

To be honest: I like SQL Server! I truly admire what this “guy” does for all of us and how it handles all of our (weird) ideas. He is capable of producing awesome query plans in a blink of an eye, calculating bunch of stuff in the background. But, as any other “guy”, he also has his own flaws.
I will use “Stack Overflow” database to demonstrate some interesting things. I believe that there is no “techies” around who haven’t used Stack Overflow at least once (per day, haha). Their database structure is quite simple, but at the same time is “real”, unlike Adventure Works, WWI and similar semi-prepared solutions from Microsoft. Best of all, SO database holds tables with millions of records, which is good for testing some real-life cases.
Goal – find specific users
Our goal is to find all SO users which have more than certain number of upvotes (we’ll look for users with more than 100, 1000 and 10000 upvotes). This is plain simple query, but can be “salted” enough to force SQL Server rethinking.
First of all, let’s create an index which will help our query:
create index ix_UpVotes on dbo.Users (UpVotes);
Then, we will turn on statistics for IO:
set statistics io on;
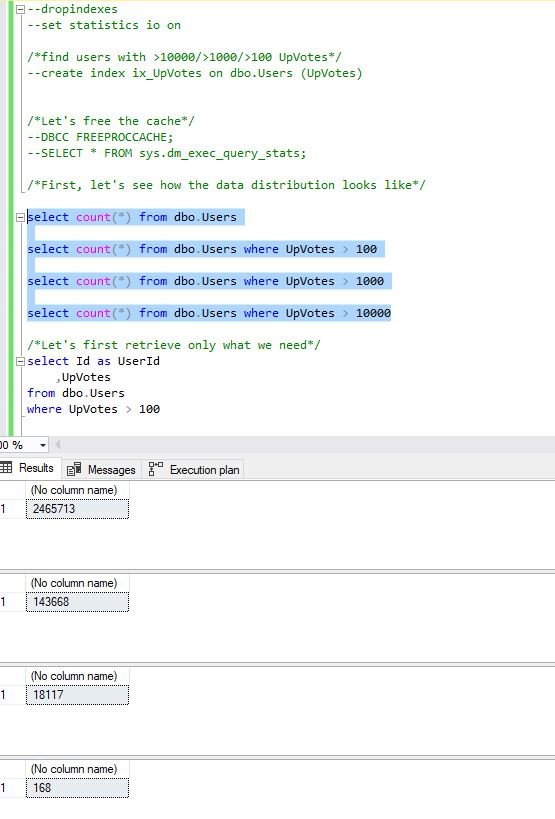
Before I run the query, I try to see how the data distribution looks like within specific table/column. Therefore, I’m running following set of commands to see how many records exist for any of the goals I want to achieve (remember, we want to see all users with more than 100, 1000 and 10000 upvotes):
select count(*) from dbo.Users;
GO
select count(*) from dbo.Users where UpVotes > 100;
GO
select count(*) from dbo.Users where UpVotes > 1000;
GO
select count(*) from dbo.Users where UpVotes > 10000;
GO
We are getting following numbers:
Now, we can finally run our query:
select Id as UserId
,UpVotes
from dbo.Users
where UpVotes > 100;
GO
select Id as UserId
,UpVotes
from dbo.Users
where UpVotes > 1000;
GO
select Id as UserId
,UpVotes
from dbo.Users
where UpVotes > 10000;
GO
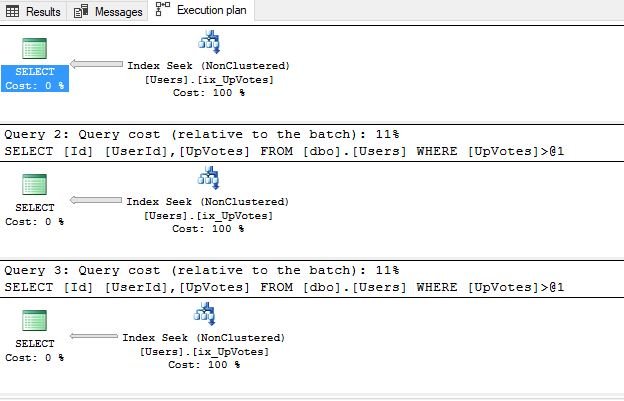
Of course, SQL Server is smart enough to use non-clustered index we previously created. It does nice and sweet Index Seek operation, which is obvious when we look at query statistics:
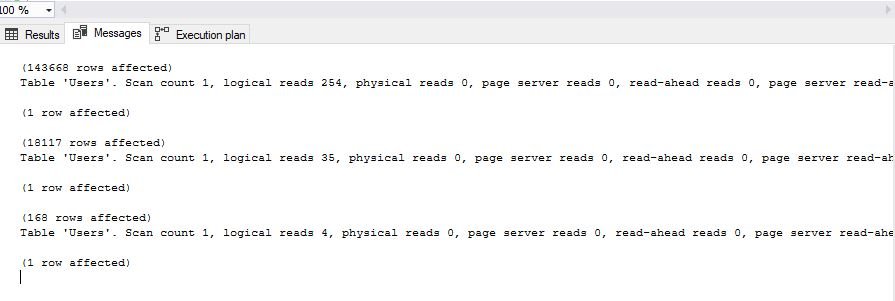
Small number of logical reads means that SQL Server didn’t have to push hard to retrieve the data we requested. It goes directly to specific pages.
Adding more ingredients
But…what will happen if we wanted to retrieve, beside User’s ID and number of her/his upvotes, also date when the user created an account at Stack Overflow. Let’s check this:
/*Now, let's include Creation Date in SELECT*/
/*Look at statistics and query plans*/
select Id as UserId
,UpVotes
,CreationDate
from dbo.Users
where UpVotes > 100;
GO
select Id as UserId
,UpVotes
,CreationDate
from dbo.Users
where UpVotes > 1000;
GO
select Id as UserId
,UpVotes
,CreationDate
from dbo.Users
where UpVotes > 10000;
GO

Aha…Now, SQL Server created two different query plans: for the first two queries (go get me users with more than 100 and more than 1000 upvotes), SQL Server assumes that it is cheaper for him to do a Clustered Index Scan (which is basically scanning entire 2.5 million rows table), while for the most selective case (users with more than 10000 upvotes), he prefers doing an Index Seek and then performing Key Lookup and adding CreationDate from the clustered index.
Statistics shows that first two queries are quite exhaustive, since SQL Server performs around 45.000 logical reads. To be honest, for the first query I expected full table scan. It retrieves approx. 6% of all records (143.668 out of 2.5 million). But, for the second query, I believed that SQL Server will use Index Seek (18.117 records out of 2.5 million), same as in the last scenario.

As a conclusion: be careful with your queries, retrieve only the data you really need, since it can happen that just one additional field (like CreationDate in this case) cause serious performance issues in the background. Obviously, it was a basic simple query, but imagine adding some complex joins, calculations, using functions, etc.
Rounding up with parameter sniffing
Ok, but what would one expect if this query becomes part of a stored procedure, so that it can handle any value for Upvotes, passed by parameter?
Let’s create a stored procedure:
create procedure sp_UpVotes (@UpVotes int)
as
begin
select Id as UserId
,UpVotes
,CreationDate
from dbo.Users
where UpVotes > @UpVotes
end
go
We saw earlier the execution plans SQL Server thinks best suit to satisfy what we were asking for. It won’t hurt if I write that again: Clustered Index Scan for 100 and 1000 upvotes, Index Seek for 10000 upvotes.
Let’s first clear the query cache, so we start fresh (hint: don’t do this on production server):
DBCC FREEPROCCACHE;
Now, let’s run our brand new stored procedure with three different parameter values, in same order as we ran the queries:
exec sp_UpVotes 100;
GO
exec sp_UpVotes 1000;
GO
exec sp_UpVotes 10000;
GO
And take a look at execution plans:
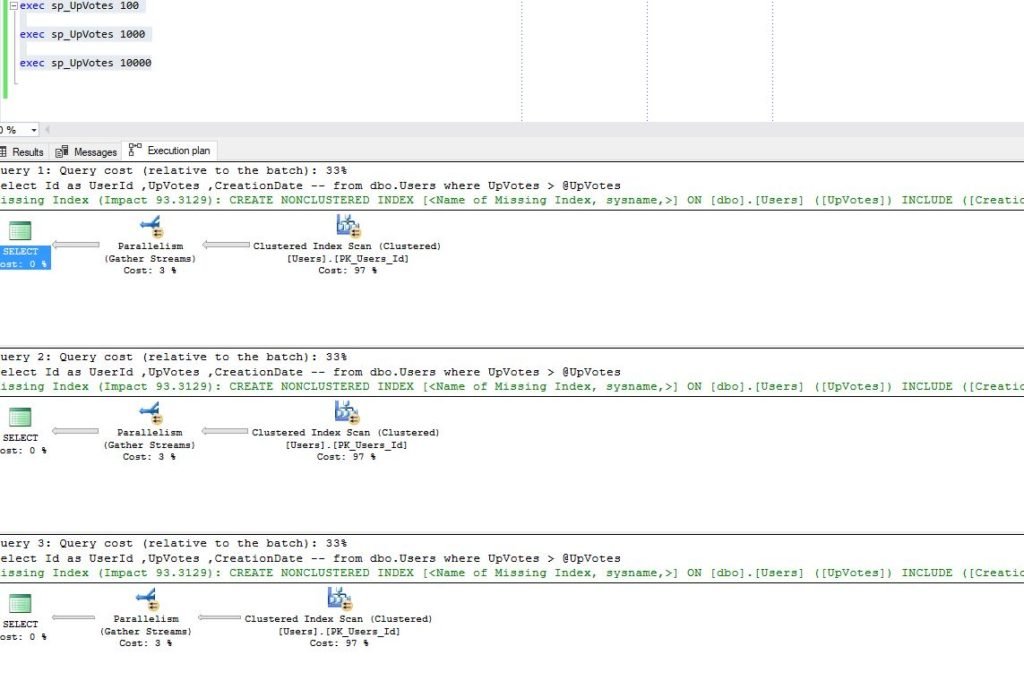
Wait, what?! Didn’t SQL Server use Index Seek when retrieving 168 users with more than 10000 upvotes??? Why does he think now that Clustered Index Scan is the way to go?
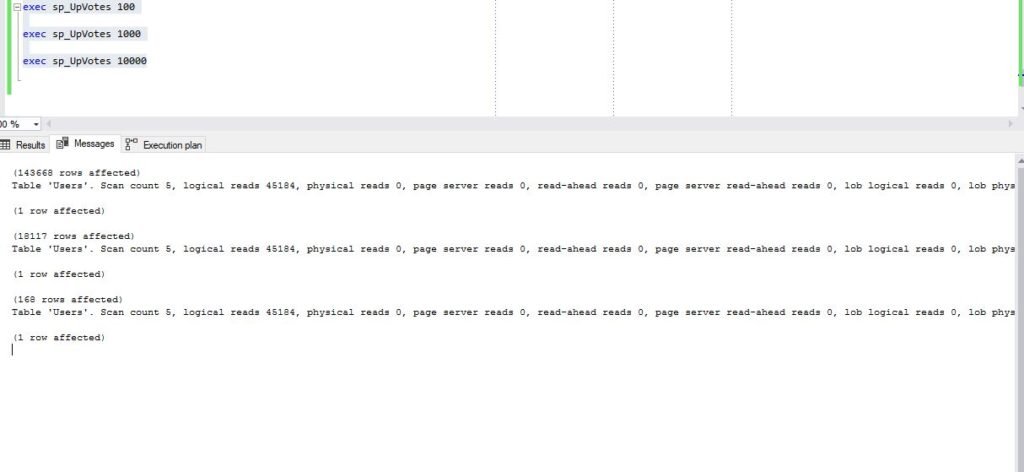
Instead of brilliant 527 logical reads, now we have 45.000, same as for the 143.000 users with more than 100 upvotes?!
Here, this is what happens: SQL Server creates a query plan based on the first run of your stored procedure. After that, whenever you run the procedure, SQL Server tries to “sniff” the parameter value and use exactly the same query plan as for the first scenario.
Is this query plan best fit for retrieving users with more than 100 upvotes? Probably YES. Is this query plan best fit for retrieving users with more than 10000 upvotes? Definitely NOT.
If you go back to Execution Plan for the last run of stored procedure (10000 value), in Properties pane you will see the Parameter Compiled Value equals 100! That’s the parameter value SQL Server created execution plan for!

There are different ways to handle “parameter sniffing” (please avoid OPTION RECOMPILE in production environment, unless you are 100% sure what you are doing). Therefore, I strongly recommend to read following article on this topic, since it really goes deep into details and explains possible pitfalls and solutions.
Parameter sniffing is not a bug, it’s a feature:). Of course, it is quite useful in many different situations, but it can also be a reason for unexpected overhead, like we saw in this simple example.
Last Updated on April 12, 2020 by Nikola


