

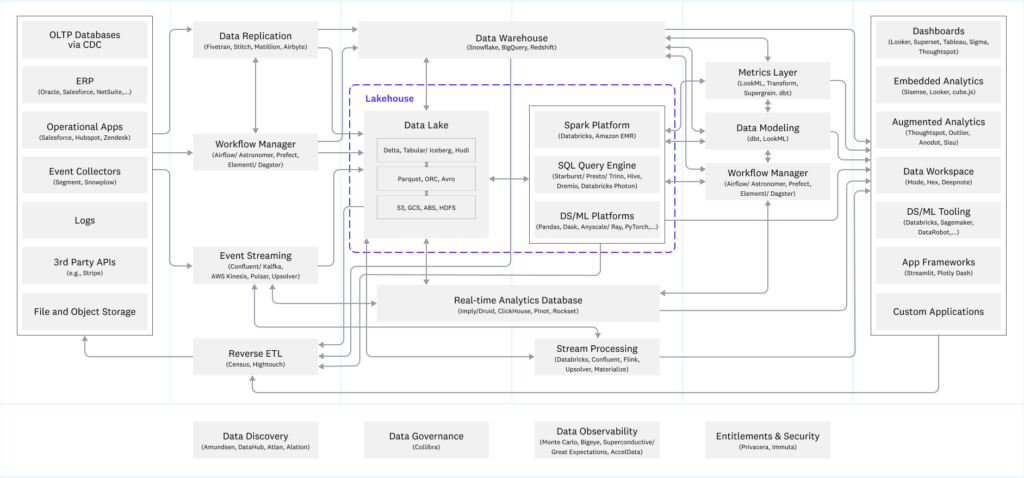
How many times have you seen a diagram like this?
Or, maybe something like this?
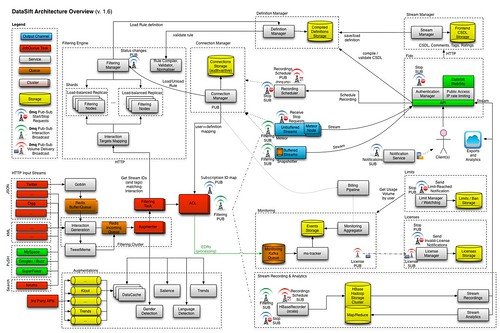
Looks too complex and overwhelming? Yes, to me too! I feel your pain.
In real life, more often than not, this is exactly how the data ecosystem looks across enterprises. Disparate data sources, various ETL tools used to ingest and transform the data, data silos all across the organization, while numerous teams within the organization leverage a bunch of different tools to prepare the data that will be consumed by business users and executives.
If I asked you: where does the specific number in the report come from? How has it been calculated? Looking at one of the diagrams above, how easy and straightforward would it be for you to find an answer?
On the other hand, it’s not all about the specific tools and vendors used. It’s also about the PEOPLE! There are many different “data personas” within the organization. These individuals possess a different set of skills, their tasks are quite diverse and, finally, they need to answer different business questions and comply with different business processes. So, the valid concern is: how to enable all data personas in the organization to thrive, while delivering quick, efficient, and accurate solutions? Simply said, how to provide them with the PLATFORM for creating robust, flexible, and secure data workloads?
Tag along with reading and you will understand why Microsoft Fabric may be THE ANSWER to these questions…
What is a Microsoft Fabric, in the first place?
I’ll start with the analogy. I’m a huge football fan (or soccer, if you prefer)! So, in a football team, you have players with different characteristics, playing in different positions, possessing different sets of skills…For example, you have very fast players that can play on wings and utilize their speed to create chances for their team. Then, you have strong and tireless players who can excel in defense. You need a goalkeeper, to protect your team from the opponents’ attacks. Finally, you have players who are skilled to score goals. Now, imagine yourself being a coach of this team. So, you have all these players at your disposal and your task is to establish the system that best fits your players, with winning the match as the ultimate goal.
Think of Fabric as the “data football team”! Microsoft provides you with the “players” and your task is to integrate these players into the system that will ensure success. These “players” are already well-known, seasoned “stars”, such as Power BI, Azure Synapse Analytics, and Azure Data Factory. But, there are also some fresh “faces”, newcomers that should bring fresh blood to your experienced team. We will examine most of these “players” in this blog series.
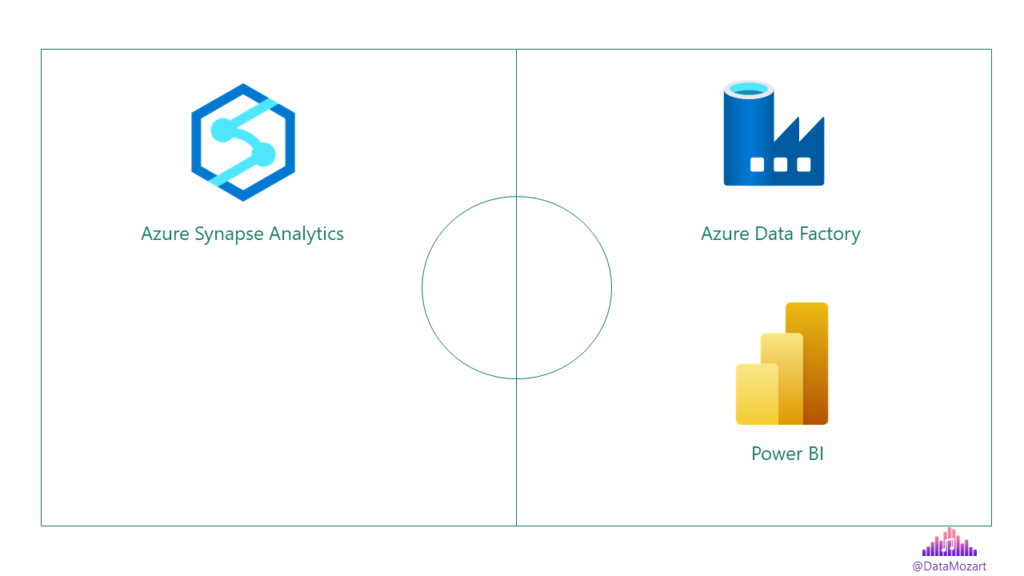
At this moment, it’s important to understand that Microsoft Fabric IS NOT some new, fancy tool or product. It’s a suite of individual analytic tools and services that work in synergy to provide a unified analytics experience.
Now, you are probably wondering: wait, wasn’t Azure Synapse Analytics labeled as a solution to provide a unified analytics experience a few years ago?! Errr, yes, you’re right:). So, we now have another unified analytics solution (Microsoft Fabric) that unifies one of the previous unified solutions (Azure Synapse Analytics). Sounds confusing, I know. But, don’t blame me, blame Microsoft:)
What does UNIFIED mean in the context of Microsoft Fabric?
It’s about a unified experience! Whether you look at the single workspace experience, single sign-on experience, single storage format, all the way to single experience for managing security and collaboration.
This is a high-level overview of our “data team” under the Fabric umbrella:
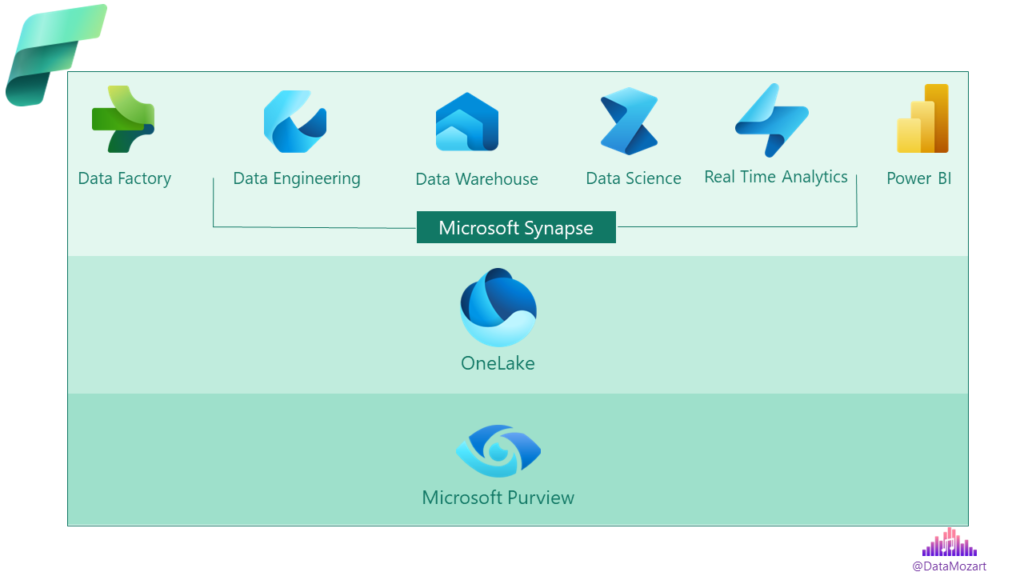
You might (rightly) assume that some “players” simply changed their “shirts”, but their skillset and strengths remain the same.
So, is the Microsoft Fabric just a re-branding of the existing Microsoft data offering? Well, to some extent yes, but there are certain features and capabilities that are brand-new and promising. Keep reading and we’ll come to explain these in more detail.
Ok, that is the unification from the service-level perspective. From the professional-level perspective, we can talk about unification from the perspective of different personas in the data world. Remember when we were talking about different players on the team? You may have BI professionals coming from a traditional relational databases background. Then, data engineers, data scientists, or data analysts…All these personas can leverage this unified Fabric experience to play to their strengths.
What are the key pillars of Microsoft Fabric?
1. “Everything-as-a-service” – Simply said: “It just works”! You don’t need to care about the hardware, infrastructure, or complex administration. By taking advantage of the instant provisioning and straightforward onboarding, the focus can be shifted to the data analysis itself, ensuring that business can quickly get results. In this scenario, the integration and optimization happen automatically.
2. Centralized administration – the idea is to govern one tenant, which contains all organizational data artifacts. So, various data professionals across the organization don’t need to worry about security or compliance challenges, because everything is handled in one place
3. Low-code + Pro Dev – In large enterprises, it’s always this kind of challenge – there are many more business users around, self-service users, that can’t rely on the small number of pro developers to meet all their requirements.

So, the idea is to enable business users to move forward without waiting for Synapse/Spark developers. It’s a win-win scenario, where business is not blocked in the process of performing data analysis, while pro developers may spend more time on doing the “hard”, more code-intensive stuff in the background.
4. Lake, lake, lake… – Data Lake is at the core and center of the Microsoft Fabric. And, since we were talking about the unified experience, how would that experience work without the unified lake😊 Or, OneLake, if you prefer that name (and Microsoft prefers it, because this is the official name of this SaaS solution).
Do you know what is OneDrive? Of course, you do! Think of OneLake as OneDrive for all your organizational data artifacts. Now, think of all the various analytic engines that are part of the Fabric: SQL, Spark, Real Time Analytics (Kusto), and all the different applications that are reliant on accessing the data in the most efficient way – meaning, reducing data duplication and data movement across different services.
Additionally, think of all the different personas in the organization. Providing business insight from the raw data is a team effort, which requires collaboration between various data professionals. Enabling all these individuals and teams to work synchronously is one of the key advantages of OneLake.
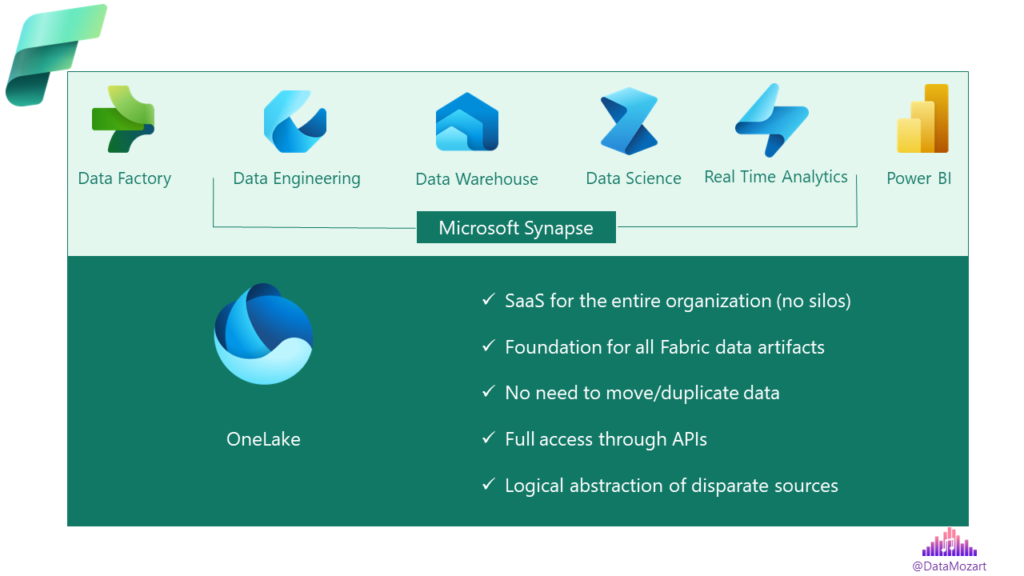
Simply said, it’s a logical structure of files and folders, that may point to disparate data sources. So, your data might be coming from ADLS Gen2, but also from other vendors, such as Amazon or Google. From the end user’s perspective, they are just navigating through the files and folders in OneLake, as a logical layer between the data source and the final data destination (for example, a Power BI report).
From a conceptual point of view, this is a Data Mesh architecture, where every department within the organization can manage their data as a product. However, since we are talking about a unified experience, it’s still easy to bring the data, mash it up and get together across the entire organization.
5. Lakehouse is the architecture of choice – Nowadays, there is an ongoing debate in the analytics world: data lakehouse vs data warehouse. Explaining the pros and cons of each of these concepts is out of the scope of this article, as well as providing the answer to which one is “better”😊
We’re examining Microsoft Fabric, so we’ll stick with the facts – and the fact is that the lakehouse is the architecture of choice in Fabric.
Although Microsoft makes a distinction between the Lakehouse and Warehouse analytics scenarios, in my opinion, this separation just introduces confusion. And, let me explain why…
In today’s cloud analytical landscape, we have a separation between the storage and compute layers. If we are talking about storage:
Data Lakehouse = data stored as files in the lake (in ACID-compliant Delta Lake format)
Then, you can choose between different engines (Spark, Polaris, etc.) to process (read/write) files in the storage. And, in Microsoft Fabric, the storage layer is LAKE. To be more precise, OneLake, which we previously examined.
Therefore, don’t be baffled when you hear someone talking about Data Warehousing in Microsoft Fabric. It’s still a lake in the background as a storage layer, but the engine (Polaris engine, that we already know from Serverless SQL in Azure Synapse Analytics) and data manipulation are SQL-flavored
More on the data warehouse and data lakehouse scenarios later in the article…
6. Aimed at a variety of data personas – Going back to my analogy with the football team and its players…Do you have a player who is great with their left foot (your equivalent “data” player who is proficient in writing Python code)? Or, do you have a player who is a fantastic free-kick shooter (the equivalent “data” player who is skilled in SQL language)? Do you want your team to play with more “attacking” formation (using more Spark in the workloads)? Or, do you prefer a more “conservative” approach (sticking with the SQL way of data manipulation)? The choice is yours, but whatever you choose, you have one single copy of the data, and all your players can leverage this one single copy.
And, based on the specific analytic task that needs to be performed, you may choose between multiple Fabric engines. The key thing to keep in mind is that once the data is stored in OneLake, it can be directly accessed by all the engines, without needing to copy or move the data from the lake.
7. DirectLake is the revolution! – Now, if you’re a Power BI professional (like me), you’re probably wondering: wait, does that mean that we don’t need to copy the data from the lake into Power BI (Import mode)? Can we query this data directly from the lake (Direct Query mode)? The answer to both questions is: YES. You don’t need to copy the data from OneLake to the instance of the Analysis Services Tabular behind Power BI.
Ok, Nikola, that’s nice, but if I choose a DirectQuery option, I’ll have to pay all the penalties and live with all the limitations when using DirectQuery… Well…Not really!
In my opinion, one of the key enhancements that Fabric brings into the data analytics world is DirectLake Mode!
Why is it so special? Because now, the Power BI Analysis Services engine can do the same as SQL and Spark engines – directly access the data in OneLake (data stored in Delta/Parquet format files) and consume the data directly from there, without any data movement, while achieving the same performance level as when using the Import mode (at least, that’s what Microsoft proclaims, still need to be tested)!
To simplify – you get the performance of Import mode, without copying the data, while at the same time having real-time data available in your Power BI reports! This sounds like heaven😊 And, I can’t wait to test it in real-life scenarios…
8. Seamless integration with other Office tools – Once you create your data story using Power BI, as you may assume, this story can be seamlessly integrated within other Office tools, such as Excel, PowerPoint, Teams, Outlook, etc.
9. Security and governance – another extremely important topic, that may become more straightforward with Fabric. Data lineage and Microsoft information protection labels, to name a few, are fully supported in Fabric, so if you mark something as highly confidential, this label will be applied to every data artifact moving through the system.
Finally, the Admin center serves as a centralized location for all administrative tasks, such as tenant settings, networking stuff, usage metrics, and so on.
Lakehouse, Warehouse…Understanding different “houses” in Microsoft Fabric
Thanks to Jovan Popovic and Priya Sathy from Microsoft for providing the guidance regarding this topic
As already mentioned, Microsoft Fabric is a lake-centric solution. This means, OneLake is the focal point and central repository for storing all organizational data. So, in its essence, Fabric is a lakehouse architecture, since the data is stored in the lake in Delta/Parquet file format, and from there can be processed by using any engine/tool capable of reading Delta format.
At this moment, Microsoft Fabric offers you two possibilities for handling these workloads:
- Lakehouse – in this scenario, data is loaded, transformed, and curated by leveraging Spark notebooks
- Warehouse – in this scenario, data is loaded, transformed, and curated by leveraging the T-SQL language
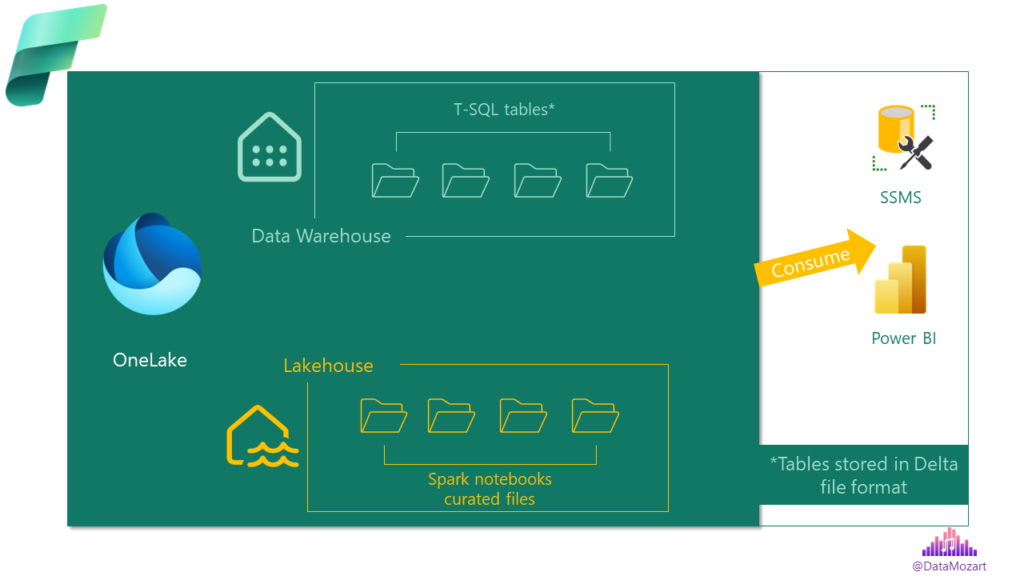
Obviously, this is a high-level distinction and there are many more nuances between these two, that I’ll cover in a separate article.
The storage layer for both scenarios is the same – OneLake. And, the storage format is the same: Delta file format.
Therefore, a valid question would be: which should I use? As per my understanding, the key criteria should be the skillset and/or preferences of your data engineering team. If the majority of your team consists of Spark engineers, your default choice should be Lakehouse. On the flip side, if your team feels more comfortable using traditional T-SQL for data workloads, then you should go “the warehouse path”.
The good thing is that the Lakehouse (Spark) exposes a SQL endpoint, so you can also leverage T-SQL to QUERY the data stored in Spark tables. I’ve intentionally emphasized the word QUERY, as in this scenario, when you’re using T-SQL over Delta files stored in the Lakehouse, there is a limited set of T-SQL features supported: for example, no DML operations are allowed (insert/update/delete), but you can create views and TVF, similarly to current setup in Synapse Serverless SQL.
The next fair question would be: what if my data engineering team consists of mixed professionals – let’s say, a data engineer that loads the data is proficient with Spark and then the other data persona responsible for curating that data wants to use SQL? Does that mean that I need to copy the data from the Lakehouse bronze (raw) layer into the Warehouse, so that “SQL-pro” can continue curating the data and preparing it for the silver and gold layers?
The answer is NO! Fabric supports cross-database queries, so in theory, you can do something like this:
SELECT col1
,col2
,col3
,....
FROM SilverTableDataWarehouse
INNER JOIN BronzeLakehouse.dbo.BronzeTableLakehouse
....
The only prerequisite is that tables in both DWH and Lakehouse are in Delta format (CSV/Parquet is not supported for this scenario). Performance-wise, there is no difference if you are querying the data directly from the Warehouse vs data in the Lakehouse, because all of these tables are in the end stored in OneLake, as a central storage repository.
How much will it cost me?
I know that most of you are interested in this part (and I don’t blame you:))
For using Microsoft Fabric, you’ll have to purchase F SKUs. If you had any exposure to Power BI licensing, then this model should look familiar. If not, I suggest you start by reading this article on Power BI licensing. Since you are paying for the capacity, this means that you need Fabric capacity to be able to leverage Fabric services. Premium-per-user and Pro licenses are not supported at this moment.
Power BI P1 SKU (which is currently priced at ca. 5.000 $/month) is equivalent to F64 SKU (8 v-cores). The great thing about Fabric SKUs is the much lower entry point. Unlike Power BI P SKUs, where the entry point P1 SKU will cost you, as mentioned above, 5.000 $/month, the entry point into the Fabric world (F2 SKU with 1/4 v-cores) will cost you ca. 300 $/month! This is a huuuge difference and will probably enable many organizations to dive into the Fabric!
However, keep in mind that all Fabric SKUs smaller than F64 will still require a Power BI Pro license for every user that needs to consume Power BI content.
More on Fabric pricing and licensing options in one of the next articles. In any case, you have 60 days available to test Microsoft Fabric for free:)
What now for Azure Synapse Analytics?
This is definitely “a million dollar” question😉…Not so long ago, Azure Synapse Analytics was hailed by Microsoft as a solution to “unify all your data analytic workloads and enable building end-to-end analytic solution from one central place” (does this sound familiar😉?)
So, the question is: will Microsoft slowly shut down Synapse, by “drowning” it into the new “data ocean” called Microsoft Fabric? Well, honestly, I don’t know:)

As of today, looks like Dedicated SQL and Serverless SQL pool are somehow integrated into one solution in Fabric (Warehouse). We have traditional structures from the Dedicated SQL pool, such as columnstore indexes (not explicitly, but implicitly through the column store of Parquet format), data cache, etc. At the same time, Warehouse relies on the Polaris engine, which currently powers the Serverless SQL pool. This is an MPP (massively parallel processing) engine, which scales AUTOMATICALLY to support various data workloads. In other words, no more DWUs, whereas scaling out is now done by the engine, not by someone from your data team.
There is still no result-set cache, but I’ve been told that it’s coming soon.
To wrap up: I really don’t see any reason for new customers to choose Azure Synapse Analytics over Microsoft Fabric, except maybe costs, because, in some scenarios, it may happen that prudent usage of DWUs in a Dedicated SQL pool, in combination with a pay-per-query model of the Serverless SQL pool will cost you less than Microsoft Fabric. For existing Azure Synapse Analytics users, there will be the option to integrate current Synapse workspaces into the new Fabric experience, but more on that in one of the next articles.
Personally, this is one of the areas I’m mostly interested in, and I’m really curious to see what the future brings for Azure Synapse Analytics.
Conclusion
Not many tech announcements produced more hype than the Fabric one at MS Build. And, for a good reason, I would say. Even though most of the platform was “already there”, and it might look that Microsoft simply rebranded the product once again, there are certain features and concepts that can really change the analytics game we play now.
In the first place, I’m talking about the DirectLake mode in Power BI, which potentially elevates the whole landscape into another dimension. However, by performing comprehensive performance tests, we can really confirm if this feature “wins” against the Import mode, which is the current “de facto” standard for Power BI performance.
Obviously, Microsoft Fabric is still a work in progress – hey, it’s been just announced and is still in public preview… This means that many features will be added/improved/adjusted in the coming months. So, let’s wait for the final judgment.
However, the overall Fabric idea and concepts around it, testify that Microsoft does not have any plans to surrender its leading position in the enterprise data analytics world.
Thanks for reading!
You can also watch the video on my YouTube channel:

Last Updated on October 27, 2023 by Nikola



Jeroen
Love this article! What’s your take on Databricks in this light? Does it even make sense to invest in a new data platform from scratch and have Databricks in it?
Neel
I too been thinking about whether this would kill Databricks eventually.
Daan Damhuis
About the capacity’s, we just bought 4 P1’s. Can I use fabric with those capacity’s? That is still not really clear to me..
Nikola
Hi Daan,
Yes, you can use Fabric with P1 SKUs.
Stay tuned, I’m soon publishing an entire article on Fabric licensing options.
Cheers!
Jhon Secc
Excellent article.
Where did you get this information about 300 dollars the price of the F2. Could you share? I would like to know the other prices as well.
Thank you and congratulations for all your content.
Nikola
Thanks Jhon.
The information about the prices is still “non-official”:) It appeared for a short period in some Azure tenants, but from June 1st, we should have a final Fabric pricing list available. Stay tuned!
Vladimir Petrinic
Hi Nicola,
Great blog.
One question regarding cost.
In part “How much will it cost me?” you present (that’s how I understood it) that Fabric could get independently of Power BI licensee. You compare the cost of Premium and Fabric and point that as a big advantage, but if I wish to have Fabric I have to have Premium capacity.
So, on top of 5000$/month I have to add 300$/month more for Fabric?
Did I understood well?
Nikola
Let’s wait for the official pricing list for Fabric (coming soon). But, the short answer is: NO, you don’t need to have Premium capacity as a prerequisite for Fabric. You can buy F SKUs independently from P SKUs.
WWV
You tout Fabric’s ability to directly access the data, but the data still has to be moved into OneLake in the first place. There are platforms like Pyramid Analytics that perform TRUE direct query without ever moving it out of the source system. Pyramid also is a single platform, unlike the conglomerate of tools that make up Fabric and Synapse, resulting in a lower total cost of ownership. Better performance at a lower cost? I’ll take that over Microsoft’s ridiculous complexities and costs any day!
Nikola
I don’t know about the Pyramid, but I’m happy that there is a competition out there, so customers can choose the solution that best suits them.
Dev
Why do you ever want to query the source system directly for DWH workloads? Its a great system to kill your source system. Also the data is ALWAYS extracted from the source system. Whether it is to a DWH or a front end tool(Simply cache/memory). The only way to truly not duplicate the data is to view it in the source system itself.
There is no secret sauce to circumvent this. Also there are many source system who will not even allow you to directly query. They either have an export function or API. And there is NO way to directly the source data.
In other words, this post seem either to be clueless or working as a sales person for Pyramid Analytics
JP Louw
Excellent article Nikola.
Just one Q: having passed PL-300 already and preparing for DP-500, would this still be worthwhile to do? Would there be a new certification from Microsoft for Fabric?
Nikola
Good question! I don’t know the answer, though. At this moment, DP-500 is still the way to go for the enterprise data analytics in Azure, and I’m pretty sure that there will be no exam/cert around Fabric until it goes GA (which means, at least a few more months). Hope this helps.
Denys Chamberland
Indeed I doubt there will be exam/cert around Fabric until it goes GA. I’ll take a bet somewhere by the end of December maybe sooner though it’s a wild guess. Now big question we may ask is if all time & energy invested in Synapse wasted (I had been planning for dp-203 including covering all Synapse Studio options inside & out though I hated Pearson proctored modus operandi & rather was hoping to find authorized partners in my neighborhood) So I don’t feel nothing was wasted at all. IMHO we never really lose, we learn;)
Nikola
Couldn’t agree more with you Denys👍
Chris
Thanks for the this great article. Are you sure that traditional structures such as columnstore indexes are supported in the warehouse ? I read the preview docs up and down and can’t find any info about that. It looks it’s delta only and with delta the varchar size seems to be limited to 8000. I know it is preview only but this and no openrowset, no parquet nested types/unnest functions is very restricting.
Nikola
Hey Chris,
Thanks for bringing this, good point that requires additional clarification. Columnstore indexes are not “explicitly” supported (you can’t write CREATE INDEX statement), but implicitly through the column store of Parquet/Delta formats.
Andres
I’m a bit confused about what you write ‘keep in mind that all Fabric SKUs smaller than F64 will still require a Power BI Pro license for every user that needs to consume Power BI content’, does this mean that you need premium Power BI capacity AND users that consume also need a PBI Pro account to consume content? If so, does this mean that without premium PBI capacity we cannot use any features of Fabric?
Nikola
Hi Andres,
No, you don’t need Power BI Premium capacity to use Fabric. Fabric SKUs are separated from P SKUs. BUT, if you purchase Fabric SKU < F64, then your Power BI content consumers will need Power BI Pro license. For >= F64 SKU, Power BI content consumers don’t need Power BI Pro licenses. Hope this helps.
Andres
Thanks so much Nikola, yes this makes it very clear.
Denys Chamberland
RE: “This is definitely “a million dollar” question😉…Not so long ago, Azure Synapse Analytics was hailed by
Microsoft as a solution to “unify all your data analytic workloads and enable building end-to-end analytic solution
from one central place” (does this sound familiar😉?)”
Hi Nikola,
Yup it sure rings a bell, I remember the Swiss knife gif animation as well. I guess we can now all say “Hasta la Vista Baby” to Synapse Studio. Scripts created through Serverless SQL pool using OPENROWSET(BULK) are not upgradable
and will no longer be supported by new Microsoft Fabric Delta Lake.
So some manual refactoring will undoubtedly need to be done to run similar logic on new Microsoft Fabric ecosystem at some stage. I personally never was a big fan of the OPENROWSET(BULK) method, so I don’t really feel missing much.
Serverless SQL pool may have had control node|calculating control similarities with Dedicated SQL pool though I feel it had somehow different engine morphology under the hood.
Also Serverless SQL pool didn’t offer much control option compared to Dedidacted SQL pool besides being able to set montly, daily or hour consumption scope limits through Synapse Studio -> Manage hub. That was about it. Still curious to know which configuration options will be accessible in new Microsoft Fabric
I also found it was still possible to set “Custom” Spark pool configuration needed for specific scenarios… in Microsoft Fabric using pretty similar UI form options interface as we found on Synapse Studio.
So you’re right, up to now we can say that Synapse Studio was THE main workspace head quarter configuration tool accessible as Azure resource through Azure portal. (Some configuration could be achieved through PowerShell & AZ CLI as well)
“RE:Microsoft slowly shut down Synapse, by “drowning” it into the new “data ocean” called Microsoft Fabric”
Well if someone had claimed a year ago, that the main Synapse management access would transit from Azure Synapse Studio to land at the very bottom left corner of Power BI Online service – hidden right under a Power BI icon, I would have probably reacted giggling (yeah sure!!).
I doubt Synapse will totally disappear however. Maybe rebranded names & acronym who knows? Probably the closest comparaison was an image of a phoenix mythic bird recycling from its own ashes shared by Andy Cutler…though I haven’t smelled any smoke on my side yet, so I proposed a monarch butterfly coming out of its cocoon. Hey just normal nature evolution transition. (cough… cough… cough…)
Following statement regarding Power BI Admins promoted to Fabric Administrator as of June 2023 raised some concerns.
“Power BI Administrator role will be renamed to Fabric Administrator”
https://powerbi.microsoft.com/en-cy/blog/power-bi-administrator-role-will-be-renamed-to-fabric-administrator/#:~:text=Starting%20June%202023%2C%20the%20Power,the%20new%20role%20name%20gradually.
“Starting June 2023, the Power BI Administrator role will be renamed to Fabric Administrator to align with the changing scope and responsibility of this role. All applications including Azure Active Directory, Microsoft Graph APIs, Microsoft 365, and GDAP will start to reflect the new role name gradually.”
Probably the most obvious reason (based on true own lived experience), was that I had to deal with some Office365 administrators who inherited full Power BI Tenants administrator roles and privileges “per interim” with no other background formation than a Power BI in A Day session. That’s about it. As a result, all Data analytics members in my teams and I were totally blocked access to all workspaces resources and options for no given founded logical reason.
Instead of requesting assistance from true expertise in the fields, Office365 administrators -now turned
Power BI Tenants administrators – rather opted to take the easy shortcut pulling all access options switch to OFF. There was nothing we could do about it but file redundant rejected requests.
As an Azure Architect consultant I had been given a limited 3 months time scope mandate to build whole Power BI collaboration infrastructure project demo which a whole IT team of programmers had not managed to complete in over 18+ months including reporta and dashboards dynamic embedding options in applications. So that left me no other option than to start building the new project demo on separate independent AAD Tenant to which I had control I needed. It couldn’t have been achieved otherwise. Project was finally completed in time and presented to head administration who were pleased with result and extended mandates with higher privileges. So IMHO lending full Microsoft Fabric monopoly access control into wrong hands with no valid basic formation could have drastic consequences. I hope this will give a good occasion to do a bit of cleanup. Anyway
Happy Coding & Take Care
Andres
Does Fabric support loading on-prem SQL tables to a Fabric Datawarehouse or Lakehouse via a gen Dataflow or Pipeline (or other method)? I created a gen Dataflow with on-prem. SQL table, but cannot seem to be able to populate a lakehouse or datawarehouse
Pulendar
Seems like Data Engineers, Data Analysts & Data Scientists will be replaced by Fabric consultants 😉
John
This looks super expensive compared to Synapse today particularly for Serverless or Spark users and compared to Databricks or Snowflake. The Fabric trial is F128 which is $16k per month and yet only includes 128 Spark cores vs the 400+ you can easily get your hands on in Synapse and doesn’t appear to offer meaningful better performance at the CU128 level vs serverless or DW1000c dedicated pool, much less Snowflake where you are only paying for actual query time…
K Sharma
Brilliant article, thank you!!
Deborah
WOW! Awesome post. Something for everyone learning about Fabric.
Nikola
Thanks Deborah, glad to hear that!