

Have you ever wondered what makes Power BI so fast and powerful when it comes to performance? So powerful, that it performs complex calculations over millions of rows in a blink of an eye.
In this series of articles, we will dig deep to discover what is “under the hood” of Power BI, how your data is being stored, compressed, queried, and finally, brought back to your report. Once you finish reading, I hope that you will get a better understanding of the hard work happening in the background and appreciate the importance of creating an optimal data model in order to get maximum performance from the Power BI engine.
As you might recall, in the previous article we scratched the surface of VertiPaq, a powerful storage engine, which is “responsible” for blazing-fast performance of most of your Power BI reports (whenever you are using Import mode or Composite model).
3, 2, 1…Fasten your seatbelts!
One of the key characteristics of the VertiPaq is that it’s a columnar database. We learned that columnar databases store data optimized for vertical scanning, which means that every column has its own structure and is physically separated from other columns.

That fact enables VertiPaq to apply different types of compression to each of the columns independently, choosing the optimal compression algorithm based on the values in that specific column.
Compression is being achieved by encoding the values within the column. But, before we dive deeper into a detailed overview of encoding techniques, just keep in mind that this architecture is not exclusively related to Power BI – in the background is a Tabular model, which is also “under the hood” of SSAS Tabular and Excel Power Pivot.
Value Encoding
This is the most desirable value encoding type since it works exclusively with integers and, therefore, require less memory than, for example, when working with text values.
How does this look in reality? Let’s say we have a column containing a number of phone calls per day, and the value in this column varies from 4.000 to 5.000. What the VertiPaq would do, is to find the minimum value in this range (which is 4.000) as a starting point, then calculate the difference between this value and all the other values in the column, storing this difference as a new value.
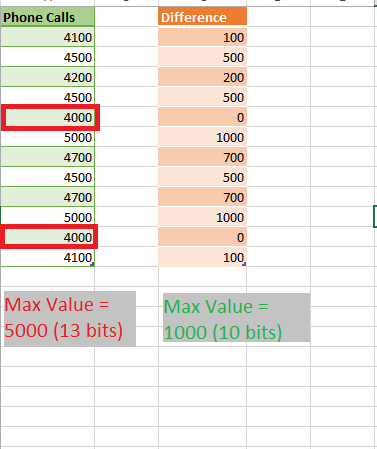
At first glance, 3 bits per value might not look like a significant saving, but multiply this by millions or even billions of rows and you will appreciate the amount of memory saved.
As I already stressed, Value Encoding is being applied exclusively to integer data type columns (currency data type is also stored as an integer).
Hash Encoding (Dictionary Encoding)
This is probably the most used compression type by a VertiPaq. Using Hash encoding, VertiPaq creates a dictionary of the distinct values within one column and afterward replaces “real” values with index values from the dictionary.
Here is the example to make things more clear:
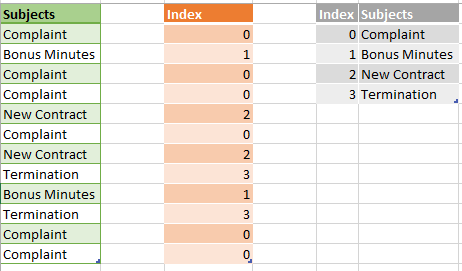
As you may notice, VertiPaq identified distinct values within the Subjects column, built a dictionary by assigning indexes to those values, and finally stored index values as pointers to “real” values. I assume you are aware that integer values require way less memory space than text, so that’s the logic behind this type of data compression.
Additionally, by being able to build dictionary for any data type, VertiPaq is practically data type independent!
This brings us to another key takeover: no matter if your column is of text, bigint or float data type – from VertiPaq perspective it’s the same – it needs to create a dictionary for each of those columns, which implies that all these columns will provide the same performance, both in terms of speed and memory space allocated! Of course, by assuming that there are no big differences between dictionary sizes between these columns.
So, it’s a myth that the data type of the column affects its size within the data model. On the opposite, the number of distinct values within the column, which is known as cardinality, mostly influence column memory consumption.
RLE (Run-Length-Encoding)
Third algorithm (RLE) creates kind of mapping table, containing ranges of repeating values, avoiding to store every single (repeated) value separately.
Again, taking a look at an example will help to better understand this concept:
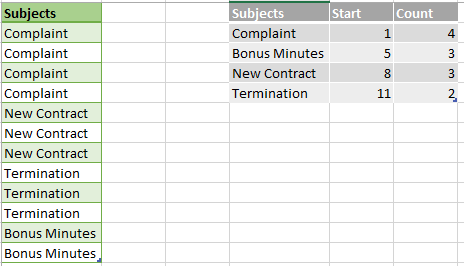
In real life, VertiPaq doesn’t store Start values, because it can quickly calculate where the next node begins by summing previous Count values.
As powerful as it might look at first glance, the RLE algorithm is highly dependent on the ordering within the column. If the data is stored the way you see in the example above, RLE will perform great. However, if your data buckets are smaller and rotate more frequently, then RLE would not be an optimal solution.
One more thing to keep in mind regarding RLE: in reality, VertiPaq doesn’t store data the way it is shown in the illustration above. First, it performs Hash encoding and creating a dictionary of the subjects and then apply RLE algorithm, so the final logic, in its most simplified way, would be something like this:
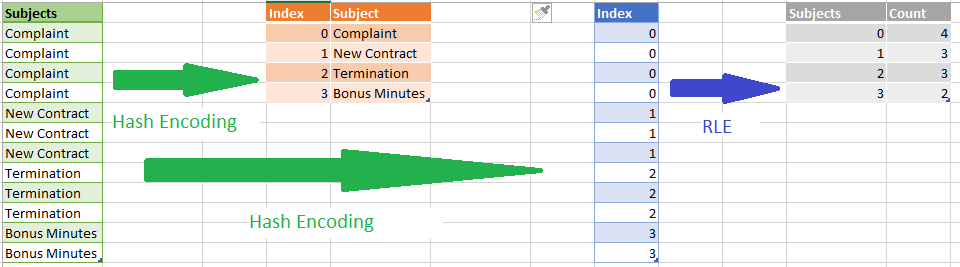
So, RLE occurs after Value or Hash Encoding, in those scenarios when VertiPaq “thinks” that it makes sense to compress data additionally (when data is ordered in that way that RLE would achieve better compression).
Re-Encoding considerations
No matter how “smart” VertiPaq is, it can also make some bad decisions, based on incorrect assumptions. Before I explain how re-encoding works, let me just briefly iterate through the process of data compression for a specific column:
- VertiPaq scans sample of rows from the column
- If the column data type is not an integer, it will look no further and use Hash encoding
- If the column is of integer data type, some additional parameters are being evaluated: if the numbers in sample linearly increase, VertiPaq assumes that it is probably a primary key and chooses Value encoding
- If the numbers in the column are reasonably close to each other (number range is not very wide, like in our example above with 4.000-5.000 phone calls per day), VertiPaq will use Value encoding. On the contrary, when values fluctuate significantly within the range (for example between 1.000 and 1.000.000), then Value encoding doesn’t make sense and VertiPaq will apply the Hash algorithm
However, it can happen sometimes that VertiPaq makes a decision about which algorithm to use based on the sample data, but then some outlier pops-up and it needs to re-encode the column from scratch.
Let’s use our previous example for the number of phone calls: VertiPaq scans the sample and chooses to apply Value encoding. Then, after processing 10 million rows, all of a sudden it found 50.000 value (it can be an error, or whatever). Now, VertiPaq re-evaluates the choice and it can decide to re-encode the column using the Hash algorithm instead. Surely, that would impact the whole process in terms of time needed for reprocessing.
Conclusion
In this part of the series on the “brain & muscles” behind Power BI, we dived deep into different data compression algorithms which VertiPaq performs in order to optimize our data model.
Finally, here is the list of parameters (in order of importance) that VertiPaq considers when choosing which algorithm to use:
- Number of distinct values in the column (Cardinality)
- Data distribution in the column – column with many repeating values can be better compressed than one containing frequently changing values (RLE can be applied)
- Number of rows in the table
- Column data type – impacts only dictionary size
In the next article, I will introduce some techniques for reducing data model size and consequentially getting the better overall performance of your Power BI report.
Last Updated on July 21, 2020 by Nikola



Power BI: Data Model Optimization – Data on Wheels – Steve & Kristyna Hughes
[…] External Resources:https://data-mozart.com/inside-vertipaq-compress-for-success/https://github.com/AnytsirkGTZ/TimeTable_MCode/blob/main/MQuery%20Time […]
Power BI: Data Model Optimization from Blog Posts – SQLServerCentral - The web development company
[…] External Resources:https://data-mozart.com/inside-vertipaq-compress-for-success/https://github.com/AnytsirkGTZ/TimeTable_MCode/blob/main/MQuery%20Time%5B1%5D%5B2%5D […]
Power BI: Making Date & Time Keys – Data on Wheels – Steve & Kristyna Hughes
[…] External Resources:https://data-mozart.com/inside-vertipaq-compress-for-success/https://github.com/AnytsirkGTZ/TimeTable_MCode/blob/main/MQuery%20Time […]
Creating a Timetable Fact Table from a Schedule - Shetland Data
[…] rows will be 500 times the number of scheduled activities. Still a tool like Power BI should still make quick work of this. Again this query uses the prior as the […]
Rohit Y
Very nicely explained … Thanks Nikola