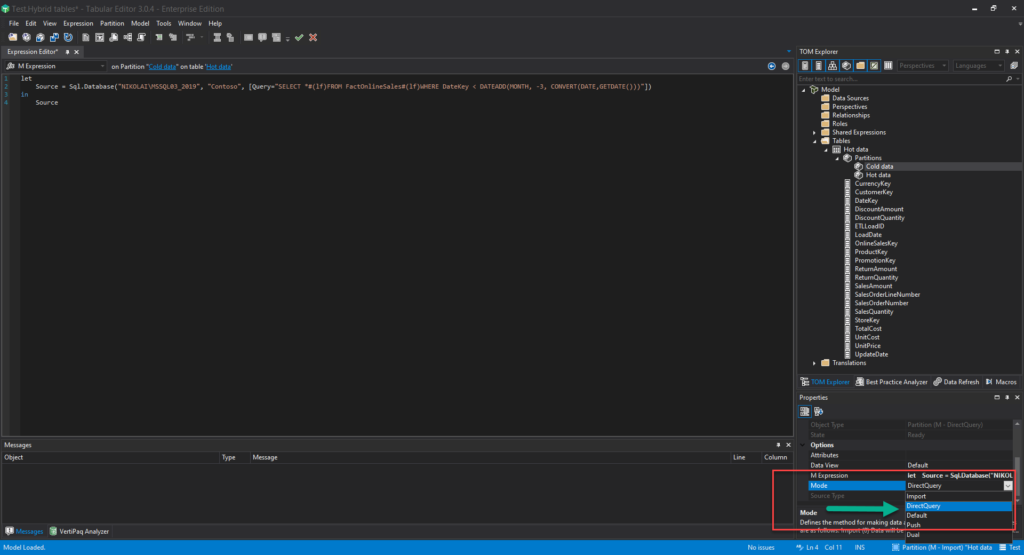
I’ll save the dataset with all the changes made and let’s turn on SQL Server Profiler to check how it behaves with different date slicing requirements:
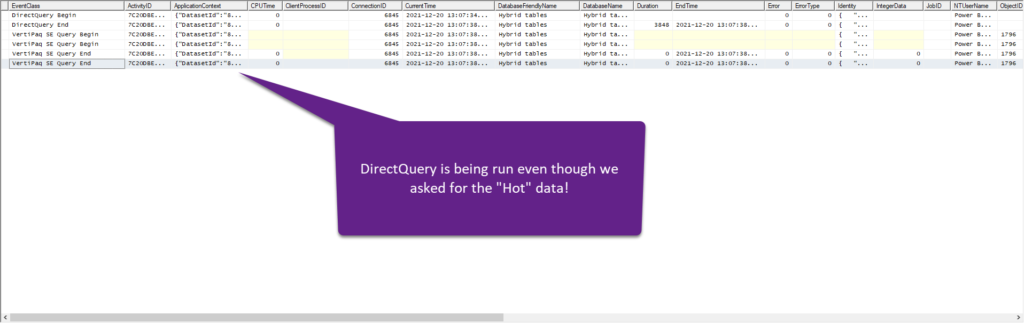
Even though we slice data from the last 3 months (“hot” data), there is still DirectQuery running in the background! Thanks for the heads up to Krystian Sakowski from Microsoft, who warned that this is (still) happening!
So, I was really hoping that instead of writing complex DAX to get the maximum performance, like in this case I explained here, by leveraging the hybrid concept, we would be able to get the best balance between the performance and memory footprint of our data model. However, it appears that the DirectQuery query will be run nevertheless if you’re slicing “hot” or “cold” data.
Considerations and limitations
No matter how cool and powerful look (and they ARE really cool and powerful), implementing Hybrid tables come with some limitations.
First of all, this is (at least for now) a Premium feature only, which means that you’ll need one of the P/EM/A SKUs, or PPU (Premium Per User) to take advantage of Hybrid tables.
Next, as the DirectQuery is involved in all scenarios, you should be aware of all general limitations that apply to a DirectQuery mode. That means, no complex Power Query transformations, no complex DAX calculations – or, to put it simple – forget anything that can’t be translated to SQL!
Also, no matter if you filter only the data from imported partitions, the DirectQuery partition will still be included in the scan. I sincerely hope that Microsoft engineers will come with a solution to eliminating the DirectQuery partition when not needed for the query.
Additionally, there are a few more things to keep in mind before you choose to go “hybrid”:
- Once you publish the dataset to Power BI Service, you can’t republish the same dataset again from Power BI Desktop, as this would remove any existing partitions and data that already exists in the dataset
- When you publish the dataset to Power BI Service, you can’t download the PBIX with the dataset back to Power BI Desktop
Thanks for reading!
Last Updated on December 20, 2021 by Nikola



Wouter De Raeve
Can partitions come from different tables?
Eg your import partition is one table and the DQ one is a different table (but they both have near-identical structures)?
If you then set up your ETL so your DQ-table is always the differential vs the import table, the scan to the DQ-table is not that costly…
Just don’t know if that is technically possible….
Nikola
Hi Wouter,
The approach you are proposing is possible and it’s called the Composite model. Basically, you keep one table in DQ mode, while the other(s) are in import mode.
More details here: https://docs.microsoft.com/en-us/power-bi/transform-model/desktop-composite-models
With Hybrid tables, you are simply splitting DQ and Import data within one same table. Hope this helps.
Ron
Hi Nikola, happy you write this article!! Trying to understand. So:
– scenario 1 is where the direct query data is recent/hot and the imported data is cold
– scenario 2 is where the imported, aggregated data is recent/hot and the directquery data is cold?
What if you have a composite model, that is only refreshed at the beginning of day (so no real-time data) whereby the requirement is that I want to have insight in aggregated (import) and very recent detailed (direct query) data ?
Is it then better just to stick to the composite model?
regards
Ron
Nikola
Hi Ron,
Well, the only correct answer is “it depends”:)
If you’re using a composite model where tables are with different granularity (I’m assuming the import data is aggregated per year/month/product/whatever…and DQ table goes to the lowest level of granularity), then I’d say you should stick with composite model. Because, in the end, a Hybrid table is just a table: so, you can’t define different granularities within one single table.
Kamil Kaleciński
Great Article, thanks for clarifying how 2nd Scenario should be configured in practice, as I immediately imagined this version while learning about Hybrid table preview. I only have one question – Tabular Editor was raising an error until I set an import partition Data View to Sample mode. Do you know why it was needed and if there are any consequences related?
Kamil Kaleciński
Doesn`t matter, just found that the problem was caused by an incorrect Compatibility Mode. When I switched from 1500 to 1565, it is all working as expected, so I am just leaving a hint to the others. Great feature!
Martina
Hi,
we are trying to apply scenario #2 on our power bi data model. I would like to ask what is/should be the settings of Data view for each partition.. Because we created 2 partitions – import with data view Full and DirectQuery with data view Sample (as Full or Default is not posible to choose). After finishing the full process of appropriate table in SSMS, only data from DirectQuery are displayed in report/excel. Can it be caused by partition setting on Sample data view? Or do you have any idea where could be the problem? Thanks.
Krystian Sakowski
you shouldn’t set up any data view settings.
that feature is deprecreated & discontinued for powerbi.
did you upgrade compatibility level of your dataset to 1565 like Kay did in his article?
https://powerbi.microsoft.com/en-us/blog/announcing-public-preview-of-hybrid-tables-in-power-bi-premium/
w/o doing that indeed you can observe some legacy errors mentioning data view settings.
Henny Speelman
Apparently there is now an option for dataCoverageDefinition, which makes sure your data is only queried to the necessary partition. However I have a feeling that it is still buggy since I cannot seem to deploy that option (comp: 1603) in SSMS…
Jon Jon
I was interested in Scenario #2, but you say, “…it appears that the DirectQuery query will be run nevertheless if you’re slicing “hot” or “cold” data.” Are you saying Scenario #2 is just not possible?
Nikola
Hi Jonathan,
No, it’s possible, but the Direct Query “part” will be included, even though you are not accessing the most recent partition. Hope this helps.
Carlos Monte
Hi Nikola
Thanks for your article. I’m looking to implement option 2 that you mention and I think it will be a little easier with your article. One question, does the bug you mention in option 2 still occur? Thanks in advance.
Thanks for the article, I need to implement case 2 and I think it will be easier
Nikola
Hi Carlos,
If you’re referring to the fact that the DirectQuery will be executed regardless if the query retrieves the data from hot or cold partition, it’s not a bug, that’s how it works by design:(…To be honest, I haven’t tested recently if this was changed, but I’d be surprised if it was.
Hope this helps.
Carlos Monte
Thanks Nikola for your answer.Regards