
In recent years, I’ve done dozens of training on various data platform topics, for all kinds of audiences. When teaching various data platform concepts and techniques, I find one of the concepts particularly intimidating for many business analysts, especially those who are just starting their journey. And, that is the concept of data modeling.
Why is data modeling sometimes intimidating?
Maybe because you feel lost when you see all these diagrams that look so complex and complicated…
But, data modeling is not about diagrams. It’s about creating trust, a shared understanding between the business and data professionals, with the final goal of providing increased business value with data.
If we agree that data modeling is about creating trust, I believe we can also agree that trust can’t be easily built – a certain amount of time and effort should be taken into consideration. And, time and effort are not something that you take for granted – it’s something that you need to INVEST!
So, we can rightly assume that data modeling is a kind of investment. An investment that should bring more stability and adaptability to your business.
Think of it like investing in building a house.

Obviously, you can choose to go the quick and easy way, by simply putting building blocks directly on the ground – and it can possibly work just fine for some time – until some new circumstances occur – think about an earthquake or thunderstorm for example. And, your house will probably be damaged. But, it’s not only the house that’s going to be damaged – your trust will also be damaged – people who live with you, your neighbors, friends…Will realize that you didn’t invest the proper amount of time and effort in advance, to prevent such a bad scenario.
Now, let’s assume that you decided to take another path – more demanding at the very beginning, which will require more time and effort from your side. You established a proper foundation for the house, secured things under the ground, and then built a house on top of it. Now, your house will be more stable and can adapt to future challenges.

Since we explained why it is of paramount importance to invest time and effort in building a data model, let’s now examine various types of data models and how they fit into the big data modeling picture.
Conceptual Data Model
Usually, the starting point is creating a conceptual data model. This is a high-level, let’s say, 10.000 feet high perspective on the business needs for data. As we are talking about the high-level perspective, the main goal of the conceptual data model is to simplify business processes and entities important in day-to-day business workflow.
In this stage, we are compiling a big picture: what are the key entities in our business workflow? How do they correlate with each other? The key characteristic of the conceptual data model is that it should communicate in easy-to-understand terms. Simply said, leverage a common language that business users and non-technical individuals can easily understand.
I know I told you that data modeling is not about diagrams, but still, we need to visualize the process of creating a data model. I’ll first give you a basic example of the conceptual data model.
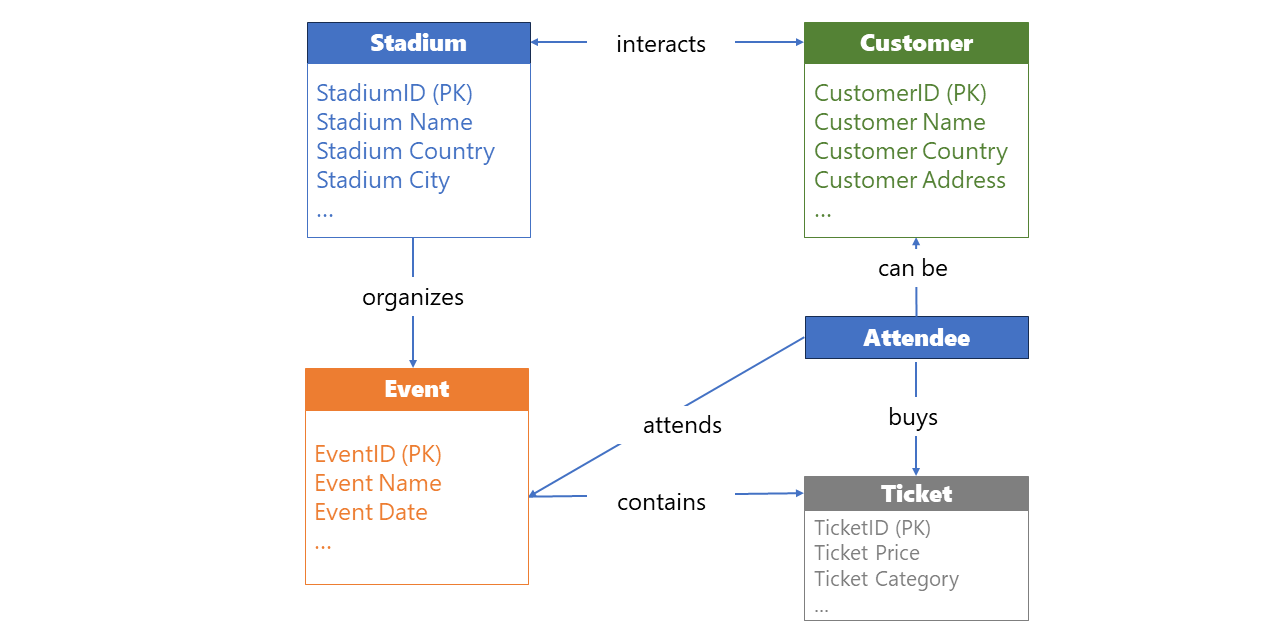
In this illustration, you can identify various entities. Stadium, Event, Customer, Attendee, and Ticket. You may also notice how these entities are interconnected. This high-level overview provides a simplified picture of the business workflow within the organization.
Now, let’s move on and explain in common language what we see in this illustration.
Our first entity is Stadium. Stadium has a name and is located in a specific country and city, which uniquely identifies that stadium. Stadium may host many events, and there can be many attendees coming to these events.
Next, we have an Event. A specific event cannot exist outside of the Stadium where it is scheduled to be held. An event can be attended by an attendee, and there can be many attendees for one event.
Attendee is the entity that attends the event. They can also be a customer of the Stadium entity, in case they’ve visited a stadium shop, or similar. The key difference between the Customer and Attendee is that the Customer doesn’t necessarily need to attend a specific event at the stadium.
Customer may have a relation to Stadium, like I said, for example by visiting a stadium museum or buying at a stadium fan shop, but that doesn’t make them attendees of the event.
Finally, a Ticket is an entity that represents confirmation that the attendee will attend a specific event. Each ticket has a unique identifier, as it would be really awkward if two or more attendees get the ticket with the same number. Although the ticket is uniquely identified, one attendee can purchase multiple tickets.
Why do we need a conceptual data model?
Now that we’ve explained the core components of conceptual data modeling, you might be wondering: Why is this important? Why should someone spend time and effort describing all the entities and relations between them?
Remember when we were talking about building trust between business and data personas? That’s what the conceptual data model is all about. Ensuring that business stakeholders will get what they need, explained in a common language so that they can easily understand the entire workflow. Setting up a conceptual data model also provides business stakeholders with the possibility to identify a whole range of business questions that need to be answered before building a physical data model.
Some of the questions business may ask are: are the customer and attendee the same entity (and why they are not)? Can one attendee buy multiple tickets? What uniquely identifies a specific event? And, many more, of course…
Additionally, the conceptual data model depicts sometimes very complex business processes in an easier-to-consume way. Instead of going through pages and pages of written documentation, one can take a look at the illustration of entities and relationships, all explained in a user-friendly way, and quickly understand the core elements of the business process.
Logical Data Model
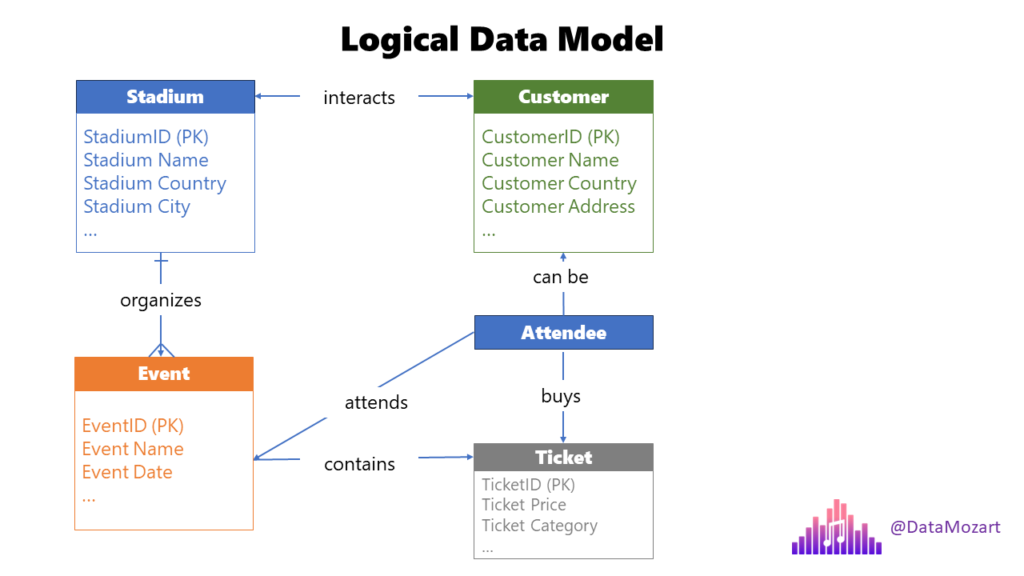
Once business and data teams align on the conceptual data model, the next step in the data modeling process is designing a logical data model. In this stage, we are building upon the previous step, by identifying the exact structure of the entities and providing more details about the relationships between these entities. In this stage, you should identify all the attributes of interest for the specific entity, as well as relationship cardinality.
Please pay attention that, same as during the conceptual data modeling phase, we still don’t talk about the specific platform or solution. Like in the previous stage, our focus is on understanding business requirements and how these requirements can be efficiently translated into data model.
There are several steps to be performed to ensure that the conceptual data model successfully evolved into a logical data model.
- Identify entity attributes
- Identify candidate keys – find out which attribute, or set of attributes, uniquely identify a specific entity
- Choose primary keys – based on the findings from the previous step, set the primary key of the entity
- Apply normalization/denormalization to the data model – we’ll discuss normalization and denormalization in more detail in one of the next articles. At this moment, keep in mind that normalization should eliminate data redundancy and is typical for OLTP systems. On the other hand, denormalization is predominantly used in analytical systems, or OLAP, to minimize the impact of JOIN operations and speed up data reading
- Set relationships between entities – validate how various entities interconnect and, if needed, reduce the complexity of having multiple relationship dependencies, by breaking down one entity into multiple entities
- Identify the relationship cardinality – another extremely important step. Relationship cardinality defines how many instances of one entity are related to instances of another entity. There are three main cardinality types: one-to-one (1:1) one-to-many (1:M) and many-to-many (M:M)
- Iterate and fine-tune – in real life, it’s almost impossible to find the data model that suits everyone’s needs and fulfills all the requirements immediately. Therefore, it’s of key importance to always ask for feedback from business stakeholders and, based on the feedback received, fine-tune the logical data model, before materializing it in physical form
Why do we need a logical data model?
Unlike the conceptual data model, where the benefits of investing time and effort in building it were not so obvious, I believe that for the logical data model, potential gains are more evident. First of all, the logical data model serves as the best quality assurance test, because it can enclose gaps and issues in understanding the business workflow, thus saving you a lot of time and effort down the road. It’s much easier and less costly, to fix these issues at this stage, before locking into a specific platform and building an inefficient physical data model on it.
As we’ve already mentioned, one of the key characteristics of a good logical data model is that iteration and fine-tuning are continuous processes. Therefore, building a logical data model can be considered part of the agile data modeling cycle, which ensures more robust, scalable, and future-proof models.
The ultimate benefit of the logical data model is that it serves as a blueprint for the final implementation of the business logic through the physical data model. Relying on a well-designed logical data model enables database engineers and data architects to create more efficient physical database systems.
Physical Data Model
A physical data model represents that final touch – how the data model will be implemented in the specific database. Unlike conceptual data model and logical data model, which are platform and solution-agnostic, physical implementation requires defining low-level detail that may be specific for the certain database provider.
Transitioning from a logical data model to a physical data model requires more iterations and fine-tuning of the entities and relationships defined in the logical data model.

The same as for logical data model, there is a whole list of necessary steps to make your data model implementation success, so let’s focus on the most important ones:
- Choose the platform – this is a step that you can’t skip, because this decision will shape your future design principles
- Translate logical entities into physical tables – the logical entity is just that – a logical entity, and it exists on a more abstract level. Since a real database doesn’t support that level of abstraction, we need to translate that entity into a physical unit. This means, we need to provide information to the underlying platform on how the data should be stored – in simple words, define the data type of each entity attribute – be it a whole number, decimal number, or plain text. Additionally, each physical table should rely on keys to ensure data integrity – and it’s your task during the physical data modeling process to set primary, foreign, and unique keys.
- Establish relationships – based on the key columns, the next step in the physical data modeling workflow is to create relationships between the tables.
- Apply normalization/denormalization – similar to what we’ve already examined in the logical data modeling phase, check and confirm that tables are, depending if you’re designing a transactional or analytical system, normalized or denormalized to a degree that ensures the most efficient workload for the specific system – don’t forget, in OLTP systems, tables should be normalized (in most scenarios) to a 3rd normal form to reduce data redundancy, and efficiently support WRITE operations (insert, update), while in OLAP systems data may be denormalized to eliminate the number of joins, to make READ operations more performant
- Define table constraints – there are dozen of constraints that you may apply to ensure data integrity. It’s not only about the keys, which we’ve already mentioned previously, but also other logical checks. I’ll give you a simple example: let’s imagine that your table contains a column that stores the data about students’ grades in college. Can a student be graded with a grade 100? Or 1000? Or 1? Of course not! There is a finite list of possible grades, in the range of 5 to 10 (or A to F in some other systems). So, why not define this constraint on the column, thus preventing the insertion of values that don’t make sense – be it due to an error, or by leaving the end user possibility to enter whatever they want?
- Create indexes and/or partitions – indexes and partitions are special physical data structures that “reside” within a table, and their main goal is to increase the efficiency of the data model. Explaining indexes and table partitioning is out of the scope of this article, but keep in mind that both these features may significantly affect the performance of your data model – both for good and bad! It’s fair to say, especially for indexes, that implementing an efficient indexing strategy is mastery on its own. Table partitioning represents a technique of splitting one big table into multiple smaller “sub-tables”, thus helping the database engine to reduce the scanning time during the query execution. A good example would be partitioning per calendar periods, let’s say years. Instead of keeping all the records in one huge, multi-million, or multi-billion row table, you can split this table and create multiple smaller “sub-tables” containing records for the specific year. Don’t be confused when I say “sub-tables” – these are not “real” new tables in your data model – everything is happening behind the scenes and it’s just the way the data is physically structured under the surface
- Extend with programmatic objects – almost every database management system will let you create various programmatic objects, such as stored procedures, functions, or triggers. Explaining each of these objects is out of the scope of this article, and they all serve different purposes and help you efficiently complete various tasks. However, their implementation is “de-facto” standard in almost every data platform solution, and it’s hard to find any OLTP or OLAP system which doesn’t rely on these objects
Why do we need a physical data model?
With all points mentioned previously, the main benefit of having a physical data model in place is to ensure efficiency, optimal performance, and scalability. When we talk about efficiency, we are obviously having in mind the two most precious business assets – time and money. Unless you think that time = money, then we have only one asset to consider…

To simplify – the more efficient your data model is, the more users it can serve, the more faster can serve them, which in the end in most cases brings more money to the business.
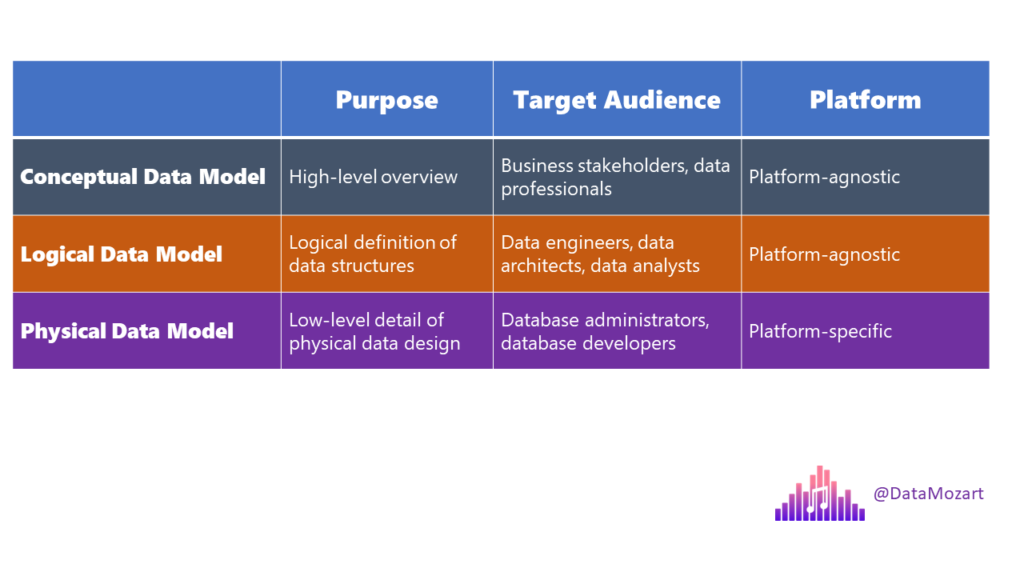
Side-by-side comparison
Here is a brief overview of the key characteristics of each of the data model types:
Conclusion
I want you to remember three key things about data modeling:
- Never ever underestimate the importance of the data modeling process and designing a proper data model! Can you “sneak” without it? Of course, you can…But, same as with our example with the house, without a solid foundation, it’s a matter of time before you’ll start scratching your head
- Saving time and effort to avoid building an efficient data model will create a technical debt that will cause investing much more time and resources to deal with it at a later stage
- Always model the data with business in mind! Designing a data model for the sake of having one in place, or using a pre-defined “universal data modeling” template, doesn’t make any sense if that model is not capable of answering key business questions
In the next part of the series, we’ll examine the wonderful world of dimensional data modeling…
Thanks for reading!

Last Updated on October 27, 2023 by Nikola



Olivier LN
Great great great! As usual. I might extract so part as introduction for my younger colleagues!
Nikola
Thanks a lot Olivier!
Rani
As always, easy-to-digest guides are written by you !!
Nikola
Thank you Rani!
Amit M
Explained very well. Thanks for sharing.