

Have you ever wondered what makes Power BI so fast and powerful when it comes to performance? So powerful, that it performs complex calculations over millions of rows in a blink of an eye.
In this series of articles, we will dig deep to discover what is “under the hood” of Power BI, how your data is being stored, compressed, queried, and finally, brought back to your report. Once you finish reading, I hope that you will get a better understanding of the hard work happening in the background and appreciate the importance of creating an optimal data model in order to get maximum performance from the Power BI engine.

First look under the hood – Formula Engine & Storage Engine
First, I want you to meet the VertiPaq engine, “brain & muscles” of the system behind not only Power BI, but also SSAS Tabular and Excel Power Pivot. Truth to be said, VertiPaq represents only one part of the storage engine within the Tabular model, besides DirectQuery, which we will talk about in one of the next articles.
When you send the query to get data for your Power BI report, here is what happens:
- Formula Engine (FE) accepts the request, process it, generates the query plan and finally executes it
- Storage Engine (SE) pulls the data out of Tabular model to satisfy the request issued within the query generated by the Formula Engine
Storage Engine works in two different ways in order to retrieve requested data: VertiPaq keeps the snapshot of the data in-memory. This snapshot can be refreshed from time to time, from the original data source.
On the opposite, DirectQuery doesn’t store any data. It just forwards the query straight to the data source for every single request.
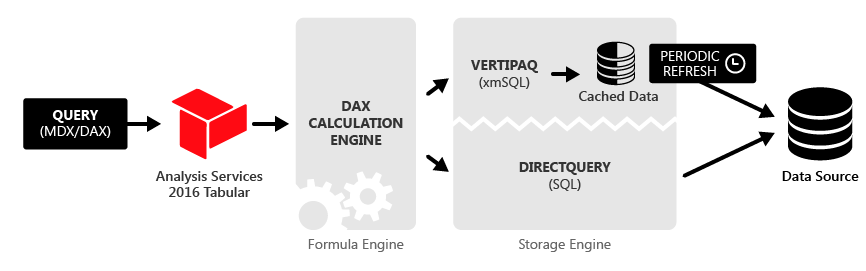
Data in Tabular model is usually stored either as an in-memory snapshot (VertiPaq) or in DirectQuery mode. However, there is also possibility of implementing a hybrid Composite model, which relies on both architectures in parallel.
Formula Engine – “Brain” of Power BI
As I already stressed, Formula Engine accepts the query, and since it’s able to “understand” DAX (and MDX also, but it is out of the scope of this series), it “translates” DAX into a specific query plan, consisting of physical operations that need to be executed in order to get results back.
Those physical operations can be joins between multiple tables, filtering, or aggregations. It’s important to know that Formula Engine works in a single-threaded way, which means that requests to Storage Engine are always being sent sequentially.
Storage Engine – “Muscles” of Power BI
Once the query been generated and executed by the Formula Engine, the Storage Engine comes into the scene. It physically goes through the data stored within the Tabular model (VertiPaq) or goes directly to a different data source (SQL Server for example, if DirectQuery storage mode is in place).
When it comes to specifying the storage engine for the table, there are three possible options to choose between:
- Import mode – based on VertiPaq. Table data is being stored in-memory as a snapshot. Data can be refreshed periodically
- DirectQuery mode – data is being retrieved from the data source at the query time. Data resides in its original source before, during and after the query execution
- Dual mode – combination of the first two options. Data from the table is being loaded into memory, but at the query time it can be also retrieved directly from the source
As opposed to Formula Engine that doesn’t support parallelism, the Storage Engine can work asynchronously.
Meet VertiPaq Storage Engine
As we drawn a big picture previously, let me explain in more details what VertiPaq does in the background to boost performance of our Power BI reports.
When we choose Import mode for our Power BI tables, VertiPaq performs the following actions:
- Reads the data source, transforms data into columnar structure, encodes and compresses data within each of the columns
- Establishes dictionary and index for each of the columns
- Prepares and establishes relationships
- Computes all calculated columns and calculated tables and compresses them
Two main characteristics of VertiPaq are:
- VertiPaq is a columnar database
- VertiPaq is an in-memory database
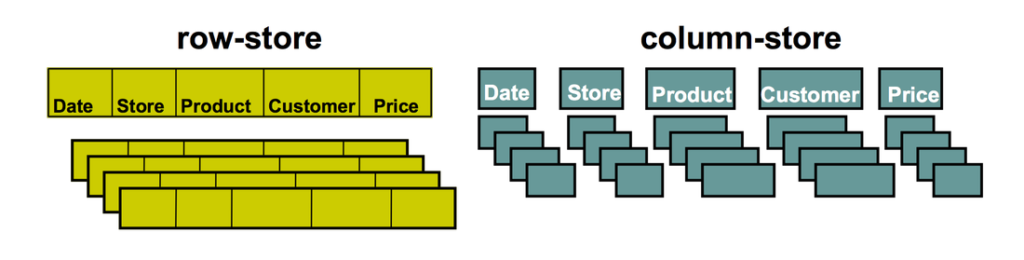
As you can see in the illustration above, columnar databases stores and compresses data in a different way to traditional row-store databases. Columnar databases are optimized for vertical data scanning, which means that every column is structured in its own way and physically separated from other columns!
Without going into deep analysis about advantages and drawbacks between row-store vs column-store databases, since it would require a separate series of articles, let me just pinpoint few key differentials in terms of performance.
With columnar databases, single column access is fast and effective. Once the computation starts to involve multiple columns, things become more complex, as intermediary steps’ results need to be temporarily stored in some way.
Simply said, columnar databases are more CPU exhaustive, while row-store databases increase I/O, because of many scans of useless data.
Conclusion
In this first part of the series, we painted a big picture of the architecture which enables Power BI to fully shine as an ultimate BI tool. Now, we are ready to dive deeper into specific architectural solutions and consequentially leverage this knowledge to make the most of our Power BI reports, by tuning our data model to extract the maximum from the underlying engine.
In the next part of the series, we will put emphasis on data compression. We will learn what types of encoding exist, and also how we can help VertiPaq to achieve the best possible data compression – which enables optimal data model size and better performance!
Last Updated on July 20, 2021 by Nikola


Alexandre Doyen
Thanks this is amazing! So concise. Much better than Microsoft lessons =)
Cardinality — Your Power BI Majesty! – Data Science Austria
[…] optimal condition — which means, reduce the data model size whenever possible! This will enable VertiPaq’s Storage Engine to work in a more efficient way when retrieving the data for your […]
Ambaji
This is excellent. Till now I was in an assumption that Vertipaq plays role in both Import and Direct Query, but with this I got clarity on the Row mode storage and Columnar storage too. Thanks for the best one.
3 Steps to troubleshoot any DAX Query | by Nikola Ilic | Sep, 2022 - Techno Blender
[…] two key components of the underlying architecture — Formula engine and Storage engine — in this article, and I strongly encourage you to read it before proceeding further, as it will help you to get a […]
Amit M
Well explained Nikola!! Much appreciated.
Nikola
Thanks Amit, happy if it helps.
Mohamed slim ben Mosbeh
Very clear, Big picture. I appreciate it, 😊