Choosing optimal indexing strategy for your SQL Server workloads is one of the most challenging tasks. As you probably know, indexes can dramatically improve the performance of your queries, but at the same time, they can cause additional overhead when it comes to maintenance.
In complete honesty, I would never call myself an expert on indexing. However, I wanted to share my experience from the recent project, as it opened a whole new perspective to me and I thought that it can be beneficial to others also.
First of all, up until a few months ago, I have never used Columnstore indexes, since the working environment in my company was based on SQL Server 2008R2. I’ve had theoretical knowledge about Columnstore indexes and I was aware of the difference between them and traditional B-Tree indexes, but I’ve never tried them in reality.
But, first things first…
What is a Columnstore index ?
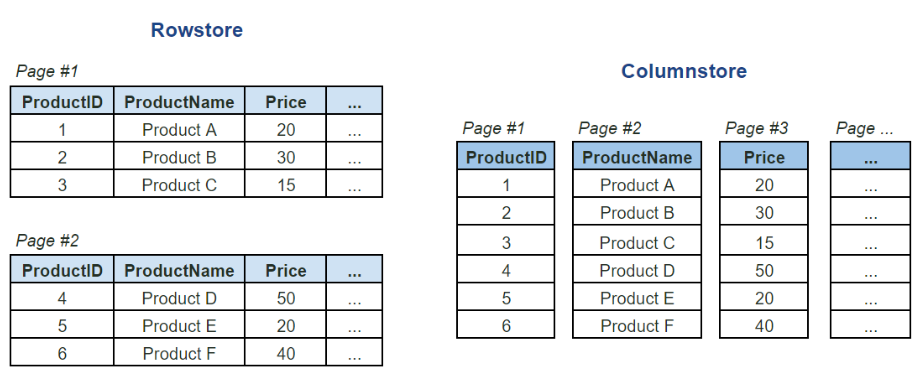
As opposed to a rowstore type of data storage, which physically stores data in a row-wise format, columnstore operates on a columnar level of the table. It was first introduced with SQL Server 2012 and later improved with every newer version of SQL Server. While traditional rowstore indexes (I will refer them as B-tree indexes) store the key value of each row, so that the SQL Server engine can use this key to retrieve the row data, columnstore indexes store each table column separately!
The main reason for using the Columnstore index is its high compression! That brings significant gains in terms of memory footprint and, consequentially, better performance when used in a proper way.
There are really a lot of great resources on the web for learning about Columnstore indexes architecture, and Microsoft’s documentation is also quite comprehensive on this topic, but I wanted to show on some real examples when the usage of Columnstore indexes makes sense.
Just to emphasize that I will use clustered columnstore indexes exclusively (non-clustered columnstore indexes are out of the scope of this article).
For all examples, I’m using Stack Overflow database.
Climbing on a B-tree
Let’s first run a few simple queries on our Posts table, which has slightly more than 17 million records, just to get a feeling about the data. At the very beginning, I don’t have any indexes on this table, except the clustered index on the primary key column.
My goal is to find all posts from the 1st half of year 2010, with more than 3000 views:
SELECT * FROM dbo.Posts P WHERE CreationDate >= '20100101' AND CreationDate < '20100701' AND ViewCount > 3000
This query returned 88.547 rows and it took more than a minute to execute!
Since no index exists on this table, SQL Server had to scan a whole table to satisfy our request, performing around 4.2 million logical reads. Let’s help a little bit our poor SQL Server, and create a nonclustered index on CreationDate column:
CREATE NONCLUSTERED INDEX [ix_creationDate] ON [dbo].[Posts] ( [CreationDate] ASC )
Now, when I ran again exactly the same query, I’ve got back my results in 9 seconds, but the number of logical reads (5.6 million) suggests that this query is still far from being good. SQL Server is thankful for our new index since it was used to narrow down the scope for the initial search. However, selecting all columns is obviously not a good idea, as SQL Server had to pick up all other columns from the clustered index, performing an enormous number of random readings.
Now, the first question I would ask myself is: what data do I really need? Do I need Body, ClosedDate, LastEditDate, etc.? Ok, so I will rewrite the query to include only necessary columns:
SELECT P.Id AS PostId ,P.CreationDate ,P.OwnerUserId AS UserId ,P.Score ,P.ViewCount FROM dbo.Posts P WHERE P.CreationDate >= '20100101' AND P.CreationDate < '20100701' AND P.ViewCount > 3000
We are getting exactly the same execution plan, with less logical reads (4 million), since the amount of data that’s being returned was decreased.
SQL Server suggests creating an index on our predicate columns (columns in WHERE clause), and including remaining columns in the index. Let’s obey SQL Server’s wish and modify our index:
CREATE NONCLUSTERED INDEX [ix_creationDate_viewCount] ON [dbo].[Posts] ( [CreationDate], [ViewCount] ) INCLUDE ([OwnerUserId],[Score])
Now, when I run my query, it executes in less than a second, performing only 3626 logical reads! Wow! So, we’ve created a nice “covering” index, which works perfectly for this query. I’ve intentionally bolded the part “for this query”, since we can’t create covering index for every single query that runs against our database. Here, it’s fine for the demo purposes.
Columnstore index comes into play
Ok, we couldn’t optimize the previous query more than we did. Let’s now see how will columnstore index performs.
The first step is to create a copy of dbo.Posts table, but instead of using B-tree index, I will create a clustered columnstore index on this new table (dbo.Posts_CS).
CREATE CLUSTERED COLUMNSTORE INDEX cix_Posts ON dbo.Posts_CS
First thing you may notice is the huuge difference in the memory footprint of these two identical tables:
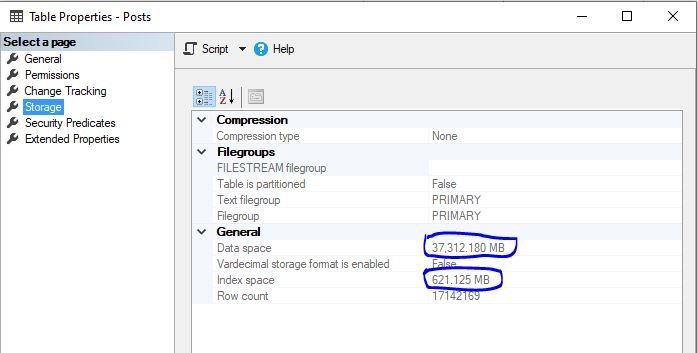
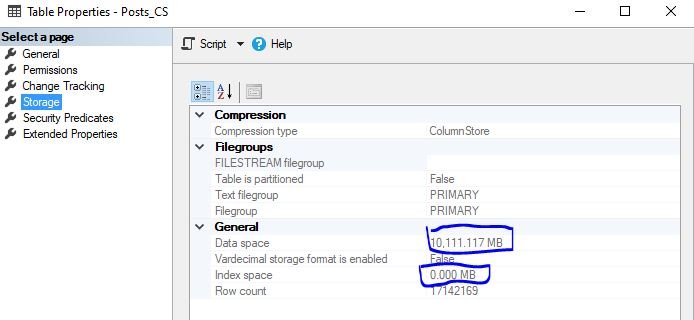
So, table with clustered columnstore index on it, consumes almost 4x less memory comparing to an original one with B-tree index! If we also take non-clustered indexes into consideration, the difference only gets bigger. As I’ve already mentioned, data is much better compressed on the column level.
Now, let’s run exactly the same query on our newly created columnstore indexed table.
SELECT P.Id AS PostId ,P.CreationDate ,P.OwnerUserId AS UserId ,P.Score ,P.ViewCount FROM dbo.Posts_CS P WHERE P.CreationDate >= '20100101' AND P.CreationDate < '20100701' AND P.ViewCount > 3000
Data in columnstore index is stored in segments. So, depending on the data distribution within the table, SQL Server has to read more or less segments in order to retrieve the requested data.

As you can see in the above illustration, to return my 88.547 records, SQL Server went through 26 segments and skipped 72. That’s because the data in our columnstore index is not sorted in any specific order. We could sort it by, let’s say, CreationDate (assuming that most of our queries will use CreationDate as a predicate), and in that case performance should be even better, since SQL Server would exactly know in which segments to look for the data, and which could be skipped.
Now, let’s run both queries together and compare the query costs:
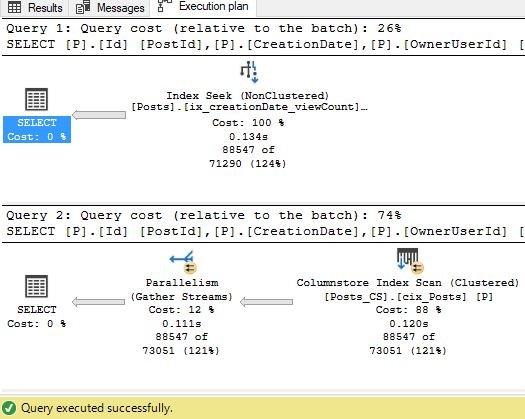
Traditional B-tree index seek has cost of 3.7, while columnstore scan costs 10.7. Quite obvious, since we have perfectly matching non-clustered index that covers all columns we need. Still, the difference is not so big.
Adding more ingredients…
But, let’s say that after some time we need to expand our output list and retrieve data for LastActivityDate. Let’s check what will happen:
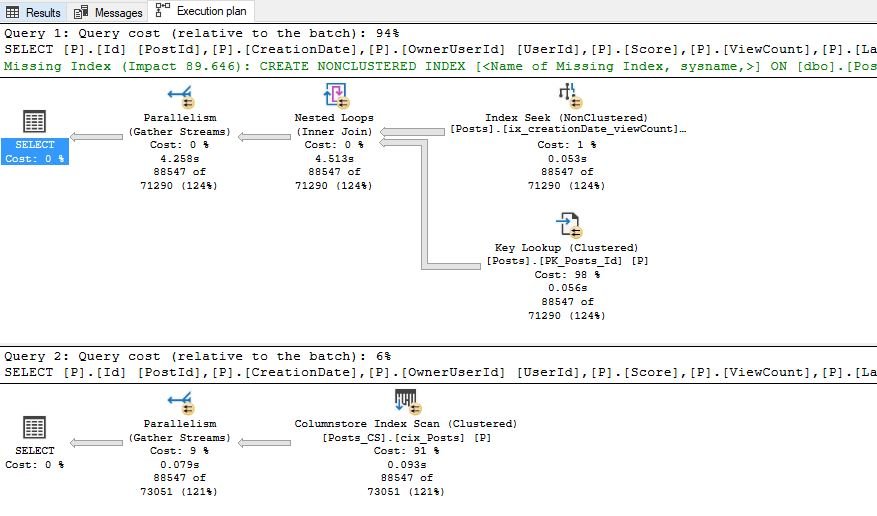
Oops!!! By adding just one column, results completely changed in the favor of columnstore index. Now, B-tree non-clustered index doesn’t have all necessary data and it needs to pick up LastActivityDate from the clustered index – that makes the cost of this query rise up to 236! On the other hand, columnstore index became slightly more expensive and now costs 14!
Of course, as you can notice in the picture above, SQL Server asks for another index (or existing one to be expanded), but that’s what I stressed above – you shouldn’t blindly obey all of SQL Server wishes, or you will finish with “overindexed” tables!
Running Analytical Queries
By definition, the area where columnstore indexes should excel is when running analytical queries. So, let’s check this on the following scenario: I want to retrieve the users who registered in the first half of year 2010, posted in the years 2010 and 2011, and the user’s overall Reputation is greater than 3000 and respective posts have more than 3000 views…I also need to see the user’s Location and DisplayName. Sounds complicated, but it really isn’t:)
Here is the query:
SELECT U.Id ,U.Location ,U.DisplayName ,P.CreationDate ,P.Score ,P.ViewCount FROM dbo.Users U INNER JOIN dbo.Posts P ON U.Id = P.OwnerUserId WHERE U.CreationDate >= '20100101' AND U.CreationDate < '20100701' AND U.Reputation > 3000 AND P.ViewCount > 3000 AND P.CreationDate >= '20100101' AND P.CreationDate < '20120101'
The query returns 37.332 rows and we want to help SQL Server a little bit, by creating a non-clustered index on CreationDate column in the Users table.
CREATE NONCLUSTERED INDEX [ix_creationDate] ON [dbo].[Users] ( [CreationDate] )
When I run the query, SQL Server comes with the following execution plan:
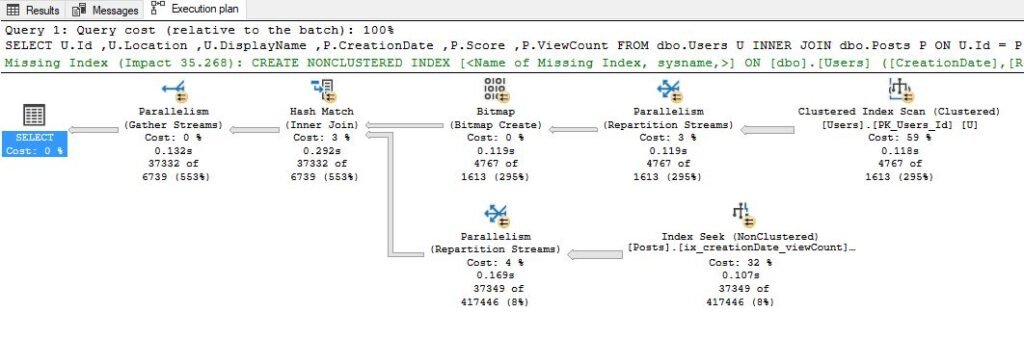
Since our index doesn’t cover all the necessary columns, SQL Server assumes that it’s cheaper to perform a scan on the Users table, instead of doing Index Seek and then expensive key lookups. This query costs 58.4.
Now, I will create copy of the Users table (Users_CS) and create a clustered columnstore index on it:
CREATE CLUSTERED COLUMNSTORE INDEX cix_Users ON dbo.Users_CS
Let’s now run bot of our queries at the same time and compare the performance:
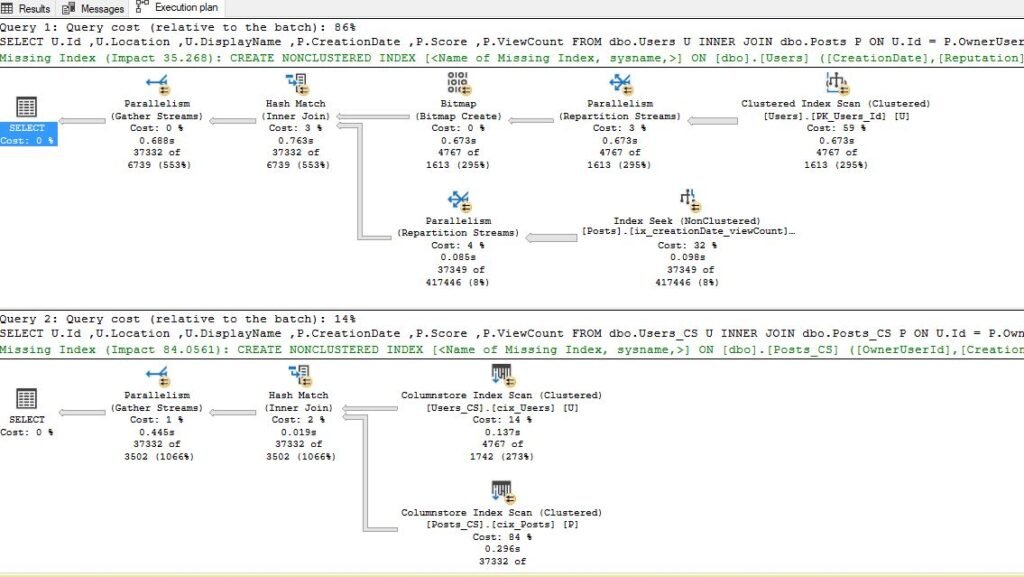
Again, the table with columnstore index on it, easily outperforms the original one with the B-tree index. The cost of the second query is 9.2! And keep in mind that we didn’t even optimize the columnstore index itself (we were not sorting the data during the insertion)!
One last example comes from my real project, where we were comparing performance between columnstore and B-tree indexes on our actual workload. The query itself is so simple: I want to summarize total deposits per every single customer between January 1st and end of July this year:
SELECT customerID ,SUM(amount) total FROM factDeposit WHERE isSuccessful = 1 AND datetm >='20200101' AND datetm < '20200801' GROUP BY customerID SELECT customerID ,SUM(amount) total FROM factDeposit_cs WHERE isSuccessful = 1 AND datetm >='20200101' AND datetm < '20200801' GROUP BY customerID
And here are the results:
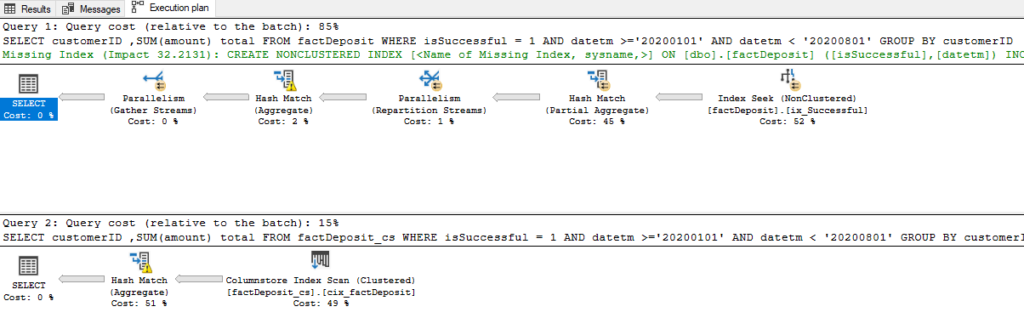
Again, columnstore index convincingly “wins” with 4.6 vs 26 query cost!
So, why would I use B-tree indexes at all??!!
Before you fall into the trap of concluding that traditional B-tree indexes aren’t needed anymore, you should ask yourself: where is the catch? And the catch is obviously there, since B-tree indexes are still heavily used in most of the databases.
The biggest downside of the columnstore indexes is UPDATE/DELETE operations. Deleted records are not really deleted – they are just flagged as deleted, but they still remain part of the columnstore index, until the index is rebuilt. Updates perform even worse, since they are being executed as two consecutive actions: delete and then insert…Inserts “per se” are not an issue, because SQL Server keeps them in the structure called Deltastore (which, by the way, has B-tree structure), and performs a bulk load into the columnstore index.
Therefore, if you are often performing updates and/or deletes, be aware that you will not extract maximum benefit from the columnstore index.
So, the right question should be:
WHEN should I use B-tree indexes, and WHEN columnstore idexes?
The answer is, as in 99% cases within SQL Server debates – IT DEPENDS!
Finding the appropriate workload
The key challenge is to identify the scenario, or better say the workload, that suits best to the usage of columnstore vs rowstore indexes.
Here are some recommendations for best practice usage for each of the index types:
- Use columnstore indexes on large tables (with at least a few million records), that are not being updated/deleted frequently
- Columnstore indexes perform best on static data, such as in OLAP workloads, with a lot of queries that simply reads the data from the tables, or bulk loading new data periodically
- Columnstore indexes excel in scanning and performing aggregations on big data ranges (doing SUM, AVG, COUNT, etc), because they are able to process around 900 rows in one batch, while traditional B-tree index process one-by-one (up until SQL Server 2019, which added a batch mode for row-based workload)
- Use B-tree indexes on highly transactional workloads, when your table is being frequently modified (updates, deletes, inserts)
- B-tree indexes will usually perform better in queries with high selectivity, for example, when you are returning a single value, or small number of values, or if you are querying small range of values (SEEKing for a value)
To say that you should use columnstore indexes in OLAP workloads, while using B-tree indexes in OLTP environment, will be huge oversimplifying. In order to get the proper answer to this question, you should ask yourself: what kind of queries are mostly used for the specific table? As soon as you get the answer to this question, you will be able to define the proper indexing strategy for your own workload.
And, finally, in case you wonder if you can take the best from both worlds: the answer is – YES! Starting from SQL Server 2016, you can combine columnstore and traditional B-tree indexes on the same table!
That’s, however, separate and complex topic that requires serious planning and various considerations, which is out of the scope of this article.
Thanks for reading!
Last Updated on August 12, 2020 by Nikola