
TL; DR: No, data lakehouse is not all we need! But, it’s an extremely important concept to understand, especially in the modern data landscape…
In the previous parts of the Data Modeling for mere mortals series, we examined traditional approaches to data modeling, with a focus on dimensional modeling and Star schema importance for business intelligence scenarios. Now, it’s time to introduce the concept of the modern data platform.
As usual, let’s take a more tool-agnostic approach and learn about some of the key characteristics of the modern data estate. Please, don’t mind if I use some of the latest buzzwords related to this topic, but I promise to reduce their usage as much as possible.
History lessons (again)…
Ok, let’s start with some history lessons and introduce a short history of data architectures.
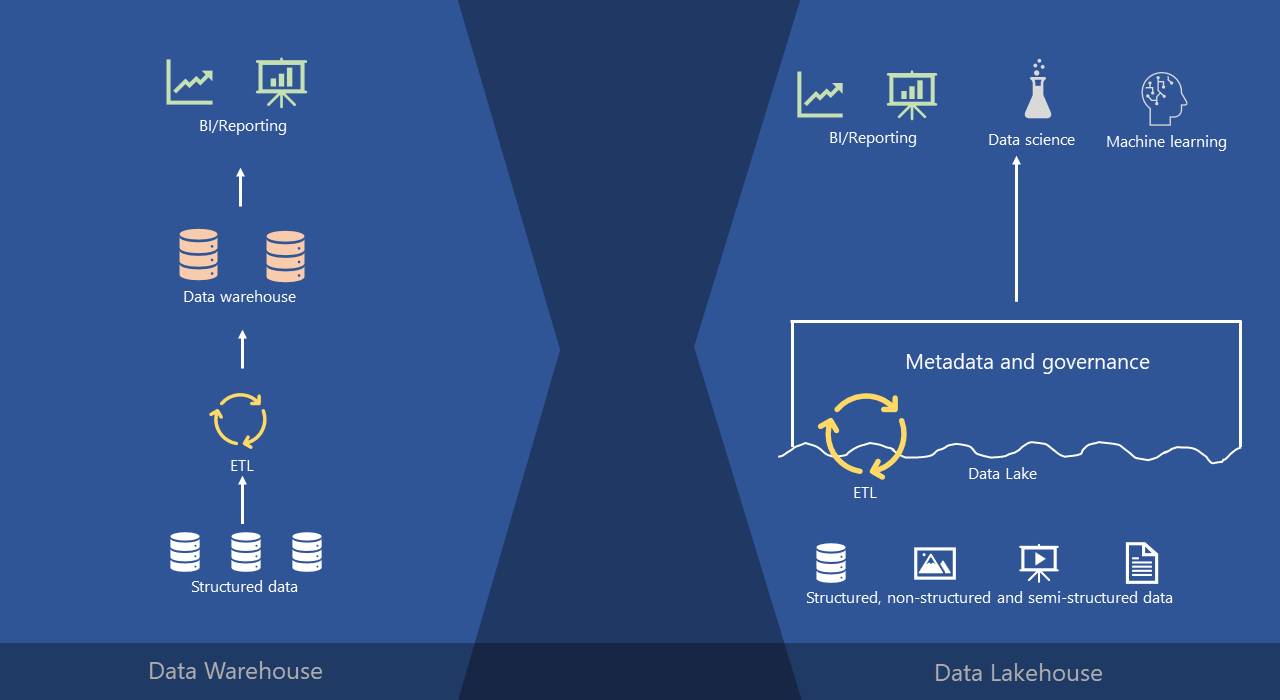
We’ll kick it off with Data warehouses. Data warehouses, as you’ve already learned in the previous article, have a long history in decision support and business intelligence systems, being around for decades. They represent a mature and well-established architecture for handling huge amounts of structured data. And, this is a typical workflow in traditional enterprise data warehousing architecture:
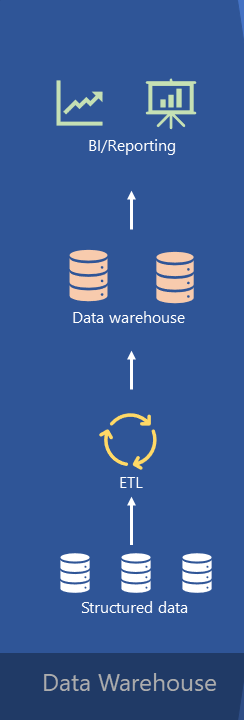
So, we connect to the structured data stored in various source systems – let’s say transactional databases, then we perform some transformations on this data to shape it in a form that is suitable for analytic workloads – doing things like data cleaning, filtering, and so on – before we load it into a central repository, which is an enterprise data warehouse.
These enterprise data warehouses were, and still are, the focal point of the architecture – a single source of truth for all your organizational data. From there, we are using various business reporting tools, such as Crystal Reports (yes, I’m that old), SSRS, Power BI, of course, if we’re talking about Microsoft’s reporting solutions (and, don’t forget good old Excel too), creating all kinds of different reports to support efficient business decision making. A specific group of people, who are proficient in understanding and using SQL language, could also connect and query the data directly from the data warehouse, by leveraging other client tools, such as SSMS or Azure Data Studio.
However, times are changing. Not that I want to say that traditional data warehousing solutions are dead – on the contrary – but, let’s say that they needed to evolve to support new flavors of data.
In recent years, organizations acquire more and more data that’s originating outside of structured, transactional databases. Things like social media data, images, videos, logs, information collected from IoT devices, and so on…Which is hardly manageable using traditional data warehousing solutions. So, we are talking about semi-structured and non-structured data.
So, how do we handle these new flavors of data?
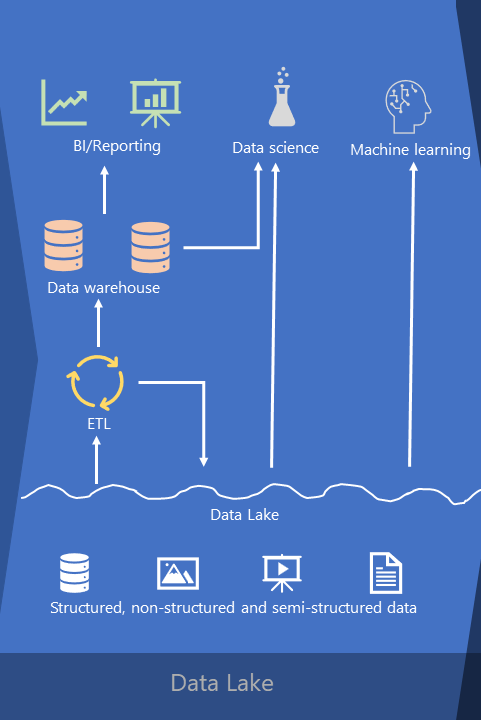
We simply store them “as-is” in the data lake. A data lake can be used for storing all data types – structured, semi-structured and non-structured. From there, again, we can perform our ETL operations to populate the enterprise data warehouse and this part of the architecture looks exactly the same as in the previous case.
However, it’s not only about different data flavors. It’s also about new roles in data space – individuals like data scientists or machine learning engineers, people responsible for providing predictive analytics over all data types, not only those residing in the data warehouse! These “new kids on the block” had to respond to business questions in a whole different way compared to what we used to know previously. Therefore, by providing them with access over raw data stored in the data lake, we got a whole new architectural concept in place.
Not only that! Please pay attention to the arrow ETL-> Data Lake. ETL process is not a one-way street anymore – meaning, it’s not populating only an enterprise data warehouse, but also a data lake itself! So, essentially, we have two data storage locations here – a traditional, enterprise data warehouse, but also an organizational data lake.
Things become a little complicated, right?
Obviously, we needed, or at least some of the folks around thought that we needed, a more flexible and less complex solution.
And that’s when the latest concept was introduced.
It’s called: DATA LAKEHOUSE!
What else? I mean, if you combine warehouse and lake, what else you may expect than lakehouse, right? Before we proceed to explain what is a lakehouse, you might be wondering who was the “godfather” of this concept. Credit goes to Databricks, as they were the first to introduce the concept with this name.
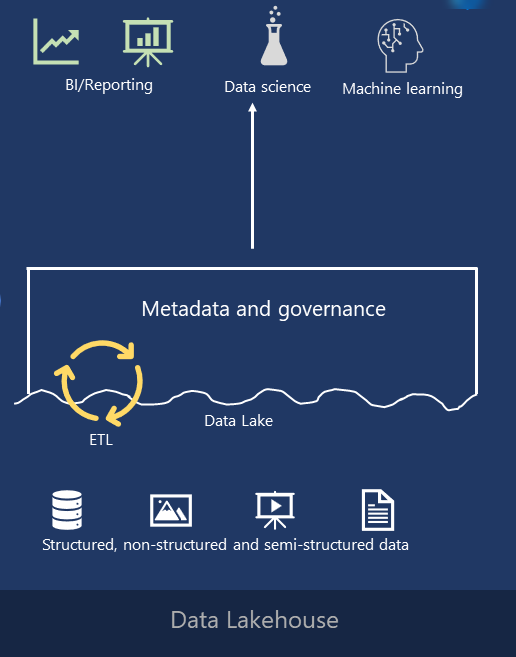
If I’d to explain a data lakehouse in one sentence, that would be: a data lakehouse is conceptually the same as data warehouse – the only difference is that in traditional data warehouse data is stored within files on the disk (using vendor-specific proprietary formats), whereas in data lakehouse data is stored within files in the data lake (using open Delta format).
But, why lakehouse? And, what are the benefits of having a solution like this? Well, you may notice that this part at the bottom is exactly the same – we have our structured, semi-structured and non-structured data, and we store it again in the data lake.
However, instead of physically moving the data from the data lake to the data warehouse, by introducing a metadata and governance layer directly on the data lake, plus performing all the ETL stuff within the lake itself, we are getting the best from both worlds!
What does this “best from both worlds” mean in real life?
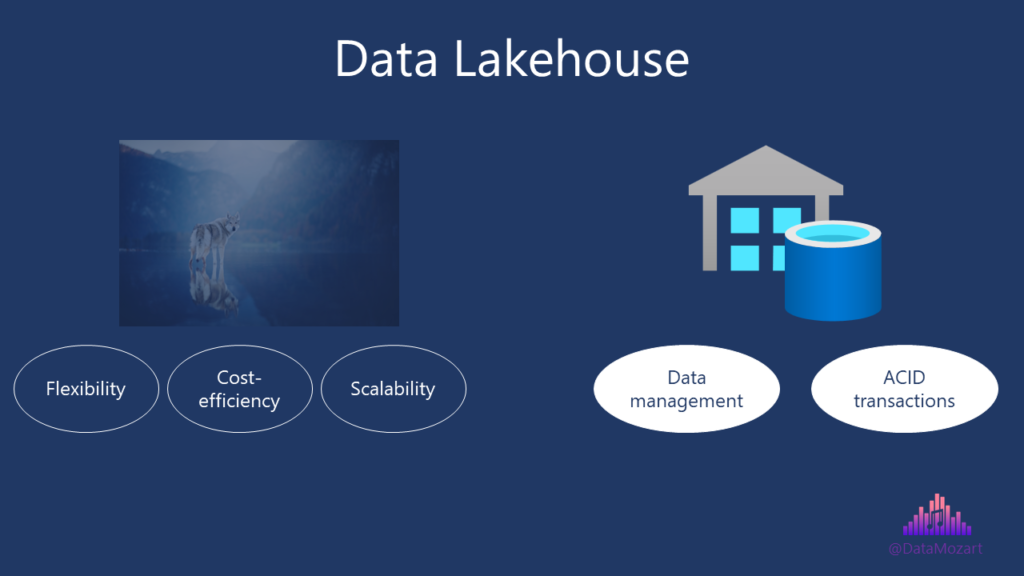
On the one hand side, we have flexibility, cost-efficiency, and scalability of the data lakes. On the other side, we can leverage features such as data management and ACID transactions, that are at the core of traditional data warehousing architecture.
The main benefit of this new, hybrid architecture, is that various data teams can perform faster, without needing to access and consume the data from multiple systems. Additionally, by eliminating the need for physically moving the data, data lakehouse architecture enables all the teams across the organization – data analysts, data scientists, and ML engineers – to have the latest and most complete data available.
No matter how it sounds fancy and cool, you have to be aware of the specific prerequisites that enabled rise of the data lakehouse concept:
- Metadata layers – for example, an open-source Delta lake file format, that supports transaction logging and ACID-compliant transactions. This metadata layer also supports streaming I/O, time travel between the table versions, schema enforcement, etc.
- Performance – with enterprise data warehouses, you could have always relied on the performance aspect, because of their powerful engines and other features that enable performance optimization. When we are talking about data lakes, in the past, it was really slow to access objects in the data lake. Now, with these new engines, such as Polaris engine in Microsoft Fabric, or Photon in Databricks, you can write SQL queries and quickly retrieve the data stored in the lake
- Accessibility for data scientists/ML engineers – Don’t forget, folks in data scientist and machine learning engineer roles are usually super proficient with Python, Spark and similar technologies, but they are not SQL gurus. So, exposing the data from the data lake directly to them, while giving them the possibility to continue using their tools, is another strong argument for implementing a data lakehouse architecture
Data Lakehouse Key Features
Let’s briefly examine all the key features of this emerging new concept. Or, what makes this architecture a successful implementation.
- Transaction support – In an enterprise lakehouse, many data pipelines will often read and write data concurrently. Support for ACID transactions ensures consistency as multiple parties concurrently read or write data, typically using SQL
- Schema enforcement and governance - The Lakehouse should offer a way to support schema enforcement and evolution, supporting DW schema architectures such as star/snowflake-schemas. The system should be able to implement data integrity, and it should have robust governance and auditing mechanisms
- BI support - Lakehouses enable using BI tools directly on the source data. This reduces staleness and improves recency, reduces latency, and lowers the cost of having to operationalize two copies of the data in both a data lake and a warehouse
- Storage is decoupled from compute - In practice this means storage and compute use separate clusters, thus these systems are able to scale to many more concurrent users and larger data sizes. Many modern data warehouses (Microsoft Fabric, Databricks, Snowflake) also have this property
- Openness - The storage formats they use are open and standardized, such as Parquet, and they provide an API so a variety of tools and engines, including machine learning and Python/R libraries, can efficiently access the data directly
- Support for diverse data types ranging from unstructured to structured data – The lakehouse can be used to store, refine, analyze, and access data types needed for many new data applications, including images, video, audio, semi-structured data, and text
- Support for diverse workloads - including data science, machine learning, and SQL and analytics. Multiple tools might be needed to support all these workloads but they all rely on the same data repository
- End-to-end streaming – Real-time reports are the norm in many enterprises. Support for streaming eliminates the need for separate systems dedicated to serving real-time data applications
These are the key attributes of lakehouses. Of course, enterprise grade systems require additional features, such as tools for security and access control, data governance including auditing, retention, and lineage, tools that enable data discovery such as data catalogs and data usage metrics, just to name a few…
With a lakehouse, all these enterprise features only need to be implemented, tested, and managed for a single system, instead for multiple systems previously, which also reduces the overall architecture complexity.
Conclusion
We evolve! Same as we, the data is also evolving. So, new flavors of data required new ways of storing it. And, let’s be honest, by introducing Fabric, which is a lake-centric solution, Microsoft, as the biggest “player” on the market, also confirmed that the concept of the data lakehouse became de-facto standard in modern data architecture.
The key question you’re probably asking yourself at this point is: do we ALL need a data lakehouse, right here, right now? The short answer is: NO! The long answer is: HELL, NOOOOO!!! If you already invested in building an enterprise data warehouse and have a working solution based on traditional data warehousing principles, or if you’re dealing with structured data only, and your data team consists of SQL professionals, don’t fall into the trap of marketing and hype – you simply don’t need a lakehouse!
If you’re just starting your data platform modernization journey, you might consider implementing data lakehouse architecture, because of the smooth and more straightforward collaboration between different data teams within the organization (and other reasons as well). I’ll cover this in the separate series of articles that will focus on Microsoft Fabric as the platform of choice for implementing a lakehouse solution.
In the final part of this series, we’ll discuss a special data modeling technique relevant for data lakehouse scenarios – medallion architecture.
Thanks for reading!

Last Updated on October 27, 2023 by Nikola



Jaywant Thorat
Great article, Nikola Ilic! The concept of a data lakehouse is gaining a lot of buzz in the industry, and your post beautifully outlines its significance. The easy-to-understand description and thought-provoking questions have definitely piqued my curiosity. Can’t wait to dive into this series and uncover more insights. Keep up the excellent work! 👏
Nikola
Thank you Jaywant!
Donald Parish
“perform some transformations on this data to shape it in the form that is suitable for analytic workloads – doing things like aggregations, and so on – before we load it into a central repository, which is an enterprise data warehouse.” The “aggregations” are not really part of shaping data for analysis. Kimball would say keep atomic detailed data, with “aggregations” being done in the BI tool, or as a performance optimization. Otherwise, if we aggregate too soon, like rolling up sales to week level, we won’t be able to do Day level analysis.
Nikola
Good catch Donald! Poor phrasing from my side, just edited that part of the article. Thanks a lot!