

With amounts of data growing exponentially in the last few years, one of the biggest challenges became finding the most optimal way to store various data flavors. Unlike in the (not so far) past, when relational databases were considered the only way to go, organizations now want to perform analysis over raw data – think of social media sentiment analysis, audio/video files, and so on – which usually couldn’t be stored in a traditional (relational) way, or storing them in a traditional way would require significant effort and time, which increase the overall time-for-analysis.
Another challenge was to somehow stick with a traditional approach to have data stored in a structured way, but without the necessity to design complex and time-consuming ETL workloads to move this data into the enterprise data warehouse. Additionally, what if half of the data professionals in your organization are proficient with, let’s say, Python (data scientists, data engineers), and the other half (data engineers, data analysts) with SQL? Would you insist that “Pythonists” learn SQL? Or, vice-versa?
By the way, if you want to learn how to query the data from Parquet files using Azure Synapse Analytics, I get you covered!
Or, would you prefer a storage option that can play to the strengths of your entire data team? I have good news for you – something like this already exists since 2013 and it’s called Apache Parquet!
Parquet file format in a nutshell!
Before I show you ins and outs of the Parquet file format, there are (at least) five main reasons why Parquet is considered a de-facto standard for storing data nowadays:
- Data compression – by applying various encoding and compression algorithms, Parquet file provides reduced memory consumption
- Columnar storage – this is of paramount importance in analytic workloads, where fast data read operation is the key requirement. But, more on that later in the article…
- Language agnostic – as already mentioned previously, developers may use different programming languages to manipulate the data in the Parquet file
- Open-source format – meaning, you are not locked with a specific vendor
- Support for complex data types
Row-store vs Column-store
We’ve already mentioned that Parquet is a column-based storage format. However, to understand the benefits of using the Parquet file format, we first need to draw the line between the row-based and column-based ways of storing the data.
In traditional, row-based storage, the data is stored as a sequence of rows. Something like this:
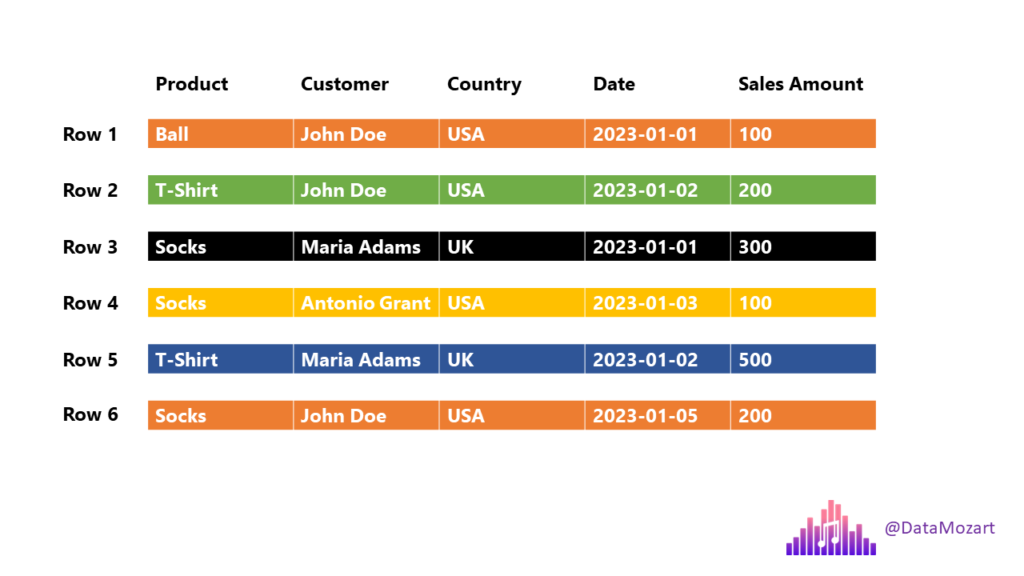
Now, when we are talking about OLAP scenarios, some of the common questions that your users may ask are:
- How many balls did we sell?
- How many users from the USA bought T-Shirt?
- What is the total amount spent by customer Maria Adams?
- How many sales did we have on January 2nd?
To be able to answer any of these questions, the engine must scan each and every row from the beginning to the very end! So, to answer the question: how many users from the USA bought T-Shirt, the engine has to do something like this:
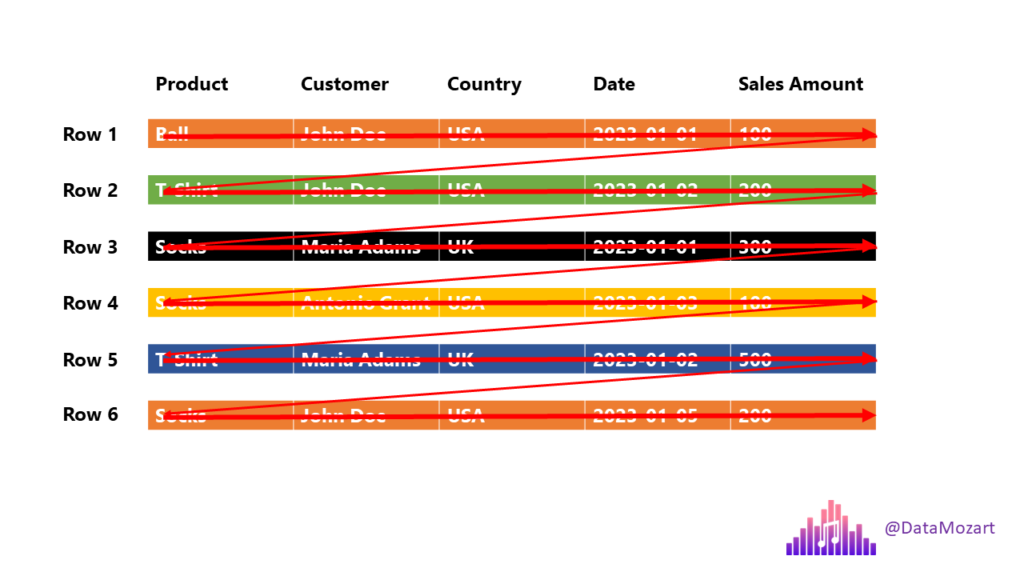
Essentially, we just need the information from two columns: Product (T-Shirts) and Country (USA), but the engine will scan all five columns! This is not the most efficient solution – I think we can agree on that…
Column store
Let’s now examine how the column store works. As you may assume, the approach is 180 degrees different:
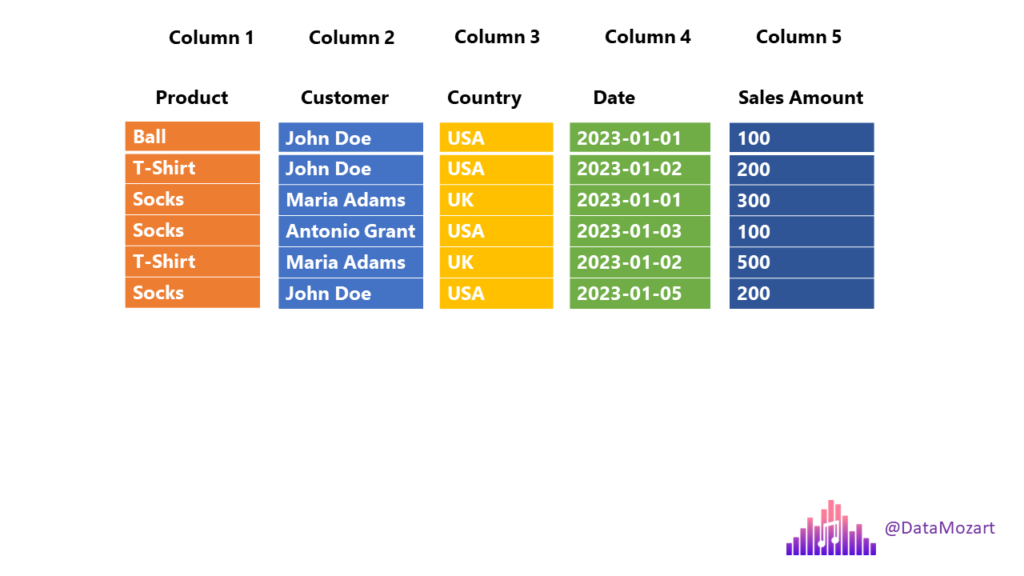
In this case, each column is a separate entity – meaning, each column is physically separated from other columns! Going back to our previous business question: the engine can now scan only those columns that are needed by the query (Product and country), while skipping scanning the unnecessary columns. And, in most cases, this should improve the performance of the analytical queries.
Ok, that’s nice, but the column store existed before Parquet and it still exists outside of Parquet as well. So, what is so special about the Parquet format?
Parquet is a columnar format that stores the data in row groups!
Wait, what?! Wasn’t it enough complicated even before this? Don’t worry, it’s much easier than it sounds:)
Let’s go back to our previous example and depict how Parquet will store this same chunk of data:
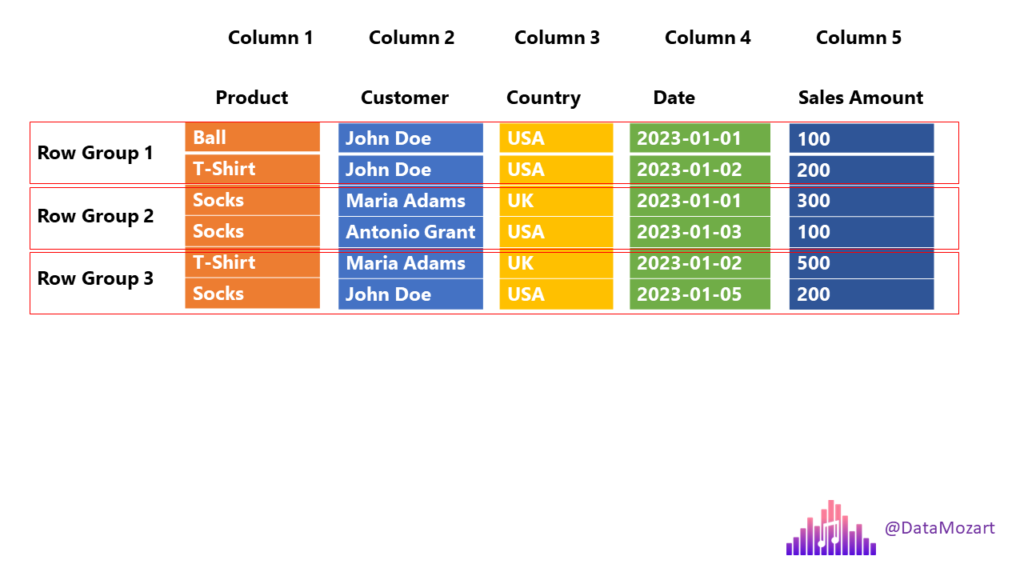
Let’s stop for a moment and explain the illustration above, as this is exactly the structure of the Parquet file (some additional things were intentionally omitted, but we will come soon to explain that as well). Columns are still stored as separate units, but Parquet introduces additional structures, called Row group.
Why is this additional structure super important?
You’ll need to wait for an answer for a bit:). In OLAP scenarios, we are mainly concerned with two concepts: projection and predicate(s). Projection refers to a SELECT statement in SQL language – which columns are needed by the query. Back to our previous example, we need only the Product and Country columns, so the engine can skip scanning the remaining ones.
Predicate(s) refer to the WHERE clause in SQL language – which rows satisfy criteria defined in the query. In our case, we are interested in T-Shirts only, so the engine can completely skip scanning Row group 2, where all the values in the Product column equal socks!
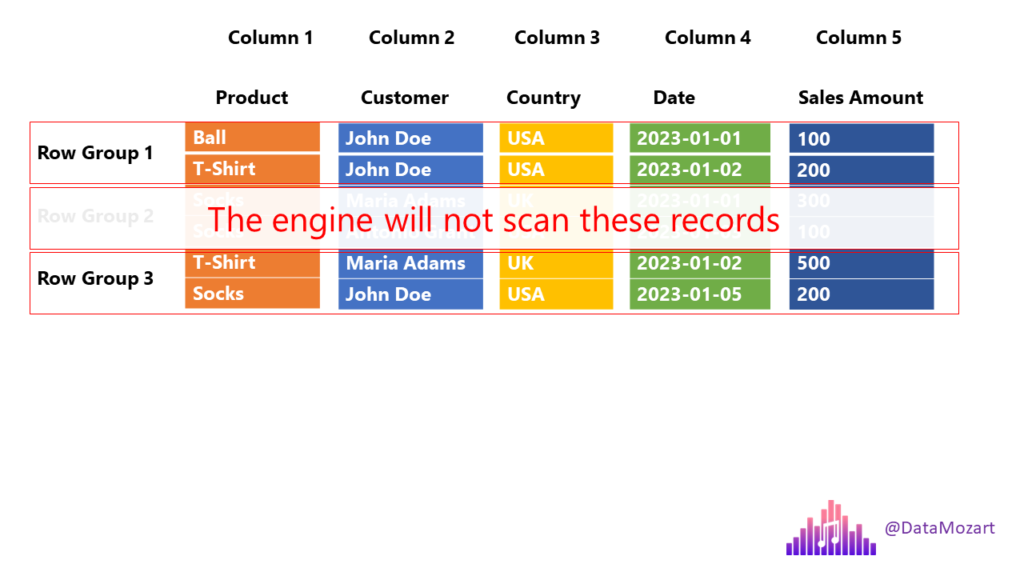
Let’s quickly stop here, as I want you to realize the difference between various types of storage in terms of the work that needs to be performed by the engine:
- Row store – the engine needs to scan all 5 columns and all 6 rows
- Column store – the engine needs to scan 2 columns and all 6 rows
- Column store with row groups – the engine needs to scan 2 columns and 4 rows
Obviously, this is an oversimplified example, with only 6 rows and 5 columns, where you will definitely not see any difference in performance between these three storage options. However, in real life, when you’re dealing with much larger amounts of data, the difference becomes more evident.
Now, the fair question would be: how Parquet “knows” which row group to skip/scan?
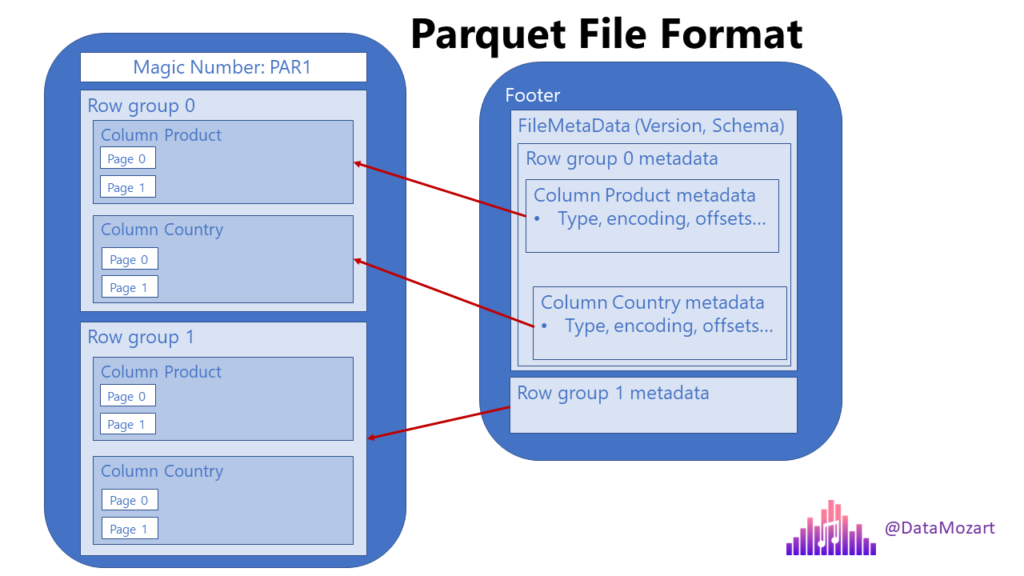
Parquet file contains metadata!
This means, every Parquet file contains “data about data” – information such as minimum and maximum values in the specific column within the certain row group. Furthermore, every Parquet file contains a footer, which keeps the information about the format version, schema information, column metadata, and so on. You can find more details about Parquet metadata types here.
Important: In order to optimize the performance and eliminate unnecessary data structures (row groups and columns), the engine first needs to “get familiar” with the data, so it first reads the metadata. It’s not a slow operation, but it still requires a certain amount of time. Therefore, if you’re querying the data from multiple small Parquet files, query performance can degrade, because the engine will have to read metadata from each file. So, you should be better off merging multiple smaller files into one bigger file (but still not too big:)…
I hear you, I hear you: Nikola, what is “small” and what is “big”? Unfortunately, there is no single “golden” number here, but for example, Microsoft Azure Synapse Analytics recommends that the individual Parquet file should be at least a few hundred MBs in size.
What else is in there?
Here is a simplified, high-level, illustration of the Parquet file format:
Can it be better than this? Yes, with data compression
Ok, we’ve explained how skipping the scan of the unnecessary data structures (row groups and columns) may benefit your queries and increase the overall performance. But, it’s not only about that – remember when I told you at the very beginning that one of the main advantages of the Parquet format is the reduced memory footprint of the file? This is achieved by applying various compression algorithms.
I’ve already written about various data compression types in Power BI (and the Tabular model in general) here, so maybe it’s a good idea to start by reading this article.
There are two main encoding types that enable Parquet to compress the data and achieve astonishing savings in space:
- Dictionary encoding – Parquet creates a dictionary of the distinct values in the column, and afterward replaces “real” values with index values from the dictionary. Going back to our example, this process looks something like this:

You might think: why this overhead, when product names are quite short, right? Ok, but now imagine that you store the detailed description of the product, such as: “Long arm T-Shirt with application on the neck”. And, now imagine that you have this product sold million times…Yeah, instead of having million times repeating value “Long arm…bla bla”, the Parquet will store only the Index value (integer instead of text).
- Run-Length-Encoding with Bit-Packing – when your data contains many repeating values, Run-Length-Encoding (RLE) algorithm may bring additional memory savings.
Can it be better than THIS?! Yes, with the Delta Lake file format
Ok, what the heck is now a Delta Lake format?! This is the article about the Parquet, right?
So, to put it in plain English: Delta Lake is nothing else but the Parquet format “on steroids”. When I say “steroids”, the main one is the versioning of Parquet files. It also stores a transaction log, to enable keeping the track of all changes applied to the Parquet file. This is also known as ACID-compliant transactions.
Since it supports not only ACID transactions, but also supports time travel (rollbacks, audit trails, etc.) and DML (Data Manipulation Language) statements, such as INSERT, UPDATE and DELETE, you won’t be wrong if you think of the Delta Lake as a “data warehouse on the data lake” (who said: Lakehouse😉😉😉). Examining the pros and cons of the Lakehouse concept is out of the scope of this article, but if you’re curious to go deeper into this, I suggest you read this article from Databricks.
Conclusion
We evolve! Same as we, the data is also evolving. So, new flavors of data required new ways of storing it. The Parquet file format is one of the most efficient storage options in the current data landscape, since it provides multiple benefits – both in terms of memory consumption, by leveraging various compression algorithms, and fast query processing by enabling the engine to skip scanning unnecessary data.
Thanks for reading!
P.S. If you are working with Azure Data Lake Gen2, you can leverage Azure Synapse Analytics Serverless SQL pool for querying the data stored in Parquet files, as explained here.

Last Updated on March 20, 2024 by Nikola



Darin
Thanks for putting your time into introducing these concepts. I created my first Lakehouse (is not working for me but that’s just me figuring it out as I go) and am really thankful for people like you!
Antony
Best explanation of Parquet I have read Nikola. Thanks
Nikola
Thanks Antony!
Bing
Totally agree that this is the best explanation of Parquet so far I have found in the internet. Thanks Nikola. Like your work.
Nikola
Thank you very much, glad that you find it useful!
Alexandre Dantas
Thank you very much, what a wonderful way to explain
Shayan
birlliant
Swapnil
Superb Explanation Nikola! Thanks so much!
rxt
if you can explain a layman in a simple plain English, you are a true educator. I think you just did that here!!! Great article
Su W
Best explanation I have read! Thanks!
Nikola
Thank you!
Rajesh Ratakonda
Thank you very much for the detailed explanation on multiple topics. Really appreciate the effort you have put in and sharing the knowledge .
qgeff
Should already explain how sorting with row group help pruning the row group
Steve T
Great article. I’m curious, what determines the contents of a row group? Is it always 2 rows per group? Is it always sequential rows? Or is there some algorithm to optimize the contents?
Nikola
Thanks Steve. As per Parquet official docs: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
To answer your question: no, there are definitely not 2 rows per group, it’s much more than that. I used this example with 2 rows in my case to demonstrate the file structure, but in reality the recommended size of the froup is 512 MB to 1 GB (that’s really many rows:))
Hope this helps
Kamala
Very Good one to get an idea on Parquet files.