
Do you by any chance remember a guy called Allen Iverson? If you’re an NBA fan, you probably know about an incredibly talented point guard, who spent most of his time playing for the Philadelphia 76ers in the 2nd half of the 90s and the first half of this century. Iverson was a lethal scorer, averaging more than 26 points per game during his career! He was also the league’s MVP in 2001, taking part in 11 All-Star games, and finally, finding his well-deserved place in the Basketball Hall of Fame.

But, aside from all these accolades, Iverson was well known because of his nickname – “THE ANSWER”! The story behind his nickname is quite intriguing: in the mid-90s, the NBA was somehow at a crossroads, lacking “authentic” stars – “Magic” Johnson and Larry Bird retired a few years ago, whereas the one and only Michael Jordan took a sabbatical after winning three NBA titles. There was an obvious void in the game, and the League needed “the answer” to fill that void. The rest is history – “The Answer” epitomized a new era coming to the NBA, a breath of fresh air, and something that had a great impact, not only on the game itself, but also on creating a role model in the popular culture.
Ok, nice story, but Iverson retired a long time ago, and this is a technical blog…The topic of this blog is not Allen Iverson, right? Right…
What the heck does Iverson have in common with Direct Lake then?!
TL;DR: They both represent “THE ANSWER”!
You’ve heard a story about Iverson and how he WAS “the answer” to fill the void in the NBA ~30 years ago. Now, let’s see why and when Direct Lake is “the answer”, and which void(s) it should fill…
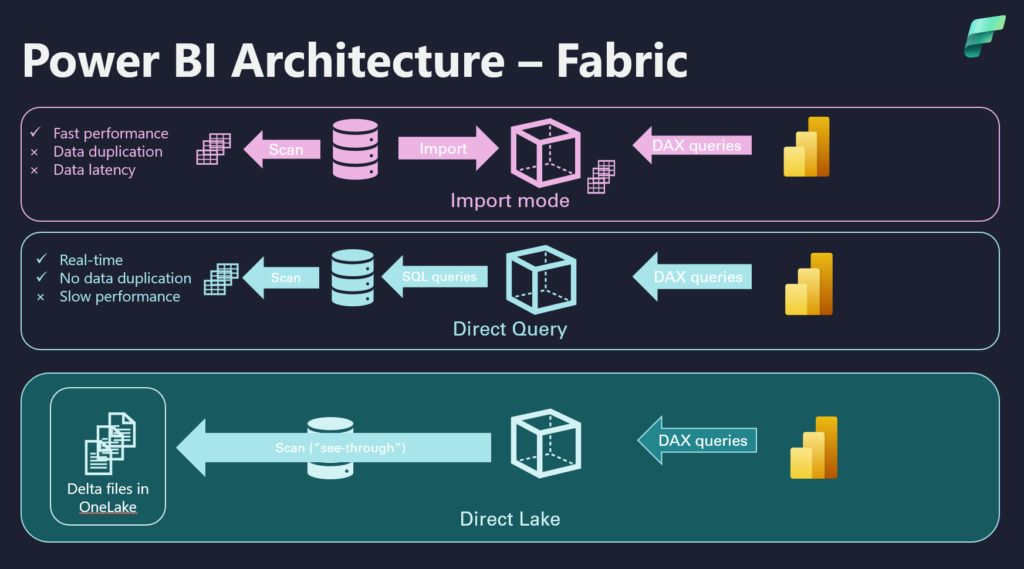
Direct Lake is a brand new mode for consuming data through Power BI Semantic Models, which is exclusively available with Microsoft Fabric. It aims to fill the void caused by shortcomings of both Import and DirectQuery modes, by combining their main advantages: performance of the Import mode, as well as near real-time reporting and “no data duplication” of the DirectQuery.

As you may see in the illustration above, this is the world we “know” before Fabric (by the way, if you are still not sure what Microsoft Fabric is, I suggest you start by reading this article first). To summarize: with Import mode, we get blazing fast performance, because the data is stored in memory. However, in order to keep the data in sync with the original source, we need to refresh the Power BI Semantic Model, which means there is some latency (duration of the data refresh process), plus another copy of the data (basically, we are storing the same data twice – once in the original data source, and then again in the instance of the Analysis Services Tabular, which stores our Power BI Semantic Model data).
And, then, we have a DirectQuery! No data duplication, and no latency, as we are querying the source directly, with queries generated at the query time – meaning, we always get the latest data in our Power BI reports! Import mode challenges solved, life is good…Until it isn’t:). The performance of DirectQuery mode is in most cases, well, let’s say – barely acceptable (if acceptable at all). There are also many additional limitations compared to Import mode, so although DirectQuery, in theory, is “the answer” to the shortcomings of the Import mode, in reality, it’s just another “question”: why do you use DirectQuery?
Direct Lake IS “THE ANSWER”!
When Fabric was introduced, Direct Lake was labeled as one of the key innovations in this SaaS platform. And, rightly so! While we can argue that certain components of the Fabric are just rebranded existing solutions, Direct Lake is definitely a brand-new concept.
How does the Direct Lake mode work?
Direct Lake conceptually works very similar to the Import mode. The “only” difference is that, instead of requiring data to be stored in the Analysis Services Tabular proprietary file format (*.idf), the Power BI engine (VertiPaq) can read the data directly from Delta tables stored in OneLake. The way data is stored in Delta/Parquet files is very similar to how VertiPaq stores the data (columnar storage, data compression, etc.), so the engine can “understand and interpret” the data practically the same as it would when reading it from Analysis Services Tabular instance (Import mode).
The key difference between the Import and Direct Lake mode is that in Import mode, the entire semantic model is loaded into memory, whereas in Direct Lake only the columns required by the query will be loaded into memory.
Direct Lake Prerequisites
Here is the list of the prerequisites for Direct Lake mode to work with your Power BI semantic models:
- F or P SKUs (Fabric capacity or Power BI Premium capacity with Fabric enabled)
- Lakehouse or Warehouse in Fabric workspace
- Delta file format – although you can store various file types in the Lakehouse, Direct Lake currently supports only Delta (no Parquet, CSV, etc.)
- V-ordering* – this is not a “no-go” prerequisite – Direct Lake will still work even if Delta files are not v-ordered – but, you could then expect performance degradation. More on v-ordering here
Fallback to DirectQuery
Whenever a Direct Lake Semantic Model can’t retrieve query results from Delta tables using a Direct Lake mode, the query will by default fall back to a DirectQuery mode. This may happen for various reasons, some of them are listed below:
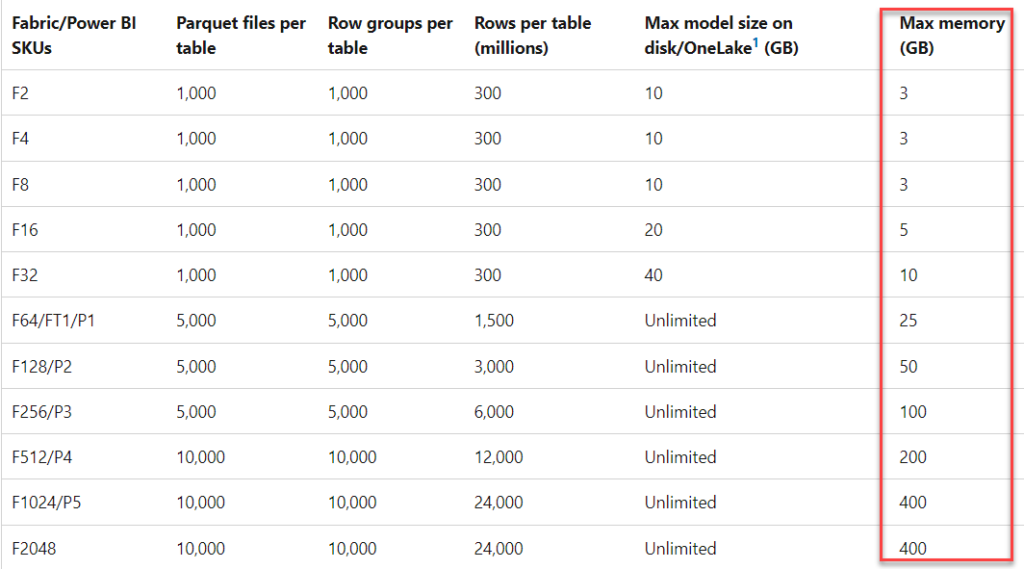
- DAX query exceeds the memory limit of the F/P SKU. Current limits are displayed in the table below, in the most-right column (Max memory (GB))
- The feature is not supported in the Direct Lake mode (i.e. views in Fabric Warehouse)
Whenever the query falls back to DirectQuery mode, all the limitations of the DirectQuery mode (performance degradation, lack of support for certain DAX functions, etc.) apply.
Fallback behavior can be configured manually (DirectLakeBehavior property), using TOM or TMSL. By default, it will automatically fall back to DirectQuery. This property can also be configured to DirectLakeOnly (if no Direct Lake mode is possible, an error will be thrown), or DirectQueryOnly (useful for testing fallback performance)
Data sync between Semantic Model and Delta tables
Whereas in Import mode it is necessary to ensure that the data is in sync with the data source by configuring a scheduled refresh, in Direct Lake mode (unless explicitly disabled), Semantic Model will automatically apply the latest changes from OneLake.
This property can be configured in the Semantic Model settings:

Limitations and considerations
Direct Lake is, the same as the entire Microsoft Fabric, a work in progress! This means, features are being added at a rapid pace, and some of the limitations that currently exist will probably be resolved in the future. Therefore, listing all the current limitations wouldn’t make much sense (because this article would then need to be updated more frequently than not).
I’ll give you some friendly advice – the same as I advise my clients who are moving to Microsoft Fabric:
Always check the current list of limitations and known issues here.
This is the link to the official Microsoft Learn page, so that one should always be relevant when considering if something is (not) possible in Direct Lake mode.
Additionally, my friend and fellow MVP Sandeep Pawar (x), created a dedicated Direct Lake Q&A page on his blog, so it wouldn’t make sense to repeat what Sandeep already tested and answered – go and check if your question has already been addressed by Sandeep.
Conclusion
Going back to the beginning of our story – the same as Allen Iverson was “the answer” to the void created in the NBA in the mid-90s, Direct Lake fills the void caused by downsides of both Import and DirectQuery modes.
Is then Direct Lake an ultimate goal, “the answer” that we should use to address each and every “question”? Absolutely not! There will still be many, many (I dare to say the majority) use cases when sticking with the proven way of doing things (Import mode) should be your preferred choice, especially until some of the key Direct Lake limitations still exist (i.e. as of today, you can’t leverage features such as calculated tables/columns, and composite models in Direct Lake, whereas views will always fall back to Direct Query). However, Direct Lake is here to stay and it is absolutely worth calling it “the answer”!
Thanks for reading!
Last Updated on January 29, 2024 by Nikola


