

This blog post is part of the “Data Modeling” series, created together with my friend and well-known Power BI expert – Tom Martens
Table of contents
- PRELUDE TO DATA MODELING WITH POWER BI
- THE POWER BI DATA MODEL
- Tables, columns and some things related
- Concept of extended tables
- Calculated columns and measures
- The danger of the one-table solution
- RELATIONSHIPS
- The benefits of strong relationships
- Circular dependencies
- Role-playing dimensions
- Bi-directional relationships
- PARENT-CHILD HIERARCHIES
- AGGREGATIONS
- OUT-OF-THE-BOX THINKING
- Disconnected tables
- A different approach to the event-in-progress problem
If you carefully follow our “Data Modeling” series, you may recall that I’ve used a theatre to illustrate the concept of role-playing dimensions. In this article, however, there will be no actors and no theatre…But, models with bi-directional relationships, or bi-directional filters if you prefer, can quickly turn into a tragedy!
Bi-directional relationships in a nutshell
Before we dive deeper to explain why bi-directional relationships can come back to ruin your data model, let’s first briefly explain what are bi-directional relationships. If you prepared your Star-schema model properly, once you establish the relationship between two tables in the model, the relationship cardinality should be 1:M (besides this cardinality type, there are also 1:1 and M:M types, but that will be covered in one of the next articles).
Let’s quickly understand what this 1 and M mean…In the well-designed Star schema model, dimension tables will be on the “1” side of the relationship – simply said, there is only one certain product in the system, one certain customer, one certain date, and so on…On the other side is “M“, which means MANY. One certain product can be bought multiple times, one certain customer can make multiple transactions, and there can be as many as millions of transactions on one certain date.
I’ll use a very basic data model to show how this 1:M story looks in reality:
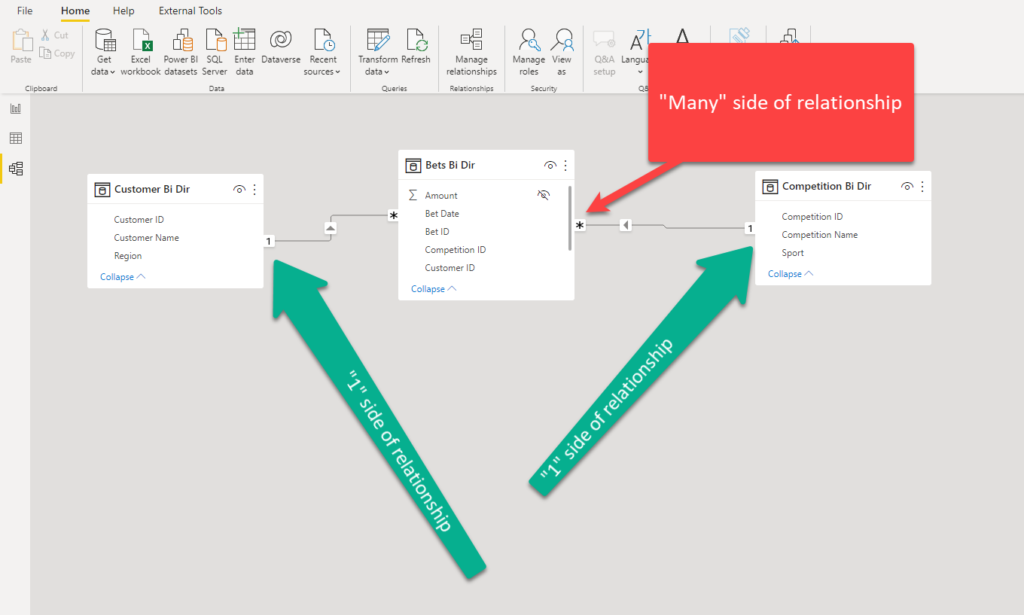
In the illustration above, I have a fact table in the middle (Bets), and two dimension tables (Customer and Competition). There is only one certain customer in the Customer table and only one certain competition in the Competition table, but one customer may place multiple bets, same as there can be many bets on one single competition.
This “relationship cardinality” story would have been finished here if you’re coming from the traditional relational data modeling world, right? In Power BI, though, there is more to it (who said expanded tables😉)…
If you take a more thorough look at this illustration, you may notice a small arrow on the line connecting two tables. And, it’s not just that the arrow itself is important – the more important thing is the arrow direction! The arrow itself means that filtering is happening between the tables, while the arrow direction shows in which way the filter is being propagated!
This is extremely important and in our example would mean – if I filter the Customer table, and choose, let’s say, a customer with ID 1, the filter will be applied on the Bets table, and I’ll see only those bets placed by a customer with ID 1. But, not the other way round, as the filter propagates from the “1” side of the relationship to the “M” side.
This is the default and, I dare to say, desired behavior because the Power BI engine is designed for moving a filter from “1” to “M” in the most optimal way. This is so-called UNIDIRECTIONAL filtering:
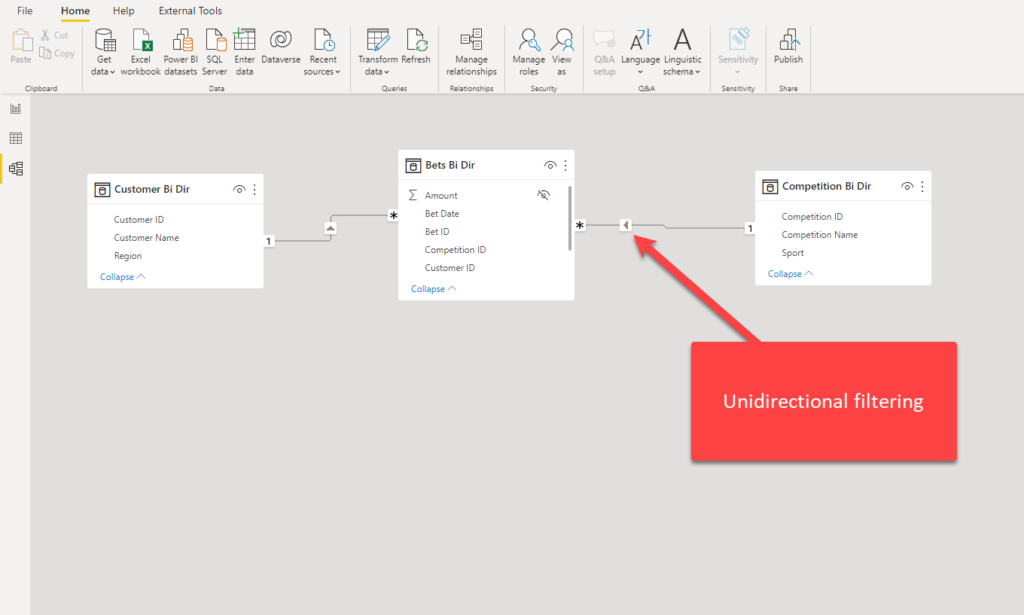
However, you may want to change this default behavior and enable filter propagation in both directions. It’s fairly simple to do this – just go to relationship properties, and select Both under the Cross filter direction drop-down list:
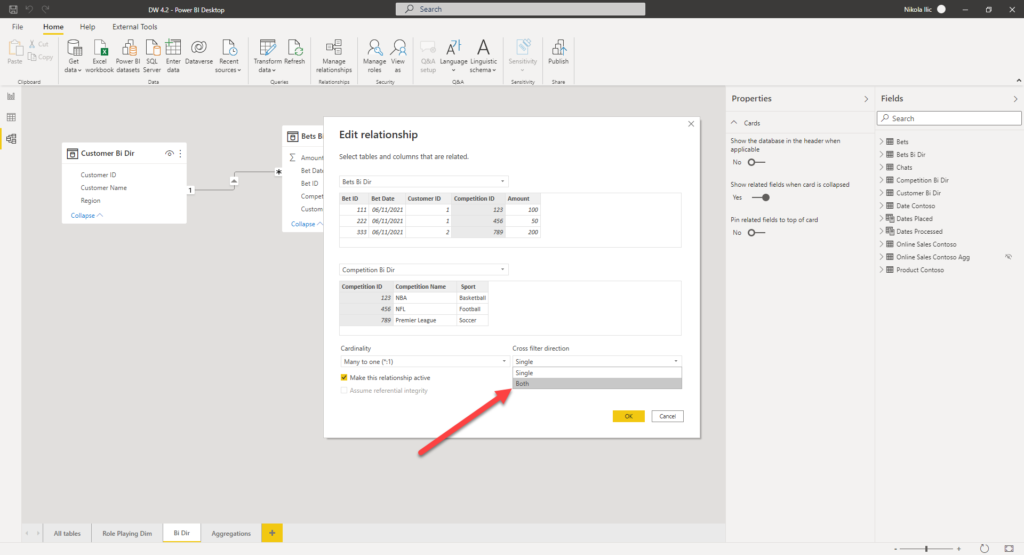
Once you choose this option, you’ve changed your relationship from unidirectional to BI-DIRECTIONAL! And, here is where the party starts…Just to be clear, there is nothing inherently wrong with bi-directional filters! But, like any other non-default behavior, this one also requires careful evaluation and a skilled data modeler.
If bi-directional relationships are not bad “per-se”, why should I care?!
That’s a fair question!
While it is true that bi-directional relationships are not “evil” per-se, it’s also very true that they can take you in direction of not only unpredictable results in your report, but also kill the report performance in certain scenarios. While performance consideration is out of the scope of this article, let me quickly show you how enabling bi-directional filtering may produce some strange and unexpected figures in the report.
Let’s say that I also want to analyze data about customers’ deposits, not just bets. So, I’ll import a very basic table that contains data about deposits. As you may see, there is no relationship between Competition and Deposits, as a customer’s deposit is not related to any specific competition:

And, in a simple report like this:
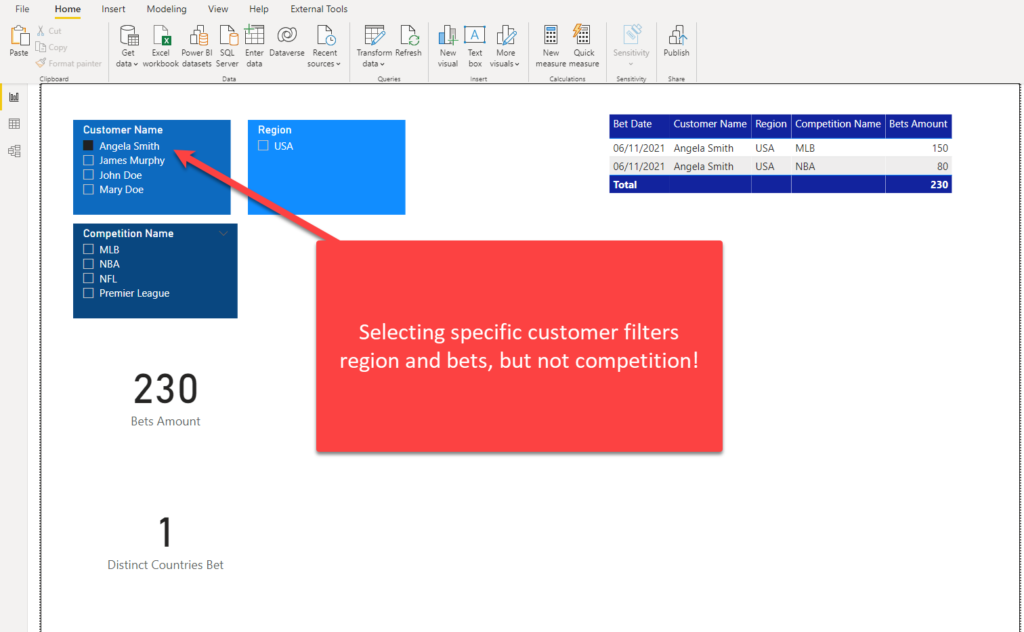
If I select Angela Smith, who is located in the USA, everything but competition is filtered. That’s because the filter propagates from Customer to Bets, but not further from Bets to Competition.
Now, let’s imagine that the business request is to sync slicers and display only those competitions where Angela really placed her bets. In our example, the Competition Name slicer should show only MLB and NBA values. How do we achieve this? Yes, enabling bi-directional filtering is the fastest and simplest way! Let me show you:
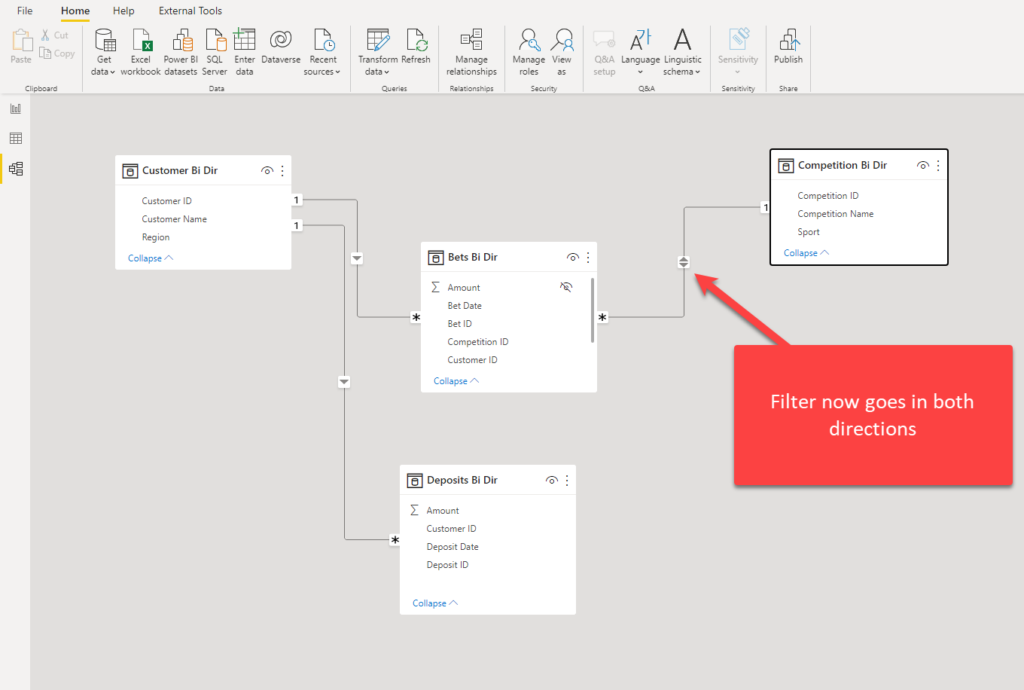
Our arrow now looks different and it shows that the filter will propagate in both directions – simply said, filter from Customer table will affect Bets, and from there, Bets will filter Competition table. Let’s go back to our report and check how it looks now:
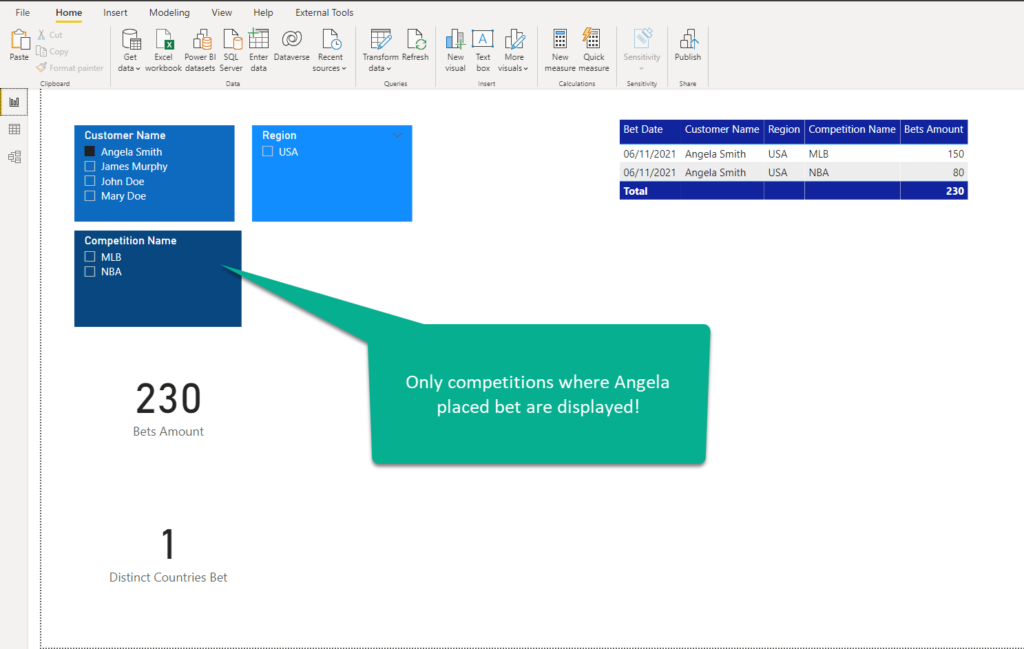
Yes! We fulfilled the business request, everyone’s happy, right? Well, in this case, it didn’t hurt, even though there is a much more convenient way to achieve the same outcome without “playing with fire”. Before I show you this solution, let’s imagine that our happy business users now ask us to analyze the data over time. Fair enough, who has ever seen a Star-schema without a date dimension:)!
So, let’s create a simple Date dimension and establish relationships between this table and our two fact tables (Bets and Deposits).
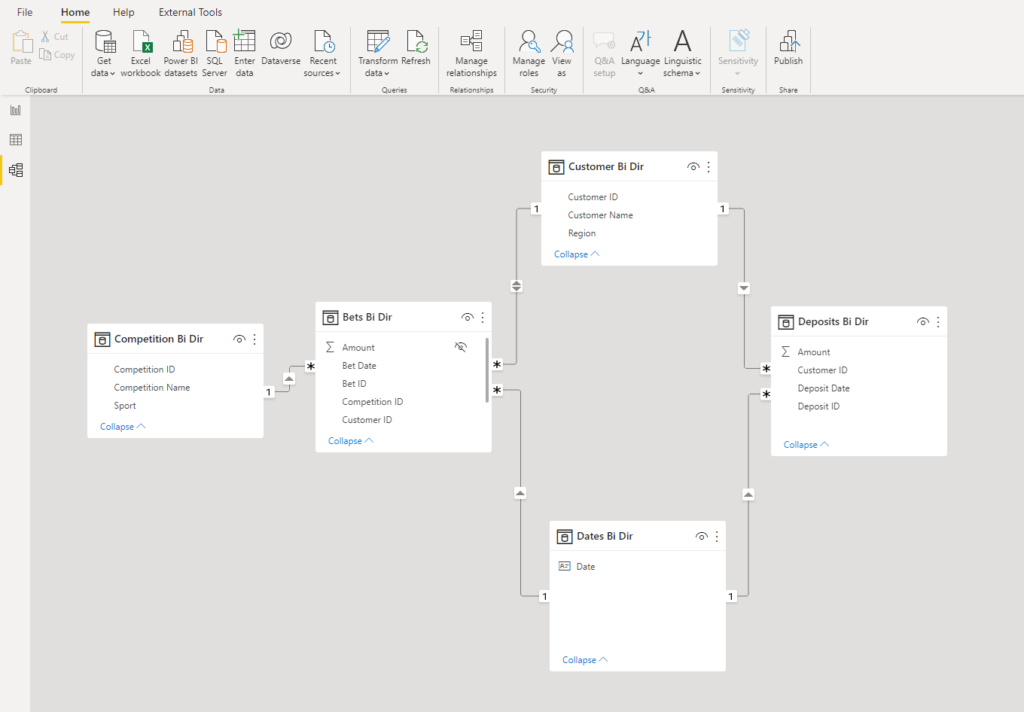
Everything looks fine, except one “small” problem – this data model is ambiguous! I will not go into details explaining what is ambiguity in the data model, as Marco and Alberto from SQLBI have a perfect article explaining this “feature”
If you don’t want to read the full article, I get you covered: ambiguity means that the engine can potentially use multiple different paths to propagate the filter between the tables. This non-deterministic way of handling filter propagation may lead to unpredictable results in the report.
In our case, by filtering the Date table, we can “reach” the Deposits table following two different paths:
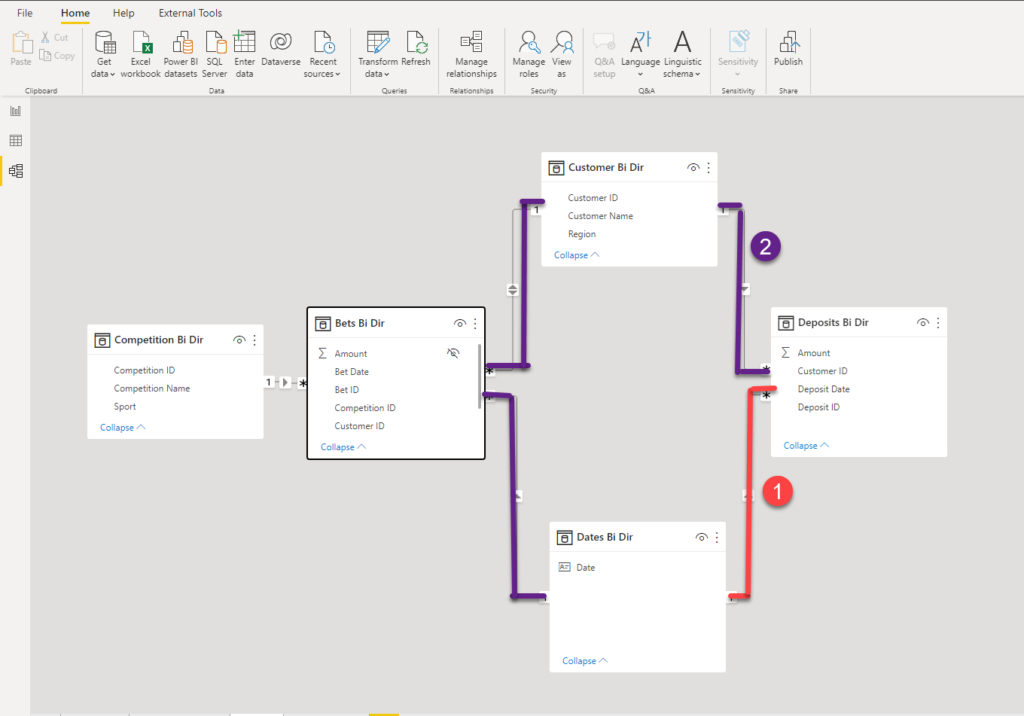
Please keep in mind that this is a fairly simple data model. You can just imagine the possible implications in the more complex scenarios.
Why are bi-directional relationships present in so many data models?
Yes, I hear you, I hear you…Nikola, we can’t avoid using bi-directional relationships in certain scenarios. I can accept that, but I don’t take it for granted!
Ok, for 1:1 and M:M relationships, you HAVE to use bi-directional filters. However, the primary question to ask yourself is: why do I have these kinds of relationships in my data model in the first place?! Especially 1:1!!!
But, going back to our previous example, when I promised to provide you with a more convenient solution to the business request we had. First of all, I’ll revert my bi-directional filtering to a default unidirectional:
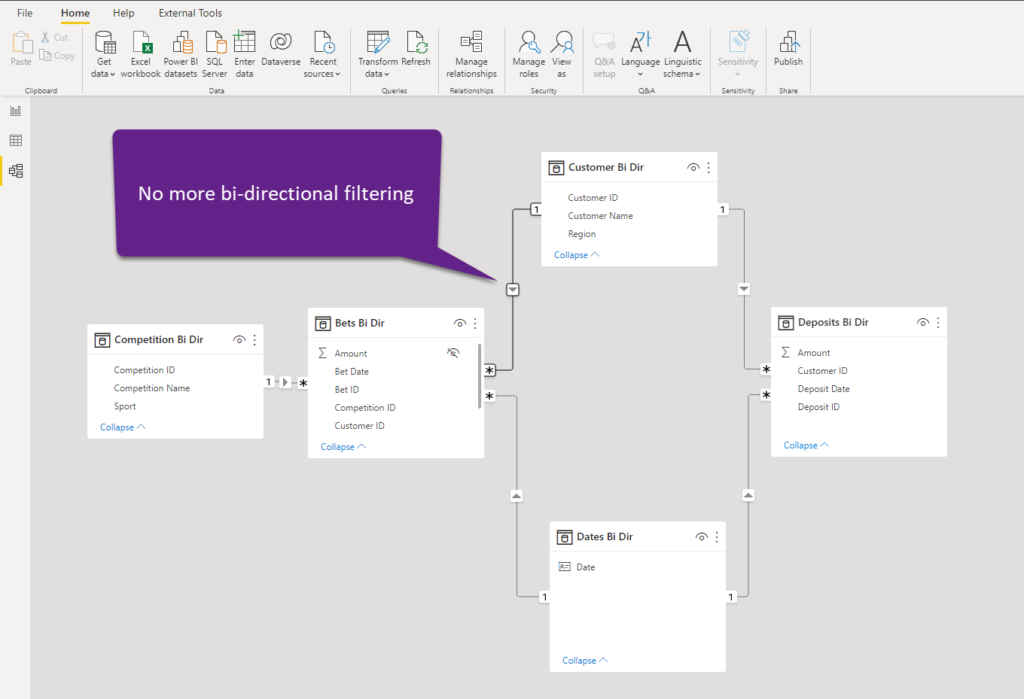
I’ll simply go back to my report, select Competition Name slicer, and set the filter on this visual for the Bets Amount to be non-blank:
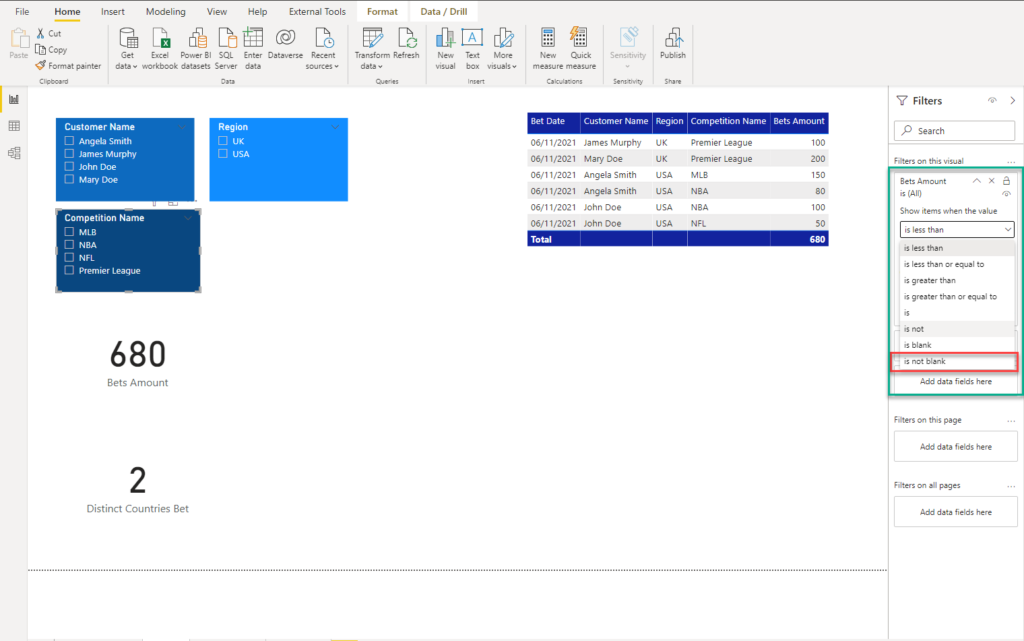
Once I apply this filter, the outcome should be exactly the same as in the previous case when we enabled bi-directional filtering:
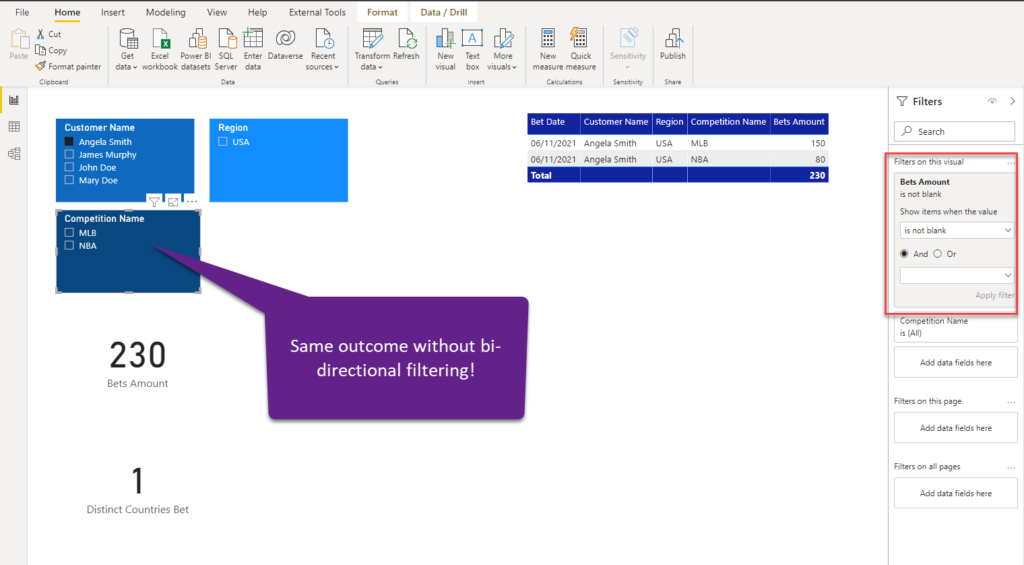
Nice, thank you Nikola, but what should I do if I need to perform the dimension-to-dimension analysis? For example, I want to see how many distinct countries bet on MLB…This is an interesting scenario, as in this case you’d use a fact table as a bridge table between dimension tables, and enable bi-directional filtering, like in the “classic” M:M relationship…
Again, please don’t do that! I hear you: your users need to see this number in their report. And, you want to impress your users, right? I have a solution for you: create a proper data model! I mean, you should follow this recommendation nevertheless of this specific challenge. But, going back to this specific requirement, what you CAN (and SHOULD) do, is to leverage the power of DAX and use CROSSFILTER function instead of enabling a bi-directional relationship.
By using CROSSFILTER, you can enable filter propagation in both directions only and only for this single calculation, instead of keeping it active permanently. CROSSFILTER is a powerful function, as it modifies filter direction, or even disables the relationship completely! But, it happens only during the evaluation of the specific expression.
The basic measure for calculating the number of distinct countries with bets placed would be something like:
Distinct Countries Bet No CROSSFILTER = DISTINCTCOUNT('Customer Bi Dir'[Region])
As Competition doesn’t filter Customer table (and consequentially, can’t filter countries), whatever you select in the Competition Name slicer, this measure will return the same result:
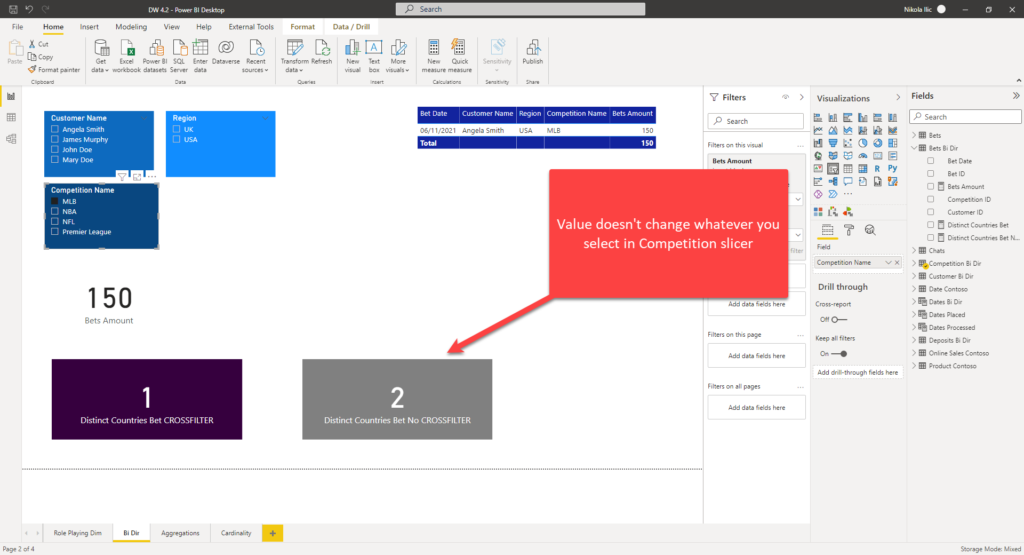
However, if I rewrite my measure, using CROSSFILTER function to enable filtering in both directions, but ONLY for this specific calculation, I’ll get the correct result, while keeping my data model safe from potential caveats produced by bi-directional relationships:
Distinct Countries Bet =
CALCULATE(
DISTINCTCOUNT('Customer Bi Dir'[Region]),
CROSSFILTER(
'Customer Bi Dir'[Customer ID],
'Bets Bi Dir'[Customer ID],
BOTH
)
)
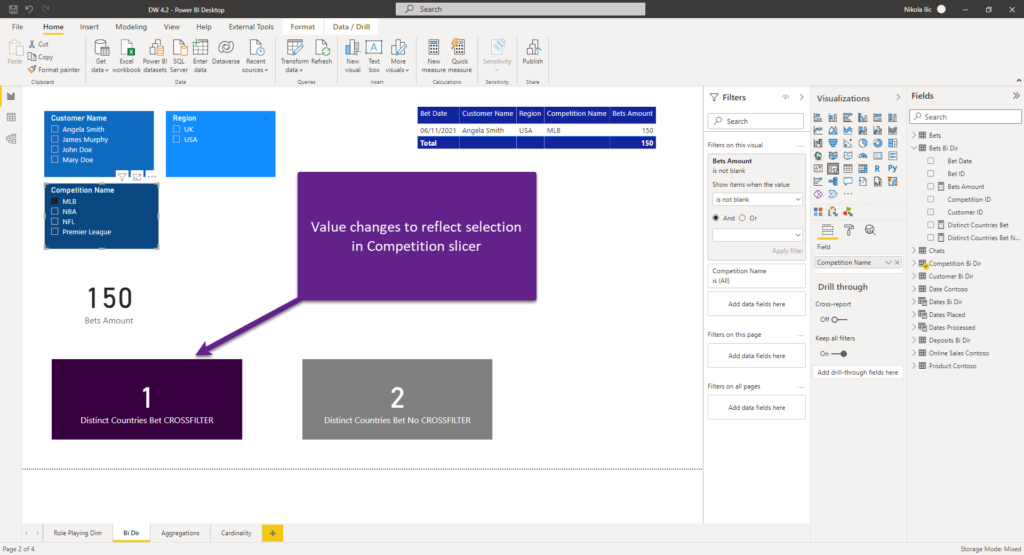
As you may see, we managed to satisfy the business request without introducing bi-directional relationships in the data model!
Conclusion
I somehow get the feeling that the general opinion about bi-directional relationships is that they are bad and “evil”. Maybe it sounds too harsh, but like any powerful feature, this one also comes with a risk of improper usage. While bi-directional relationships are not nasty per-se, the consequences that they may produce are something that you should be aware of.
To conclude, try to minimize the usage of bi-directional relationships in data modeling, unless you REALLY know what you’re doing!
Thanks for reading!
Last Updated on November 15, 2025 by Nikola



Kirill Perian
Thanks for posting this, Nikola! The requirement of slicers reacting to other slicers is not new and the common go-to solution for new Power BI developers is to accomplish it with bi-directional relationships. Somehow, the slicer filtering by non-blank measure results isn’t yet widely popular, so thank you for bringing it to everyone’s attention.
Nikola
Thanks Kirill! You’re absolutely right, I saw this multiple times, and it was almost always bi-directional relationship included
Tom
A lot of drama in this article. lol
Don’t get me wrong, thanks to the article, and made me learn when to use the new DAX: ‘CROSSFILTER’.
Thank you, Nikola.