

I don’t know about you, but when I watch movies and see some breathtaking scenes, I’m always wondering – how did they do THIS?! What kind of tricks they pulled out of their sleeves to make it work like that?
And, I have this feeling when watching Direct Lake in action! For those of you who maybe haven’t heard about the new storage mode for Power BI semantic models, or wondering what Direct Lake and Allen Iverson have in common, I encourage you to start by reading my previous article.
The purpose of this one is to demystify what happens behind the scenes, how this “thing” actually works, and give you a hint about some nuances to keep in mind when working with Direct Lake semantic models.
Direct Lake storage mode overcomes shortcomings of both Import and DirectQuery modes – providing a performance similar to Import mode, without data duplication and data latency – because the data is being retrieved directly from delta tables during the query execution.
Sounds like a dream, right? So, let’s try to examine different concepts that enable this dream comes true
Framing (aka Direct Lake “refresh”)
The most common question I’m hearing these days from clients is – how can we refresh the Direct Lake semantic model? It’s a fair question. Since they have been relying on Import mode for years, and Direct Lake promises an “import mode-like performance”…So, there has to be a similar process in place to keep your data up to date, right?
Well, ja-in…(What the heck is this now, I hear you wondering😀). Germans have a perfect word (one of many, to be honest) to define something that can be both “Yes” and “No” (ja=YES, nein=NO). Chris Webb already wrote a great blog post on the topic, so I won’t repeat things written there (go and read Chris’s blog, this is one of the best resources for learning Power BI). My idea is to illustrate the process happening in the background and emphasize some nuances that might be impacted by your decisions.
But, first things first…
Syncing the data
Once you create a Lakehouse in Microsoft Fabric, you’ll automatically get two additional objects provisioned – SQL Analytics Endpoint for querying the data in the lakehouse (yes, you can write T-SQL to READ the data from the lakehouse), and default semantic model, which contains all the tables from the lakehouse. Now, what happens when a new table arrives in the lakehouse? Well, it depends:)
If you open the Settings window for the SQL Analytics Endpoint, and go to Default Power BI semantic model property, you’ll see the following option:

This setting allows you to define what happens when a new table arrives at a lakehouse. By default, this table WILL NOT be automatically included in the default semantic model. And, that’s the first point relevant for “refreshing” the data in Direct Lake mode.
At this moment, I have 4 delta tables in my lakehouse: DimCustomer, DimDate, DimProduct and FactOnlineSales. Since I disabled auto-sync between the lakehouse and semantic model, there are currently no tables in the default semantic model!
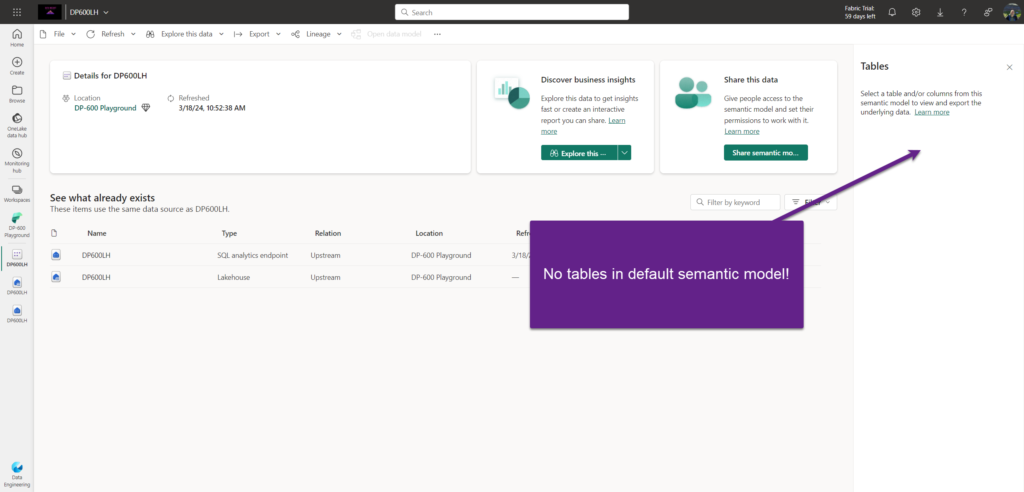
This means I first need to add the data to my default semantic model. Once I open the SQL Analytics Endpoint and choose to create a new report, I’ll be prompted to add the data to the default semantic model:

Ok, let’s examine what happens if a new table arrives in the lakehouse? I’ve added a new table in lakehouse: DimCurrency.
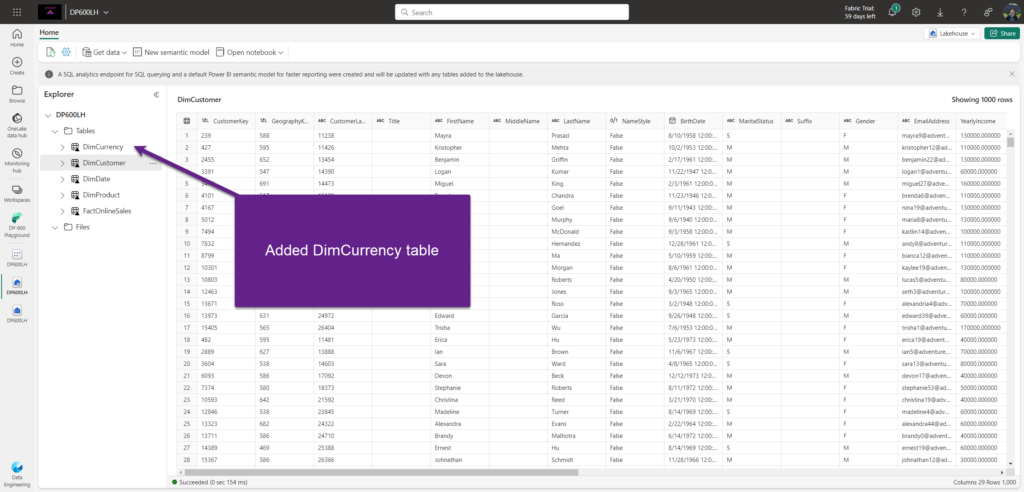
But, when I choose to create a report on top of the default semantic model, there is no DimCurrency table available:

I’ve enabled the auto-sync option and after a few minutes, the DimCurrency table appeared in the default semantic model objects view:

So, this sync option allows you to decide if the new table from the lakehouse will be automatically added to a semantic model or not.
Syncing = Adding new tables to a semantic model
But, what happens with the data itself? Meaning, if the data in the delta table changes, do we need to refresh a semantic model, like we had to do when using Import mode to have the latest data available in our Power BI reports?
It’s the right time to introduce the concept of framing. Before that, let’s quickly examine how our data is stored under the hood. I’ve already written about the Parquet file format in detail, so here it’s just important to keep in mind that our delta table DimCustomer consists of one or more parquet files (in this case two parquet files), whereas delta_log enables versioning – tracking of all the changes that happened to DimCustomer table.
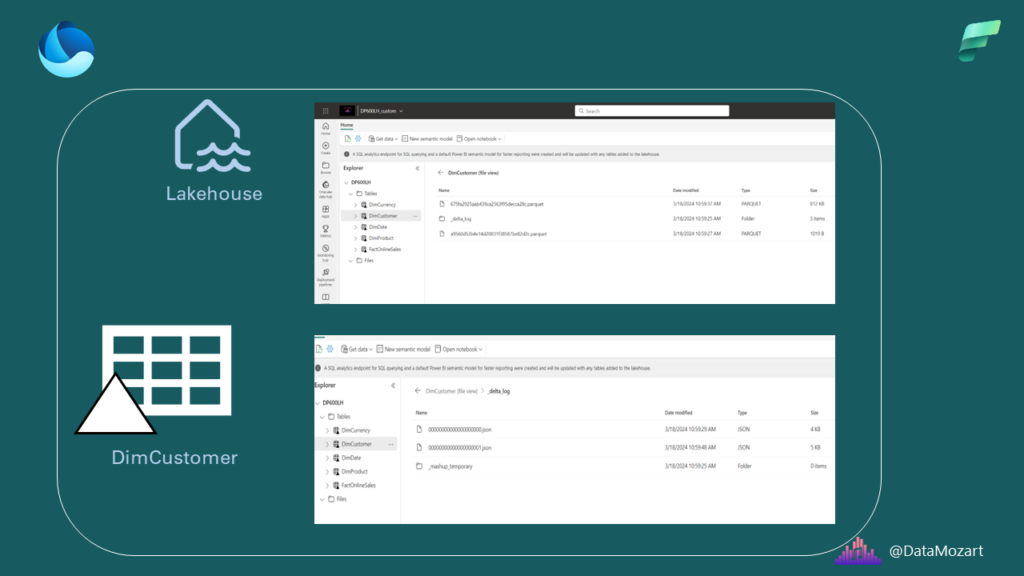
I’ve created a super basic report to examine how framing works. The report shows the name and email address of the customer Aaron Adams:

I’ll now go and change the email address in the data source, from aaron48 to aaron048

Let’s reload the data into Fabric lakehouse and check what happened to the DimCustomer table in the background:
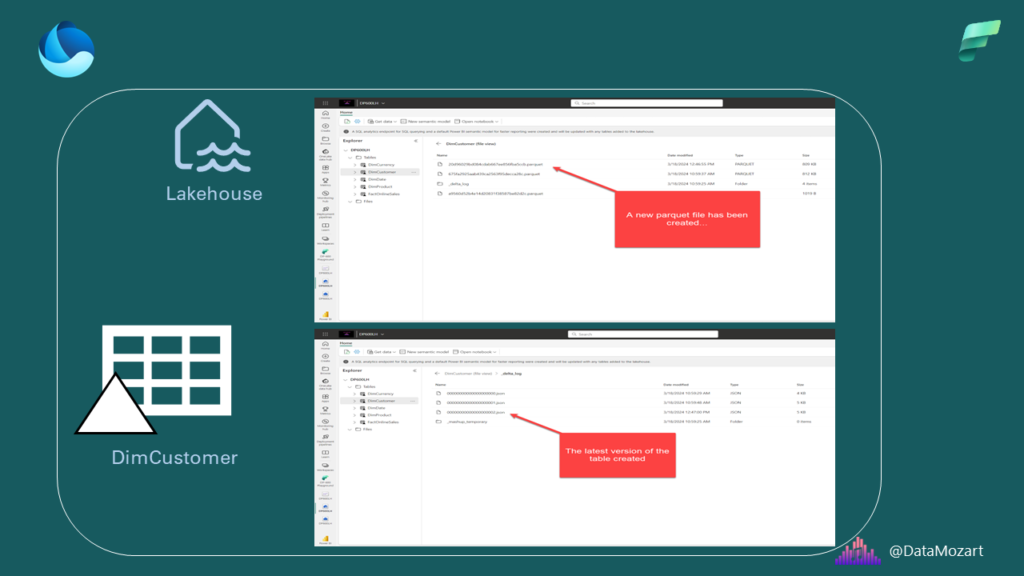
A new parquet file appeared, while at the same time in delta_log, a new version has been created.
Once I go back to my report and hit the Refresh button…

This happened because my default setting for semantic model refresh was configured to enable change detection in the delta table and automatically update the semantic model:
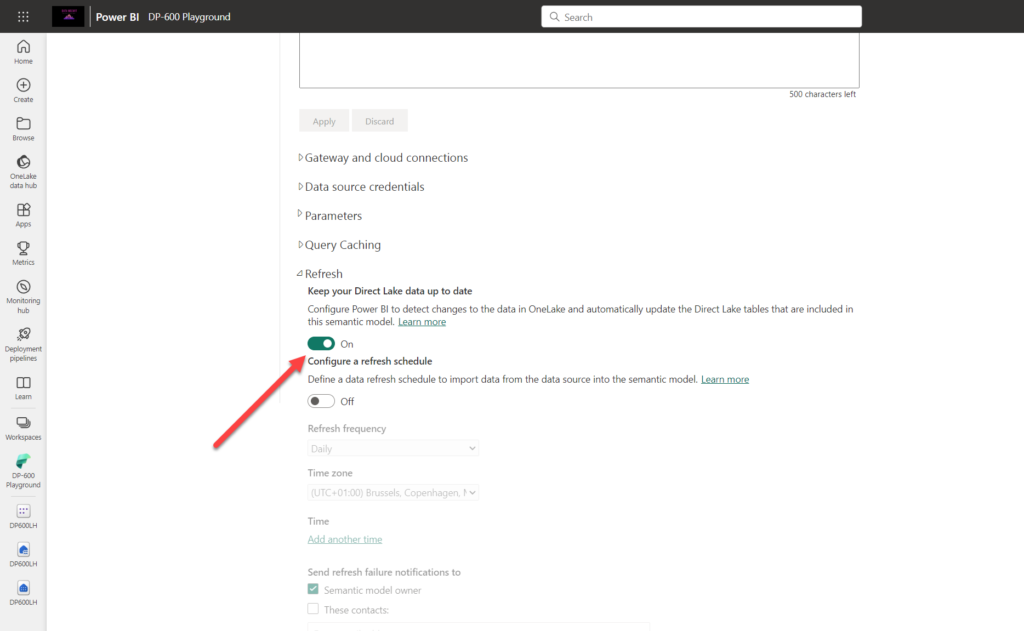
Now, what would happen if I disable this option? Let’s check…I’ll set the email address back to aaron48 and reload the data in the lakehouse. First, there is a new version of the file in delta_log, the same as in the previous case:

And, if I query the lakehouse via the SQL Analytics Endpoint, you’ll see the latest data included (aaron48):

But, if I go to the report and hit Refresh…I still see aaron048!

Since I disabled the automatic propagation of the latest data from the lakehouse (OneLake) to the semantic model, I have only two options available to keep my semantic model (and, consequentially, my report) intact:
- Enable the “Keep your Direct Lake data up to date” option again
- Manually refresh the semantic model. When I say manually, it can be really manually, by clicking on the Refresh now button, or by executing refresh programmatically (i.e. using Fabric notebooks, or REST APIs) as part of the orchestration pipeline
Why would you want to keep this option disabled (like I did in the latest example)? Well, your semantic model usually consists of multiple tables, representing the serving layer for the end user. And, you don’t necessarily want to have data in the report updated in sequence (table by table), but probably after the entire semantic model is refreshed and synced with the source data.
This process of keeping the semantic model in sync with the latest version of the delta table is called framing.

In the illustration above, you see files currently “framed” in the context of the semantic model. Once the new file enters the lakehouse (OneLake), here is what should happen in order to have the latest file included in the semantic model:

The semantic model must be “reframed” to include the latest data. This process has multiple implications that you should be aware of. First, and most important, whenever framing occurs, all the data currently stored in the memory (we are talking about cache memory) is dumped out from the cache. This is of paramount importance for the next concept that we are going to discuss – paging.
Next, there is no “real” data refresh happening with framing…
Unlike with Import mode, where kicking off the refresh process will literally put the snapshot of the physical data in the semantic model, framing refreshes metadata only! So, data stays in the delta table in OneLake (no data is loaded in the Direct Lake semantic model), we are only telling our semantic model: hey, there is a new file down there, go and take it from here once you need the data for the report… This is one of the key differences between the Direct Lake and Import mode
Since the Direct Lake “refresh” is just a metadata refresh, it’s usually a low-intensive operation that shouldn’t consume too much time and resources. Even if you have a billion-row table, don’t forget – you are not refreshing billion rows in your semantic model – you refresh only the information about that gigantic table…
Paging – Your on-demand cache magic
Fine, now that you know how to sync data from a lakehouse with your semantic model (syncing), and how to include the latest “data about data” in the semantic model (framing), it’s time to understand what really happens behind the scenes once you put your semantic model into action!
This is the selling point of Direct Lake, right? Performance of the Import mode, but without copying the data. So, let’s examine the concept of Paging…
In plain English: paging represents a process of loading parts of the delta table (when I say parts, I mean certain columns) or the entire delta table into cache memory!
Let me stop here and put the sentence above in the context of Import mode:
Update 2024-04-10: Thanks to Kurt Buhler who brought to my attention that if you enable Large Semantic Model Storage format in Power BI Service, on-demand paging is also available for Import mode models
- Loading data into memory (cache) is something that ensures a blazing-fast performance of the Import mode
- In Import mode, in case you haven’t enabled a Large Format Semantic Model feature, the entire semantic model is stored in memory (it must fit memory limits), whereas in Direct Lake mode, only columns needed by the queries are stored in memory!
To put it simply: bullet point one means that once Direct Lake columns are loaded into memory, this is absolutely the same as Import mode (I promise I’ll show you soon)! Bullet point two means that the cache memory footprint of the Direct Lake semantic model could be significantly lower, or in the worst case the same, than that of the Import mode (again, I promise to show you soon). Obviously, this lower memory footprint comes with a price, and that is the waiting time for the first load of the visual containing data that needs to be “transcoded” on-demand from OneLake to the semantic model.
Before we dive into examples, you might be wondering: how does this thing work? How can it be that data stored in the delta table can be read by the Power BI engine the same way as it was stored in Import mode?
The answer is: there is a process called transcoding, which happens on the fly when a Power BI query requests the data. This is not too expensive process, since the data in Parquet files are stored very similar to the way VertiPaq (a columnar database behind Power BI and AAS) stores the data. On top of it, if your data is written to delta tables using the v-ordering algorithm (Microsoft’s proprietary algorithm for reshuffling and sorting the data to achieve better read performance), transcoding makes the data from delta tables look exactly the same as if it were stored in the proprietary format of AAS.
Let me now show you how paging works in reality. For this example, I’ll be using a healthcare dataset provided by Greg Beaumont (go and visit Greg’s GitHub, it’s full of amazing resources). The fact table contains ca. 220 million rows and my semantic model is a well-designed star schema.
Import vs Direct Lake
The idea is the following: I have two identical semantic models (same data, same tables, same relationships, etc.) – one is Import mode, while the other is Direct Lake.

I’ll now open a Power BI Desktop and connect to each of these semantic models to create an identical report on top of them. I need the Performance Analyzer tool in the Power BI Desktop, to capture the queries and analyze them later in DAX Studio.
I’ve created a very basic report page, with only one table visual, which shows the total number of records per year. In both reports, I’m starting from the blank page, as I want to make sure that nothing is retrieved from the cache, so let’s compare the first run of each visual:

As you may notice, the Import mode performs slightly better during the first run, probably because of the transcoding cost overhead for “paging” the data for the first time in Direct Lake mode. I’ll now create a year slicer in both reports, switch between different years, and compare performance again:

There is basically no difference in performance! This means, once the column from the Direct Lake semantic model is paged into memory, it behaves exactly the same as in the Import mode.
However, what happens if we include the additional column in the scope? Let’s test the performance of both reports once I put the Total Drug Cost measure in the table visual:
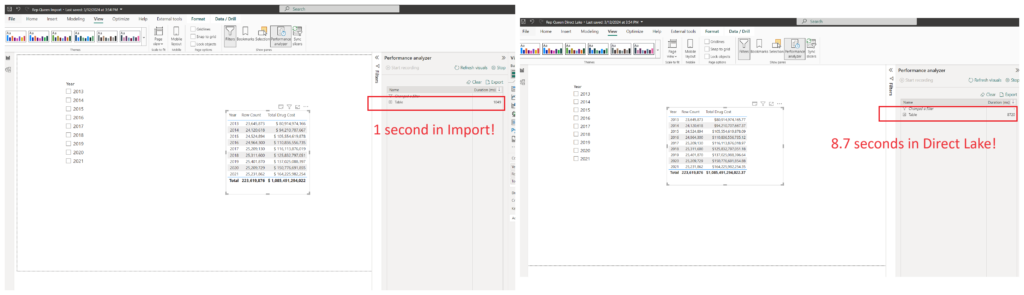
And, this is a scenario where Import easily outperforms Direct Lake! Don’t forget, in Import mode, the entire semantic model was loaded into memory, whereas in Direct Lake, only columns needed by the query were loaded in memory. In this example, since Total Drug Cost wasn’t part of the original query, it wasn’t loaded into memory. Once the user included it in the report, Power BI had to spend some time to transcode this data on the fly from OneLake to VertiPaq and page it in the memory.
Memory footprint
Ok, we also mentioned that the memory footprint of the Import vs Direct Lake semantic models may vary significantly. Let me quickly show you what I’m talking about. I’ll first check the Import mode semantic model details, using VertiPaq Analyzer in DAX Studio:
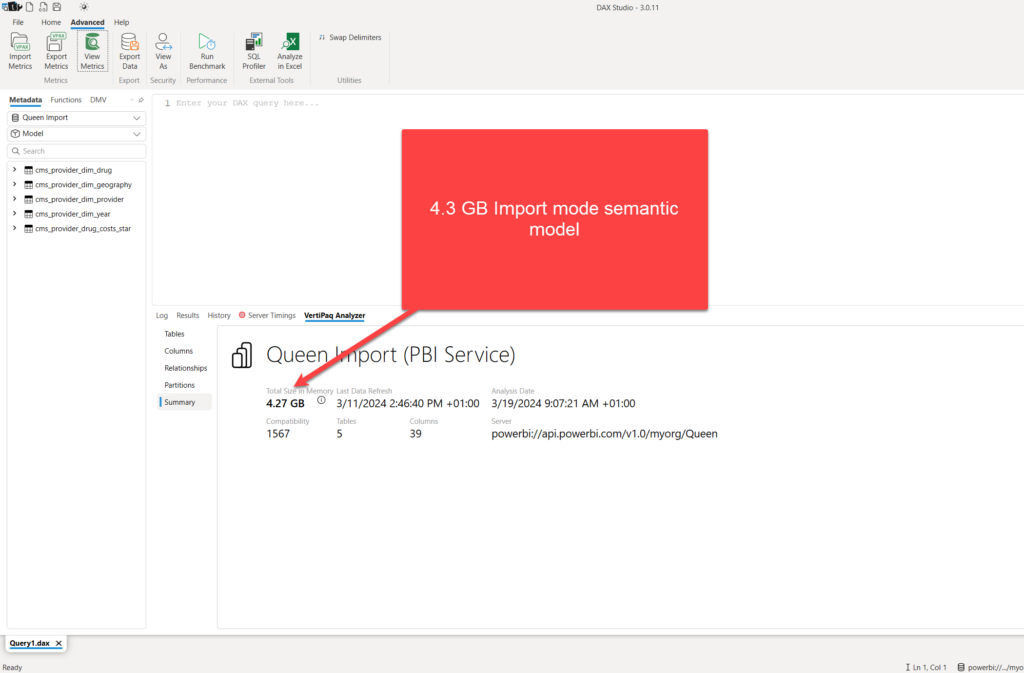
As you may see, the size of the semantic model is almost 4.3 GB! And, looking at the most expensive columns…
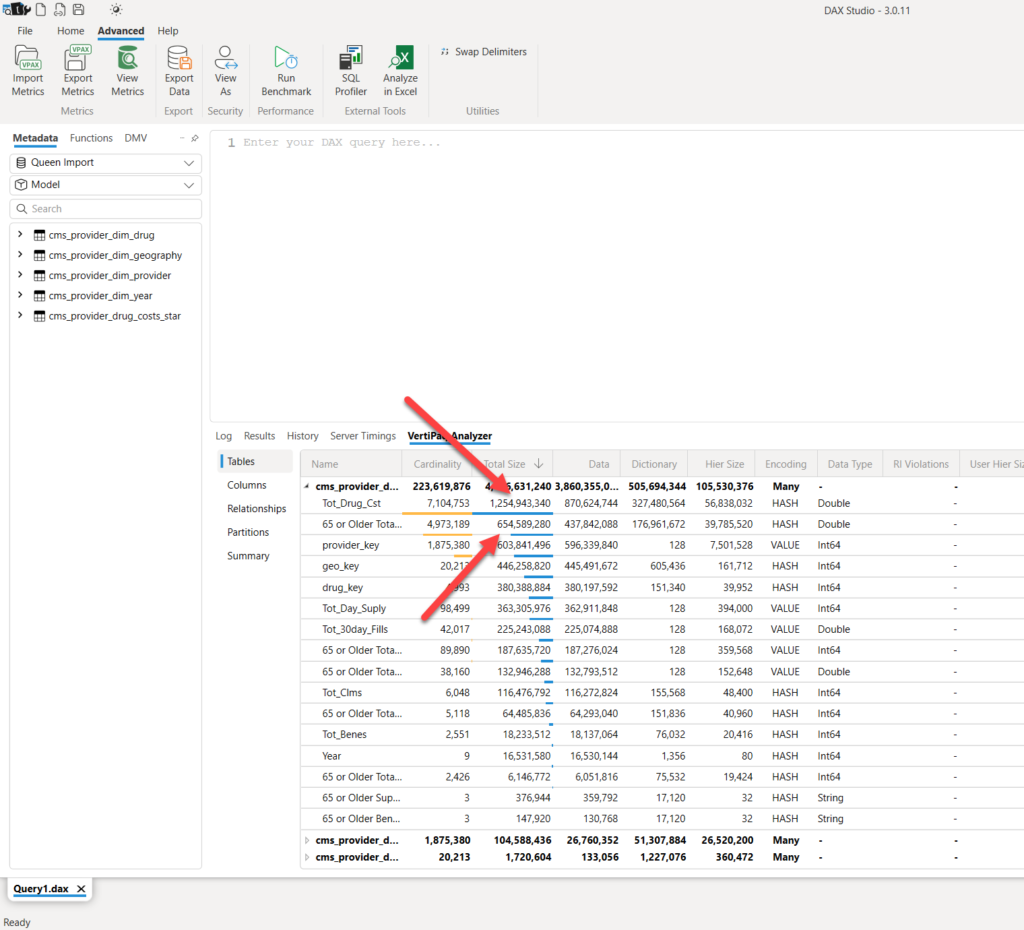
“Tot_Drug_Cost” and “65 or Older Total” columns take almost 2 GB of the entire model! So, in theory, even if no one ever uses these columns in the report, they will still take their fair share of RAM.
I’ll now analyze the DIrect Lake semantic model using the same approach:

Oh, wow, it’s 4x less memory footprint! Let’s quickly check the most expensive columns in the model…
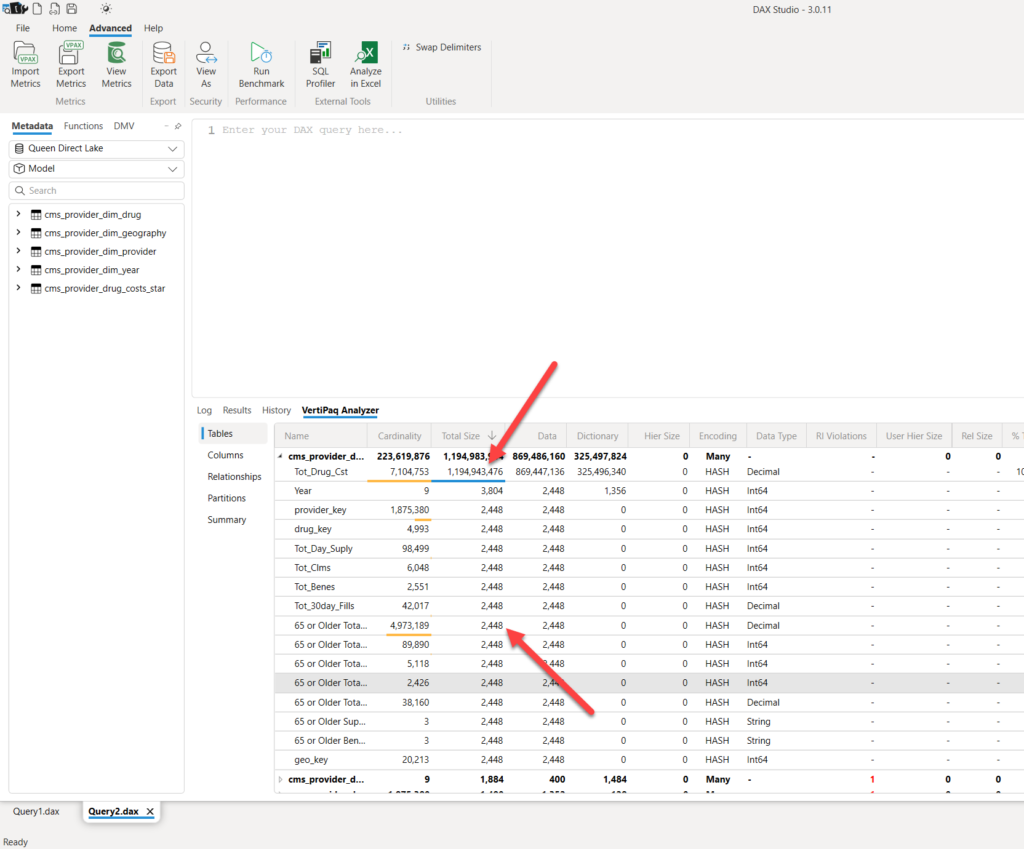
Let’s briefly stop here and examine the results displayed in the illustration above. The “Tot_Drug_Cst” column takes practically the entire memory of this semantic model – since we used it in our table visual, it was paged into memory. But, look at all the other columns, including the “65 or Older Total” that previously consumed 650 MBs in Import mode! It’s now 2.4 KBs! It’s just a metadata! As long as we don’t use this column in the report, it will not consume any RAM.
This implies, if we are talking about memory limits in Direct Lake, we are referring to a max memory limit per query! Only if the query exceeds the memory limit of your Fabric capacity SKU, it will fall back to Direct Query (of course, assuming that your configuration follows default fallback behavior setup):

This is a key difference between the Import and DIrect Lake modes. Going back to our previous example, my Direct Lake report would work just fine with the lowest F SKU (F2).
“You’re hot then you’re cold…You’re in then you’re out…”
There is a famous song by Katy Perry “Hot N Cold”, where the refrain says: “You’re hot then you’re cold…You’re in then you’re out…” This perfectly summarizes how columns are being treated in Direct Lake mode! The last concept that I want to introduce to you is the column “temperature”.
This concept is of paramount importance when working with Direct Lake mode, because based on the column temperature, the engine decides which column(s) stay in memory and which are kicked out back to OneLake.
The more the column is queried, the higher its temperature is! The higher the temperature of the column, the bigger chances are that it stays in memory.
Marc Lelijveld already wrote a great article on the topic, so I won’t repeat all the details that Marc perfectly explained. Here, I just want to show you how to check the temperature of specific columns of your Direct Lake semantic model, and share some tips and tricks on how to keep the “fire” burning:)
SELECT DIMENSION_NAME , COLUMN_ID , DICTIONARY_SIZE , DICTIONARY_TEMPERATURE , DICTIONARY_LAST_ACCESSED FROM $SYSTEM.DISCOVER_STORAGE_TABLE_COLUMNS ORDER BY DICTIONARY_TEMPERATURE DESC
The above query against the DMV Discover_Storage_Table_Columns can give you a quick hint of how the concept of “Hot N Cold” works in Direct Lake:
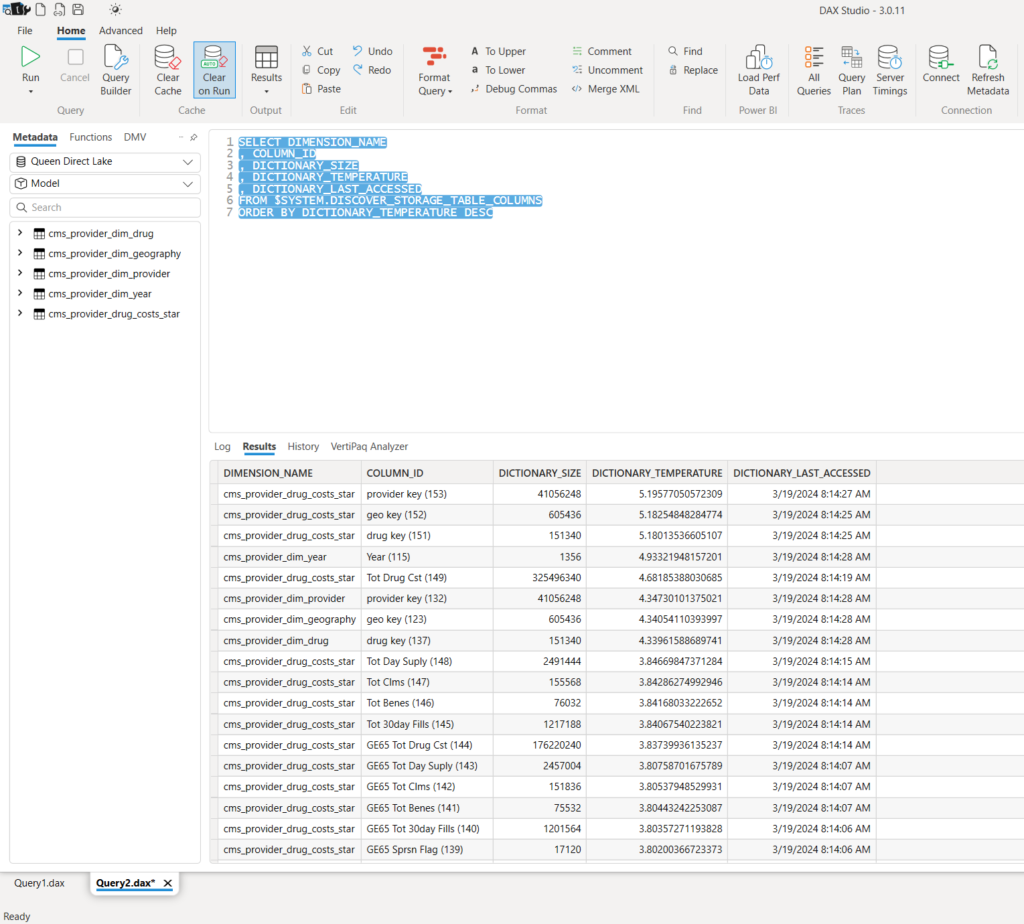
As you may notice, the engine keeps relationship columns’ dictionaries “warm”, because of the filter propagation. There are also columns that we used in our table visual: Year, Tot Drug Cst and Tot Clms. If I don’t do anything with my report, the temperature will slowly decrease over time. But, let’s perform some actions within the report and check the temperature again:
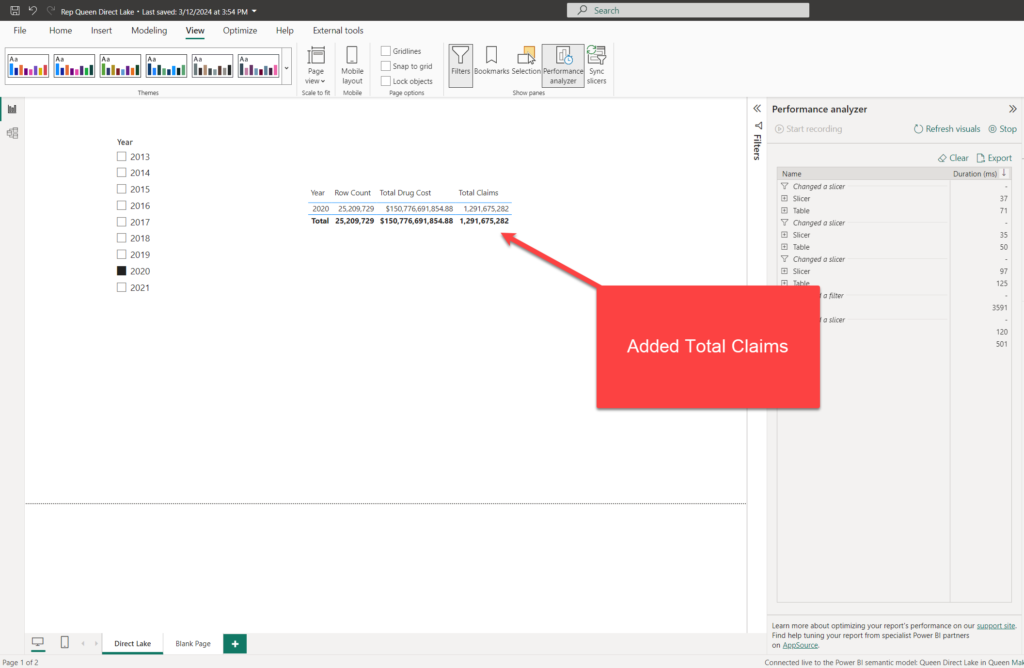
I’ve added the Total Claims measure (based on the Tot Clms column) and changed the year on the slicer. Let’s take a look at the temperature now:

Oh, wow, these three columns have a temperature 10x higher than the columns not used in the report. This way, the engine ensures that the most frequently used columns will stay in cache memory, so that the report performance will be the best possible for the end user.
Now, the fair question would be: what happens once all my end users go home at 5 PM, and no one touches Direct Lake semantic models until the next morning?
Well, the first user will have to “sacrifice” for all the others and wait a little bit longer for the first run, and then everyone can benefit from having “warm” columns ready in the cache. But, what if the first user is your manager or a CEO?! No bueno:)
I have good news – there is a trick to pre-warm the cache, by loading the most frequently used columns in advance, as soon as your data is refreshed in OneLake. Sandeep Pawar wrote a step-by-step tutorial on how to do it (Semantic Link to the rescue), and you should definitely consider implementing this technique if you want to avoid a bad experience for the first user.
Conclusion
Direct Lake is really a groundbreaking feature introduced with Microsoft Fabric. However, since this is a brand-new solution, it relies on a whole new world of concepts. In this article, we covered some of them that I consider the most important.
To wrap up, since I’m a visual person, I prepared an illustration of all the concepts we covered:
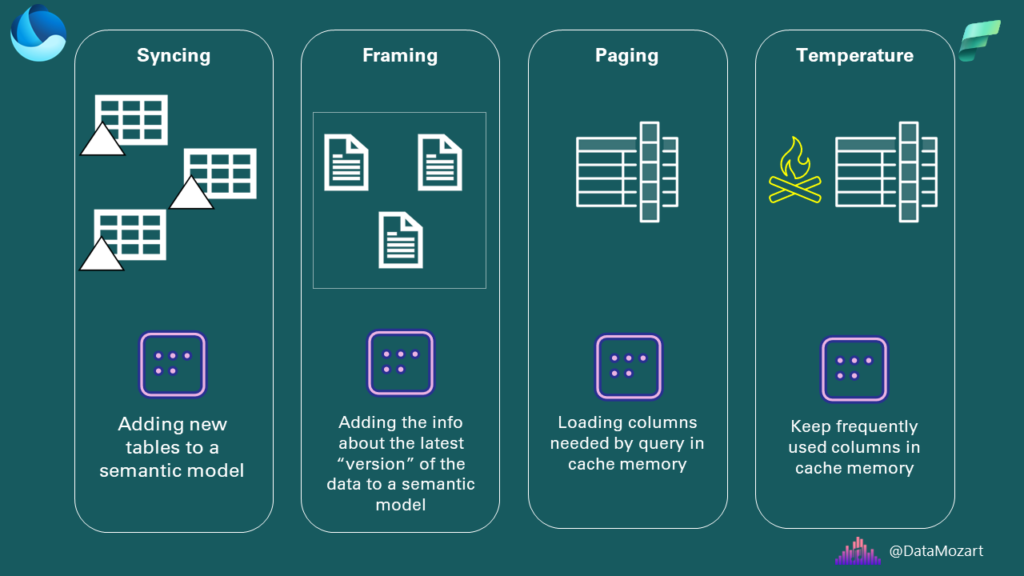
Thanks for reading!
Last Updated on April 27, 2024 by Nikola


