

With a lot of hype and fanfare, last week Microsoft announced its latest data and AI platform solution, called Microsoft Fabric. If you still haven’t heard about Fabric, you probably didn’t go to the Internet in the last few days:)
I’ve already introduced Microsoft Fabric in the previous article, so if you’re still not sure what is it all about and why you can think of Fabric as your “data football team”, I strongly encourage you to check that article. Additionally, there are many great articles and videos, both from Microsoft and the community, where you can find out more about Fabric and its various scenarios and components.
In the above-mentioned article, I scratched the surface of the inevitable topic that now comes into focus: “What now for Azure Synapse Analytics?” Since I’ve been asked this exact question multiple times in the previous days, I’ve decided to put down my thoughts and share them in this article.
Disclaimer 1
Everything you read in this article is based solely on my, and only my personal opinion and it doesn’t have any relation to anything or anyone from Microsoft
Disclaimer 2
This article assumes that you are familiar with the basics of Azure Synapse Analytics. So, more often than not, I’ll refer to certain concepts/features assuming that you are already familiar with them.
If you want to learn more about Azure Synapse Analytics, I suggest you start by reading one of the following articles:
Power BI & Synapse – The art of (im)possible
What Synapse brings to Power BI table
Dedicated vs Serverless SQL pool – which should I use?
Synapse Serverless SQL pool and file types – the ultimate guide!
Synapse Dedicated SQL pool – everything you need to know!
Or you may want to check my course for DP-500 exam, which covers Synapse Analytics in detail
So, the key question we’ll try to answer in this article is:
Will Microsoft slowly shut down Synapse, by “drowning” it into the new “data ocean” called Microsoft Fabric?
Of course, Microsoft will tell you that it’s not going to happen and that Fabric is just an “evolution of Synapse Analytics”, which might be true, but then a fair question would be: what happens with companies that heavily invested in Synapse in recent times, being convinced by Microsoft that they are investing in “latest and greatest” stack? Are they already lagging “behind”?
The next fair assumption is: ok, if we already invested in Synapse Analytics, we can easily switch to the “new kid on the block”, right? RIGHT?! Well, it depends:)
As of today, looks like Dedicated SQL and Serverless SQL pools from Synapse are somehow integrated into one solution in Fabric (Warehouse). We have traditional structures from the Dedicated SQL pool, such as columnstore indexes, data cache, etc. At the same time, Warehouse relies on the Polaris engine, which currently powers the Serverless SQL pool. This is an MPP (massively parallel processing) engine, which scales AUTOMATICALLY to support various data workloads. In other words, no more DWUs, whereas scaling out is now done by the engine, not by someone from your data team.
It’s maybe too harsh to say, but I think the Dedicated SQL pool is a “dead man walking” nowadays…
There is still no result-set cache, but I’ve been told that it’s coming soon.
But, first things first. Let’s first see the evolution of Synapse Analytics into Fabric:
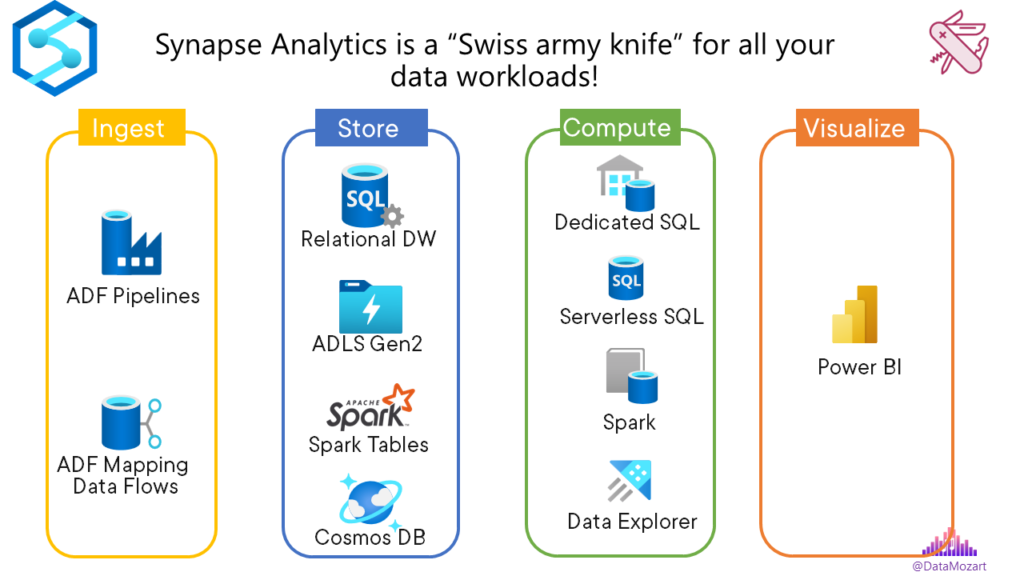
As a reminder, Azure Synapse Analytics was not so long ago branded by Microsoft as a “one-stop shop for all your analytic workloads and a unified platform for building your end-to-end analytic solutions”. We hear the same message now for Fabric…
Truth to be said, most of the Synapse features are directly available in Fabric as well, as you may conclude by looking at the Fabric architecture:
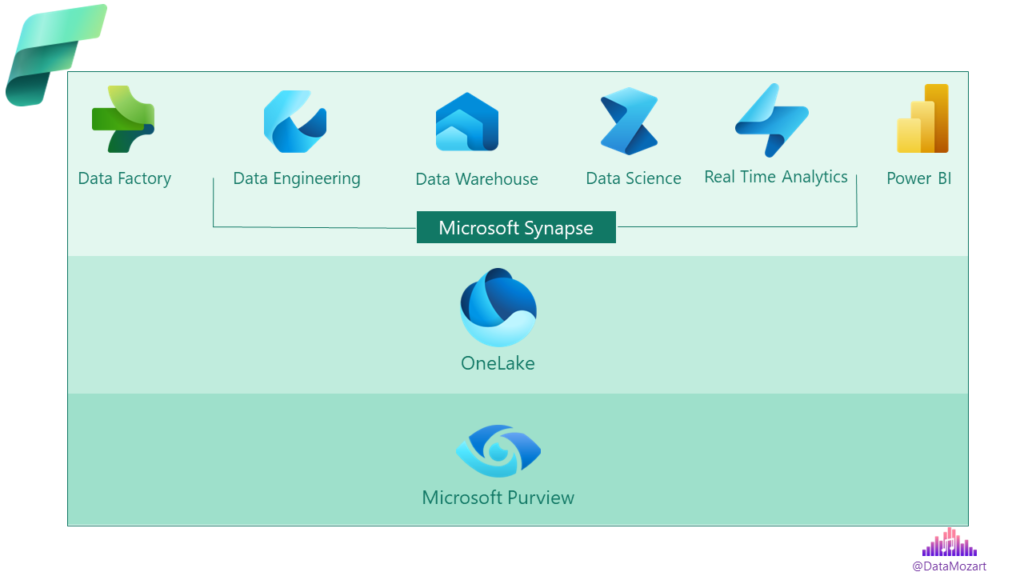
Instead of separating between different layers in the data workflow, Fabric distinguishes between various scenario-based options.
Before we continue, let’s first set the expectations for the remaining part of the article:
For organizations that still didn’t implement Synapse Analytics (or are at the very early stage): I really don’t see any reason for new customers to choose Azure Synapse Analytics over Microsoft Fabric, except maybe costs, because, in some scenarios, it may happen that prudent usage of DWUs in a Dedicated SQL pool, in combination with a pay-per-query model of the Serverless SQL pool will cost you less than Microsoft Fabric.
Additionally, there are many benefits of choosing the “Fabric path” – Spark engine spins up much faster in Fabric compared to Synapse, whereas Power BI integration looks way more natural and intuitive in Fabric (let alone the fact that the default Power BI dataset now represents not only the input for the Power BI report, but also an individual “data product” which can be used as any other data product within the Fabric ecosystem).
For existing Azure Synapse Analytics users, there are two key questions that require proper answers: migration overhead and/or costs…
Migration of existing Synapse Analytics workloads to Fabric
At the very beginning, let me be honest with you: there is no “lift-and-shift” option for migration! Meaning, you click “Next->Next->Next” and everything works as it used to work in Synapse. This is not going to happen for multiple reasons, so let’s examine a few of the most common ones:
- Mapping Data Flows don’t exist in Fabric – this means, if you used MDF to ingest and transform data in Synapse…Sorry, this artifact doesn’t exist in Fabric. Instead, you might want to use Dataflows Gen2 (more on them in one of the next articles, they are amazing!)
- OPENROWSET() isn’t supported in Fabric – huh, this is a huge deal-breaker for many Serverless SQL users, where you query the data from ADLS Gen2 by leveraging OPENROWSET() function:
SELECT
*
FROM
OPENROWSET(
BULK'https://<Your ADLS>/<Your file system>/Data/yellow_tripdata_2019-01.csv',
FORMAT='CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
)
as baseQuery
You can still query the data from the lake(house) in Fabric using T-SQL, but you would need to adjust all your queries that contain OPENROWSET syntax.
- No Synapse Link (yet) – Synapse Link is a very cool feature, especially for workloads when querying the data from Cosmos DB and/or Microsoft Dataverse. At this moment, this feature doesn’t exist in Fabric, so if you’re relying on Synapse Link, be aware that it’s still not available in Fabric.
- Bye-bye Synapse Studio – Synapse Studio is a web-based user interface for managing and developing all your Synapse stuff. Fabric relies on an entirely different concept, the concept of workspaces. If you had some exposure to Power BI, then you’ll find yourself in a familiar environment. But, if not, then be ready to adapt:)
To wrap up the migration part – there is a very handy feature in OneLake (remember, OneLake is the centralized storage repository for all Fabric artifacts), called Shortcut, which enables you to create a virtualized copy of your data lake that is stored “somewhere else” (i.e. ADLS, Amazon, Google). Shortcut, the same as in Windows, simply points to other (internal or external) storage locations.
Using a Shortcut, you can easily virtualize your ADLS Gen2 in Fabric, BUT your existing T-SQL queries must be adjusted (no OPENROWSET support). Generally speaking, migrating Spark workloads from Synapse to Fabric should be way more straightforward than SQL-related workloads.
Costs of Fabric vs Synapse Analytics
This one is still under the clouds. The reason is very simple – we still don’t have the official pricing list for Fabric. However, from what we know so far, it seems that Fabric will be charged on a capacity base. This means, a company pays a certain amount of $$$ for a dedicated set of resources.
While that could absolutely make sense for the majority of large organizations, that need consistent performance for large numbers of users, there are also many small-medium size companies that embraced the pay-per-query model of the Serverless SQL pool, where they pay only for the amount of data processed! I’ve witnessed first-handed that monthly costs at the company leveraging Synapse Analytics were between 150$ and 200$! Although the entry point into the Fabric world should be around 300$/month (this still has to be confirmed), and it might look like a super cheap option, this will enforce many companies to pay a fixed amount per month (nevertheless if they used the full capacity or not).
I’m not telling you that it’s not worth switching to Fabric, on the contrary, but you should do a detailed cost analysis and identify which option makes more sense for you. In the end, it’s not ONLY about Synapse vs Fabric, but also PaaS (Synapse) vs SaaS (Fabric)…
Conclusion
I’ll repeat it: if you’re just considering starting using a “unified analytics platform”, Microsoft Fabric should be your preferred choice in most cases.
However (and I’ll repeat that as well), it’s not only about Synapse vs Fabric: it’s also PaaS (you have more control, but also more responsibilities) vs SaaS (less control, but “everything just works”).
For organizations that already invested in Synapse Analytics implementation: sorry, but I don’t have a straightforward answer for you:)… Although Fabric provides almost all of the Synapse functionalities, there are certain features that are not supported (most noticeable, Mapping Dataflows and OPENROWSET() syntax in SQL queries over files in a data lake).
Costs are another important thing to consider. Since we still don’t have 100% clear pricing information for Fabric, I would keep my final judgment until it’s possible to perform a proper comparison,
And, finally, keep in mind that Microsoft Fabric is at this moment still in public preview, which means that many features will be added/adjusted/improved in the next months. So, I ASSUME that Fabric will get better and better in the coming months/years, which can make your decision about which platform to use more obvious and clear.
Thanks for reading!

Last Updated on October 27, 2023 by Nikola

Usaid Hubert
In the part below, I think it should be “not so long ago” instead of “not so long”. Great article though!
As a reminder, Azure Synapse Analytics was not so long branded by Microsoft as a “one-stop shop for all your analytic workloads and a unified platform for building your end-to-end analytic solutions”. We hear the same message now for Fabric…
Nikola
Ah, great catch, thanks!
Denys Chamberland
We may or may not agree with Microsoft decision to transit from Azure Synapse (Pass version giving us more control + more responsibilities) to Microsoft Fabric (an all in one Saas version where everything is ASSUMED to work…), but before making any blind statement I feel it’s important to understand the reasons which brought Microsoft to create Microsoft Fabric. I will not hide the fact that I actually loved (even up to this stage prefered) working with Azure Synapse Studio in form of Azure project orchestration rather than having to deal with some former uneducated Office365 now upgraded to Microsoft Fabric Admins… lazy Workspaces management monopoly. I was impressed by what Microsoft had created whenbI first started using Azure Synapse Studio and if someone had claimed that everything would transit under a small Power BI icon, I would have probably reacted with a bit of skepticism. Yeah sure… Instead of diving too deep, trying to swallow each and every experience content inside and out and ending up with Fabric indigestion, I rather decided to take a step back exploring the timeline. I believed that initiative would put me in much better position to evaluate the whole logical timeline equation. I then soon came to realize that Fabric really hasn’t happened overnight. Avoiding to strictly focus on the “product names”, we realize the initial goal and the main idea behind were born even before we may have expected, but may have taken time along a long path to get fully conceptualized. We then may come to understand that overall Azure Synapse was mainly a “step” towards the Microsoft Fabric transition. As I said we’re free to agree or disagree with Microsoft decision. At this stage, I feel the most predominant question any professional Data Analytics consultant may ask themselves is who will follow in the saga. I’ve previously worked in marketing long enough to know that you cannot expect gaining high rates gain profit if audience is not well informed and educated on what you’re offering them. Informing any potential users is part of the main mission of local Microsoft community meetups. It’s sad to say but I realize activities here are practically dead at this stage compared to what they used to be. It would be a bit naive to put the blame exclusively Covid as we noticed a major slowdown even before. My question is where are the MVPs? I haven’t seen many activities from them in a looooong time up here. Something’s obviously broken in the modus operandi and we cannot afford this. Thank you.
Natalie
I appreciate this was written a while ago.
What are your thoughts now?
I have been reading all of its limitations and missing features and I cannot see that this is near a full replacement.
I decided to trial Fabric (which was agonising to get working, both this time and last time I tried), and started to create a pipeline that I did in both Azure Data Factory (could just as well been Azure Synapse) and then tried to do the same thing in Fabric.
End result I could not build that in Fabric as quickly or easily and the UI was horribly laggy.
To use Fabric dataflows I have to use Power Query – OK fine, but here comes even more vendor and platform lock in – so what’s in that for the customer?
We know what’s in it for Microsoft 🙂
I don’t see Fabric as a replacement to ADF \ Azure Synapse today, might at a push be a compliment, but not a replacement.
It also siloes dev efforts as not everything can or will reside in FabricLandia so you will need integration tooling outside of it still too.
Personally I think Fabric is all about money making marketing, with huge amounts of spin speak over missing features and compatibilities when compared to other platforms, and with new toy syndrome thrown in for good measure.
Lets see what replaces it – this will happen in due course…
Nikola
Hi Natalie,
Thanks for sharing your thoughts, I appreciate it.
Synapse/ADF vs Fabric is not directly comparable, because Synapse/ADF are PaaS solutions, whereas Fabric is a SaaS. However, I still believe that Synapse will be let to die, and the official Microsoft’s stance is that there will be no new development on Synapse side – only ongoing support and bug fixing – which, more or less, tells you in which direction things will go:) Obviously, Microsoft will not tell you publicly that Synapse is dead, but I’m quite sure that Synapse customers will be “pushed” into Fabric in the very near future – one way or the other. Of course, organizations that already invested in Synapse/ADF will continue using it, but for every new greenfield project, I see no obvious reason for going Synapse/ADF route over Fabric, considering Microsoft’s plans for both solutions.