

This article is the part of the series related to mastering DP-500 certification exam: Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI
Table of contents
When working with Power BI, one of the first decisions you need to make is the following:
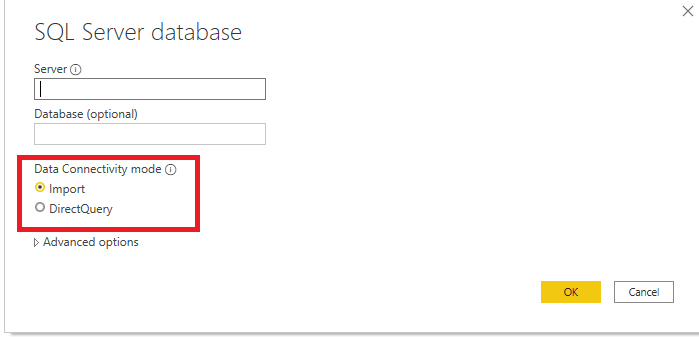
As soon as you plan to get some data to work with, Power BI asks you to choose Data Connectivity mode. If you’ve read this article, or even better, started with this one, you should probably be familiar with the Import option, and how the Tabular model works in the background of Power BI to support your queries and generate lightning fast reports.
In this article, I want to go more in-depth on the DirectQuery option, as I have a feeling that this option is still underused (for good or for bad, we’ll try to examine in this article).
WHAT is DirectQuery?
As its name suggests, DirectQuery is a method of retrieving data, that pulls the data directly from the data source, at the query time! The last part of the sentence holds the key – while Import mode stores the snapshot of your data in-memory – DirectQuery (DQ) doesn’t store any data. For every single request, it goes straight to the data source (which is in 99% of cases SQL database), and pulls the data from there.
So, data resides within its original source before, during, and after the query execution!
When interacting with the report, your users generate a query (or set of queries in most cases), that needs to be executed in order to satisfy the requests. As you may recall from this article, the Tabular model consists of Formula Engine (FE) and Storage Engine (SE). Formula Engine accepts the request, creates a query plan, and then, depending on your choice between Import vs DirectQuery mode, generates the query to target respective data source:
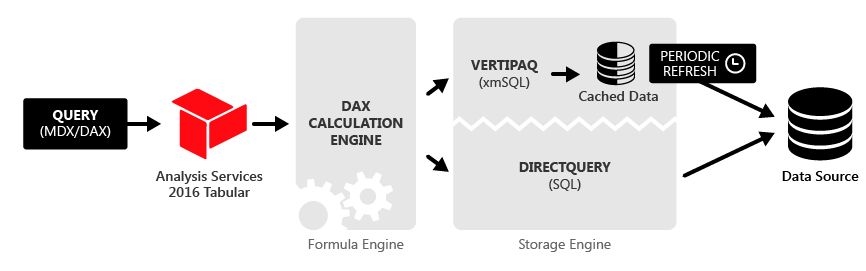
As you may notice, when you choose the DQ option, Formula Engine will “translate” DAX to a SQL and send the query directly to the data source.
Once you’ve chosen the DirectQuery option, Power BI will not import data from the underlying tables. It will hold only their metadata.
The great news is: you can use Composite models in Power BI. In simple words, this means that you can combine DQ and Import mode within your data model, setting the preferred option for every single table!
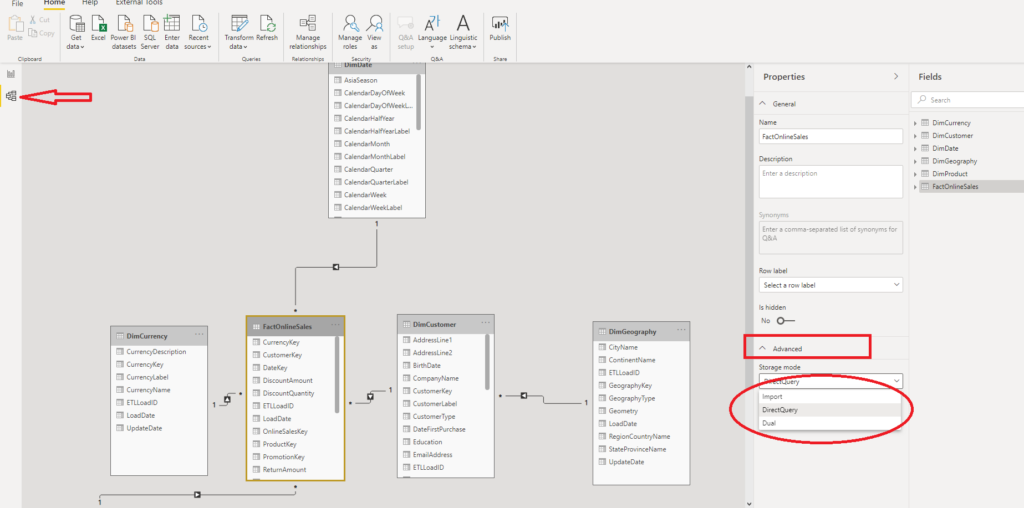
As you may see, once I’ve created my Power BI data model using the DQ option, when I open my data in the Model View, under Advanced, I can choose which Storage mode to apply for the selected table. Important notice: you can switch from Direct Query to Import mode, but not vice versa!
Dual mode is like a hybrid – a combination of Import mode and DirectQuery. Data from the table is being loaded into memory, but at the query time, it can be also retrieved directly from the source.
WHEN to use DirectQuery?
Honestly, this is a “Million $” question:)…And, as in most cases, the only correct answer is: “It depends”. But, let’s check on what it depends!
- Do you need “real-time” or near real-time data? If your answer to any of these questions were: YES, you should consider using DirectQuery mode. WHY? Because, Import mode keeps the snapshot of your data, and this needs to be refreshed periodically in order to get the latest data. In case you need, for example, data with a maximum 1-minute latency, using Import mode is practically impossible
- Is your data model size big? And when I say big, I mean BIG! So big, that you can’t accommodate it within a maximum .pbix file size (1 GB for Pro license, 10 GB for Premium/Embedded). Let’s imagine that your users need to analyze data from a billion-row table, on a low level of granularity. You can’t simply import billion-row table data into the Tabular model – on the opposite, data stays in the source, and your aggregations/calculations are being performed there before the refined results are being returned to your report
WHY (not) use DirectQuery?
If your workload requires one of the scenarios mentioned above (“real-time” analytics, and/or too large data model), DirectQuery would be an obvious choice.
However, let’s examine some general pros and cons of using DirectQuery in more frequent cases:

The most important consideration when using DirectQuery is that overall user experience depends almost exclusively on the performance of the underlying data source. That means, if your source database is not optimized for the analytic workload (missing indexes; inappropriate indexes; inadequate data modeling in place, so that query needs to target multiple tables), your report performance will suck!
Additionally, the number of users that interact with the report in parallel will also have an impact. Imagine the scenario where 10 people browsing the report page with 20 visuals on it – that will generate 200 queries to an underlying data source at the same time! Keep in mind that each visual will generate (at least) one query to a data source!
And, if there is a realistic chance that you can improve those two by applying different techniques, you should also keep in mind that there are also some things that you can’t control, such as:
- Performance of the source server – you can’t do anything if, for example, tens of different workloads are being run during the visuals refresh on that same server
- Network latency
Techniques for optimizing data source
As I mentioned above, there are different techniques to improve the performance of the data source (assuming that you have access to an underlying data source and can apply structural changes).

- Add proper indexes – to support your most exhaustive queries. You should consider creating Columnstore indexes for large analytical workloads, but well-designed B-Tree indexes should also improve the performance
- Data Integrity in place – ensure that your dimension tables contain proper keys and that those keys relate to a fact table (every fact table key value has a corresponding value in the dimension table)
- Create persistent objects in the source database – that means, try to materialize all aggregations, transformations, and calculations, either in a special table or in an Indexed View. That way, Power BI can retrieve all data from a single place, instead of performing complex operations (like joins between multiple tables) every time query is being executed
- Use Date table from the source system – every (proper) data model should rely on a separate Date dimension. Make sure that you have your Date table established in the database
Power BI & DirectQuery Best Practices
Once you are in Power BI, you should stick with the following best practices when using DirectQuery mode:
- Avoid complex Power Query transformations – each time you apply a transformation to your data model, Power Query will generate a query and fire it to a source database. Let’s say that I want to replace all my ProductKey values 782 with 783. If I do that in Power Query Editor, the following things happen:
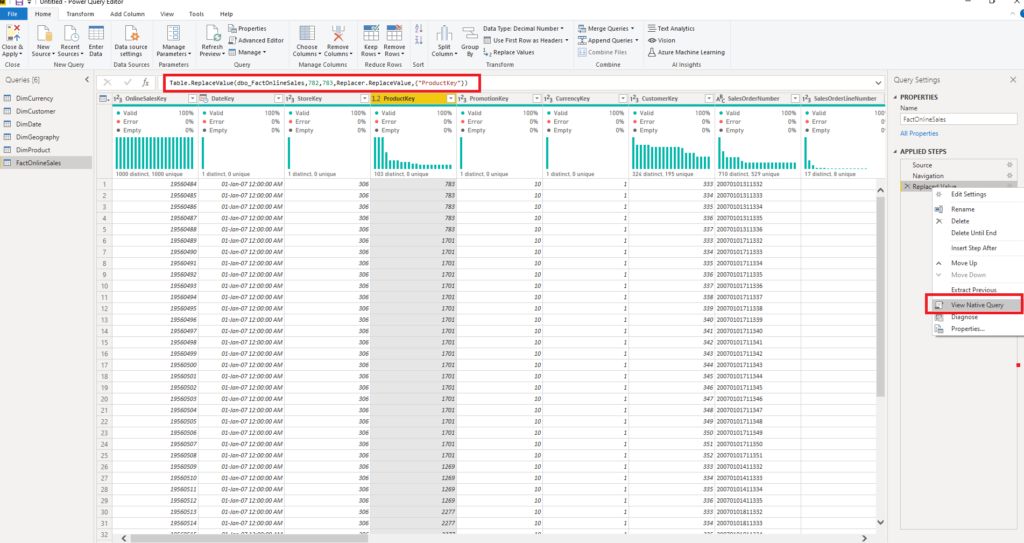
You can see the M statement which Power Query generated to satisfy our request, but if you right-click on that step and select the View Native Query option, you can also see the SQL query that will be sent to a SQL Server database:
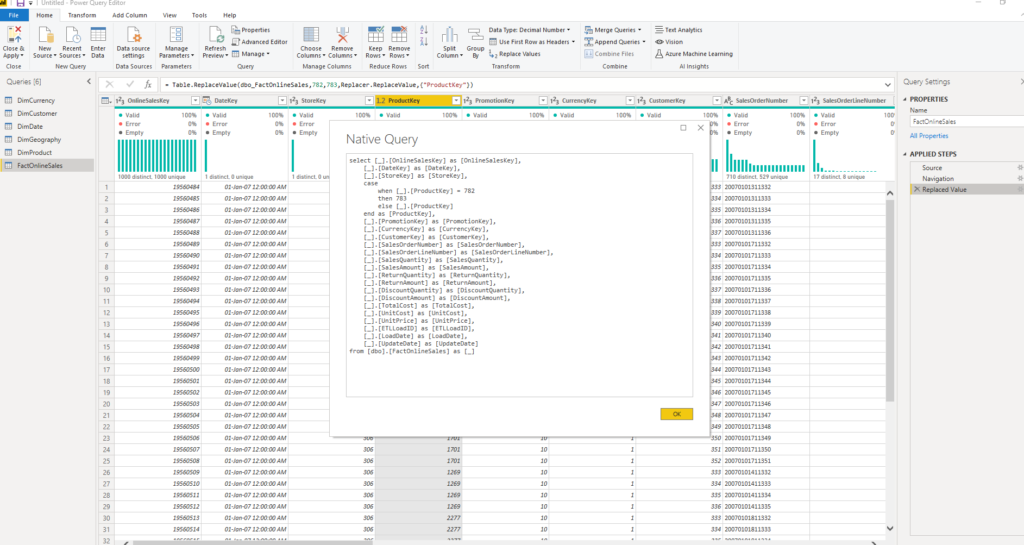
Now, for these simple transformations, Formula Engine is smart enough to do everything in one iteration. But, if you perform some more complex stuff, turn on SQL Server Profiler or DAX Studio, and have fun watching how many requests had been sent to your source database…
- If you need to use Calculated columns, try to push their creation on the source database and keep them persistent
- Avoid complex DAX measures – as your DAX statement needs to be “translated” to a SQL, keep in mind that this process can produce expensive SQL queries. Again, whenever possible, perform all your calculations on the source side
- Avoid relationships on GUID columns (unique identifier) – Power BI doesn’t support this data type and needs to apply some data conversion during the query execution, which affects the performance. The solution is to convert this data type within the source database, prior to Power BI generates its own queries
- Limit parallelism whenever possible – you can define the maximum number of connections that DQ can open at the same time:
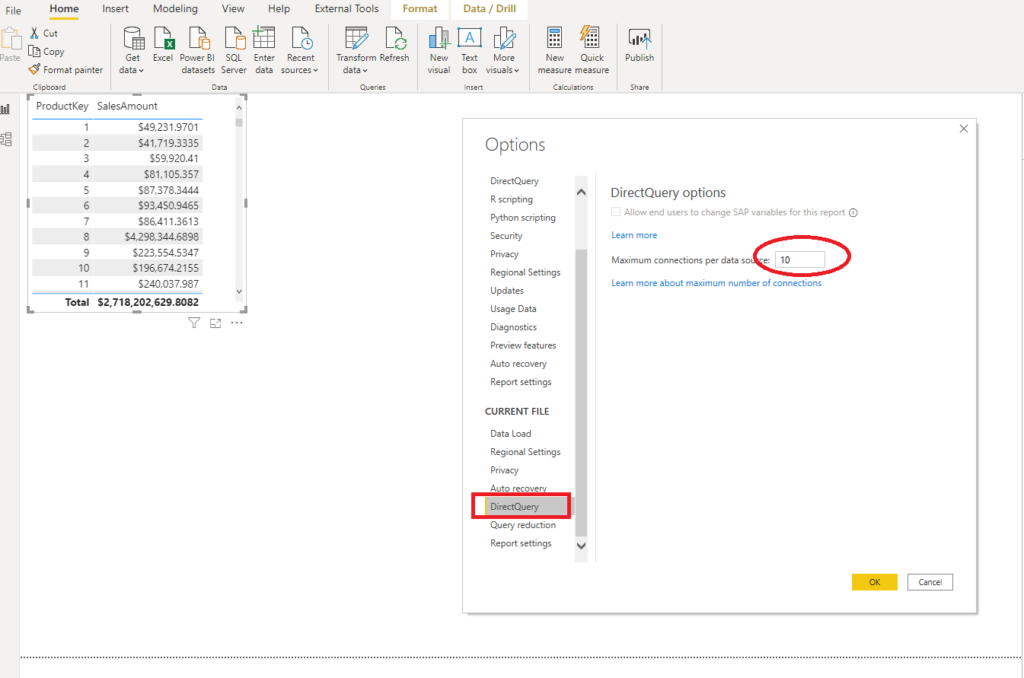
If you go to Options, under the Current File, you can specify a value for the Maximum connections per data source (by default is 10).
- Once in the Power BI report itself, there are few additional optimization options:

Most of these options are self-explanatory. Basically, you can restrict slicers and filters, because by default when you change one slicer value, all the slicers will generate the query to a data source (even those which haven’t changed)!
Therefore, you can add the “Apply” button, so that the user can specifically choose which portion of data needs to be refreshed. Of course, that will impact your report design, since you need to provide additional space for those buttons:
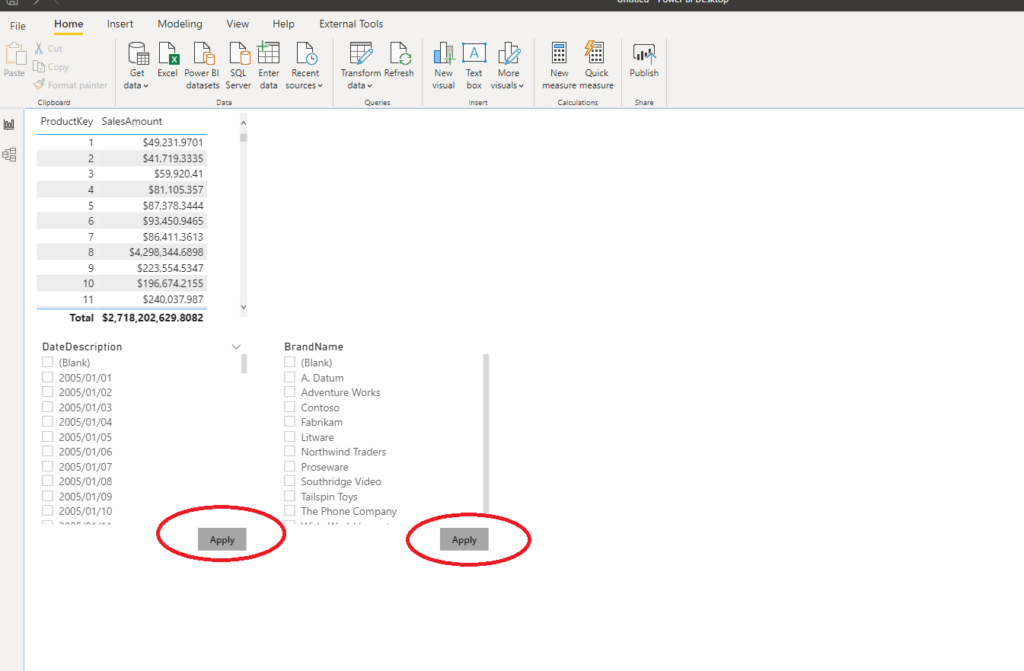
You should also carefully think about the number of visuals on the report page – the more visuals, the longer time needed for data retrieval.
Finally, you should turn off cross-highlighting and cross-filtering between the visuals, as that will reduce the number of queries generated. You can turn off these features either on the whole report level (in Options -> Query reduction -> check the option: Disabling cross highlighting/filtering by default), or for the specific visuals only.
You should also check the Assume Referential Integrity option, as described in this article. That will enable the usage of inner joins instead of outer joins, which can improve the overall query performance. Of course, as a prerequisite, you should have referential integrity in place within your source database.
One more recommendation is of key importance – talk to your users, try to explain them the difference between Import mode and DirectQuery, what benefits can they get by using each of these two, but also which downsides to expect (especially when choosing DQ mode).
Conclusion
As you may conclude on your own: Choosing the right tool for the job is the best possible recommendation, if you are considering using DirectQuery.
Carefully evaluate your potential workloads and try to identify all pros and cons of both Import and DirectQuery approach, before making the final decision.
Thanks for reading!
Last Updated on January 20, 2023 by Nikola


Triparna Ray
Thanks for sharing useful insights on this important topic. With regard to guid if we do not have option to change source structure we have to bring in guid and to improve performance trying to add index column and join based on that. What we found was this caused query folding not to work any further. Any thoughts?
Nikola
Hi Triparna,
As far as I know, there is no proper way to optimize GUID performance once you import it into the Power BI. Query folding will not work in cases when your Power Query transformations can’t be “translated” to a source language (mostly SQL).
How to Capture SQL Queries Generated by Power BI - H4Host.com - Latest Web Hosting News
[…] already written why you should reconsider using DirectQuery, and in which scenarios (maybe) it makes sense to go that […]
Leveraging Hybrid Tables to get real-time data updates
[…] DirectQuery (uses no memory for storage but it showers and limits many reporting features) […]
Wasiu
Good