

If you follow my blog on a regular basis, you are already aware that I prefer describing real-life use cases to writing some pure theoretical stuff…Don’t get me wrong – of course, you should be able to understand core theoretical and conceptual foundations behind specific solutions, before diving into a real fun, but solving real-world problems is something that counts in the end.
Scenario
As I live in a speaking area that has special characters in addition to a “regular” alphabet (for those of you who don’t know, I live in Austria, where German language is being spoken), I’ve recently faced an interesting problem while creating a Power BI report for one of the clients.
The “issue” was related to a specific handling of German “umlauts” – those are the special letters Ä, Ü, Ö, ß, that are specific for German “edition” of alphabet. The thing is that these letters are sometimes written “as-it-is”, but sometimes they are written as they are being pronounced: ae, ue, oe, ss (for example, the Austrian car drivers’ association is called ÖAMTC, but their website is https://www.oeamtc.at – just to illustrate what I’m meaning).

So, back to the original request from a customer: they are analyzing car sales for specific stores in different Austrian and German cities. Data is being collected into a CSV file (I know, I know:)), and then goes to a Power BI for further analysis.
For the sake of clarity, this CSV file is just one of the different data sources that are part of the final report.
However, here comes the challenging part: sometimes, city names are written using “umlauts”, and sometimes using “pronunciation” logic – for example – Münich and Muenich; Düsseldorf and Duesseldorf, etc.
Here is how the data looks like in a simplified file I’ve prepared for this article:
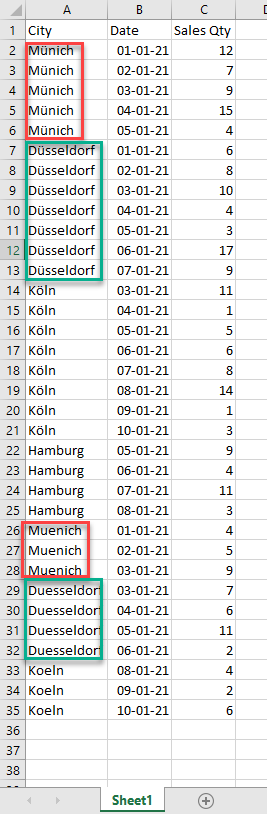
Now, when I import this CSV file in Power BI, here are the results I’m getting:
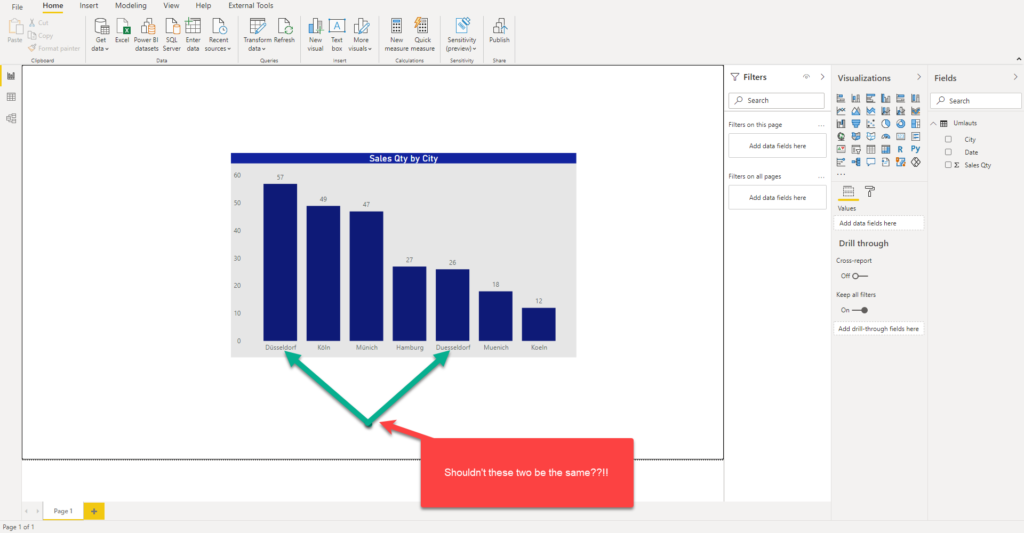
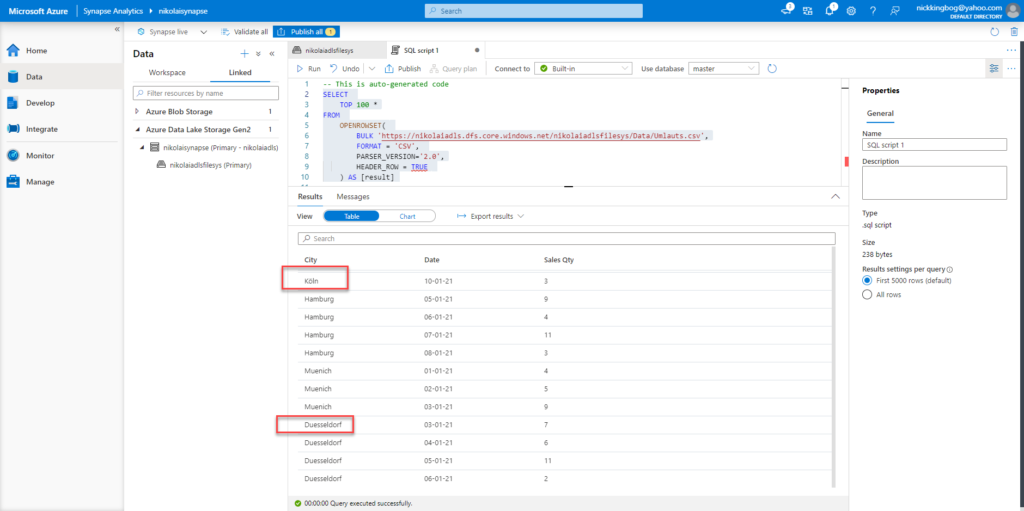
As you see, Power BI interpreted the data “as-it-is”: that means, even if in reality there were 83 cars sold in Düsseldorf, we can’t see this figure in the report, as it was split between Düsseldorf and Duesseldorf! The same applies to other cities whose names contain “umlauts”. Only Hamburg results are correct, as this city has no special characters in the name.
Trying to find a solution in Power BI
Power BI Desktop offers a lot when it comes to settings and adjusting various features for your data. However, there is not (or, at least, I’m not aware of it) an option to handle those special characters in a proper way.
I’ve tried changing File origin to German, before importing the data in the Power BI Desktop, but what happened is that umlauts were just substituted with the question mark:
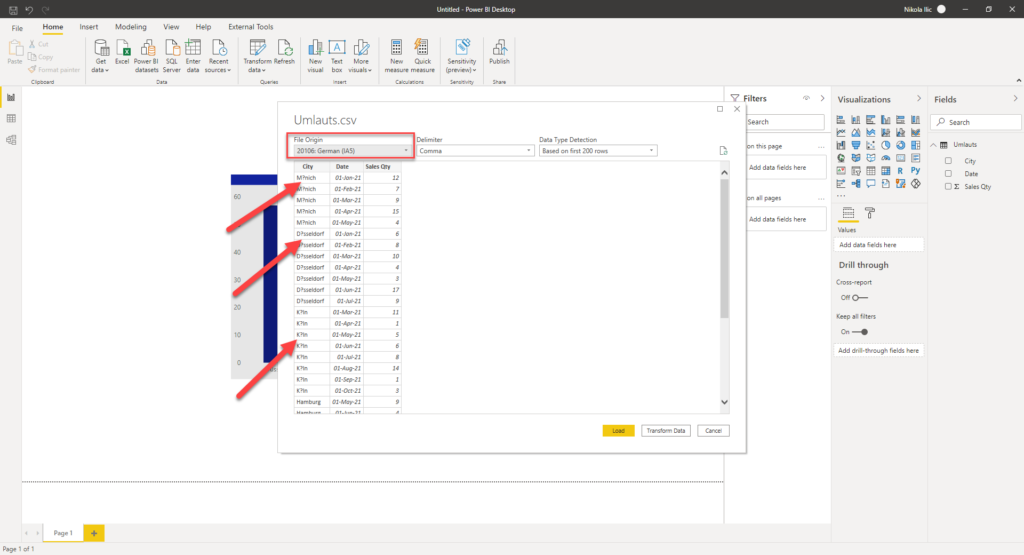
Then, I’ve tried to adjust Regional settings for the current file, just to discover that only numbers, dates and time are being affected by this setting!
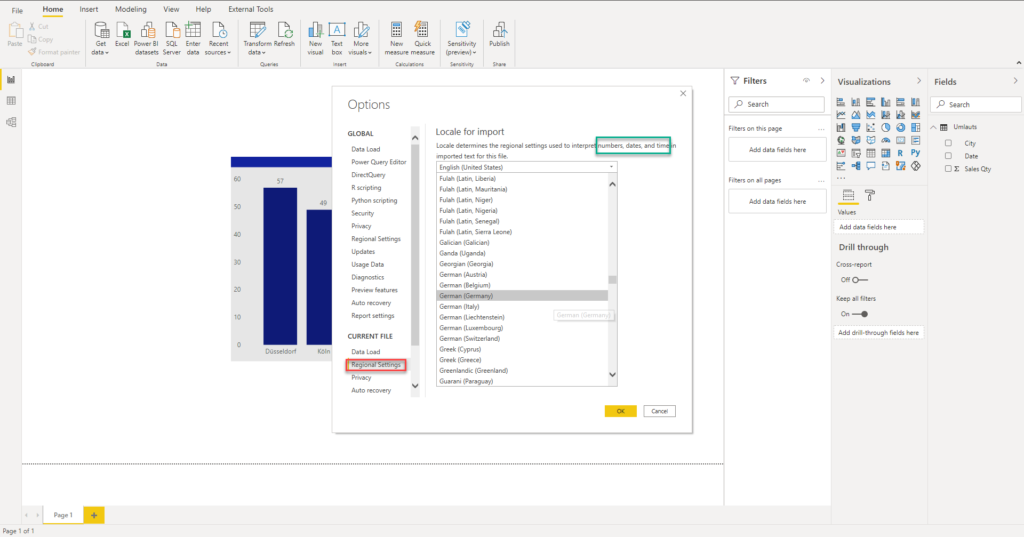
One important disclaimer from my side: I’m by no means a Power Query expert, and maybe there is a workaround solution in PQ to handle this challenge, but I couldn’t find anything similar on the web…
So, it looked like my client will need to clean the data on the source side (which is, of course, the best possible solution in all cases, and should be applied whenever possible), but the reality is cruel and clients usually want you to do the all hard work instead of them:)))
Synapse Serverless SQL to the rescue!
While scratching my head around this problem, I’ve decided to try to massage the data in the Synapse Serverless SQL pool. I’ve already written about the immense possibilities that this integrated analytics platform offers, especially in synergy with Power BI, so let’s see if we can leverage Synapse Serverless SQL to solve our “umlauts” problem!
As it leverages regular T-SQL syntax to retrieve the data from multiple disparate sources (such as CSV, Parquet files, or Cosmos DB), one of the things that Serverless SQL brings to the table is (almost) full set of features available in “normal” SQL Server.
In a “normal” SQL Server, one could handle similar request by changing the database collation to be able to “recognize” special characters from the German language. More about collation itself, and specific collation types can be found here.
As my client was already using Azure Synapse Analytics for various data workloads and had a Serverless SQL pool activated, I’ve decided to take a chance and apply the similar strategy as I would do with the on-prem SQL Server!
But, first things first…I’ve uploaded my CSV file to Azure Data Lake Storage Gen2 account, from within Synapse Studio:
And, if I run the following script from the Synapse Studio…
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://nikolaiadls.dfs.core.windows.net/nikolaiadlsfilesys/Data/Umlauts.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
) AS [result]
I will get exactly the same outcome as previously…
So, let’s change the collation of the database to be able to recognize German alphabet:
ALTER DATABASE CURRENT collate German_PhoneBook_100_CI_AI_SC_UTF8;
And let’s see if something changed once I run the following script:
SELECT
City
,SUM([Sales Qty]) AS TotalSalesQty
FROM
OPENROWSET(
BULK 'https://nikolaiadls.dfs.core.windows.net/nikolaiadlsfilesys/Data/Umlauts.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
)
AS [result]
GROUP BY City
Here are the results…
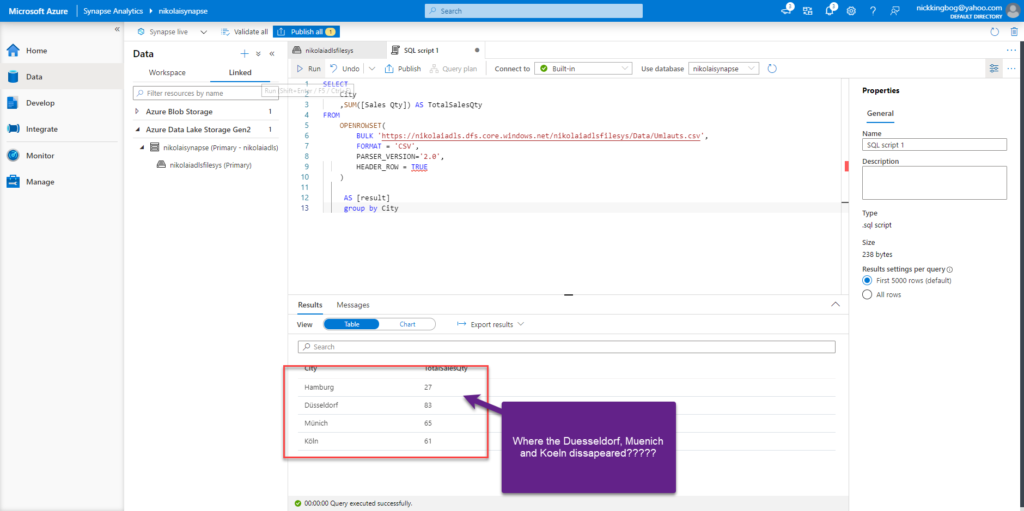
Voila!!! It looks exactly like what I was trying to achieve! Let’s create a view over this dataset and use that view in Power BI Desktop:
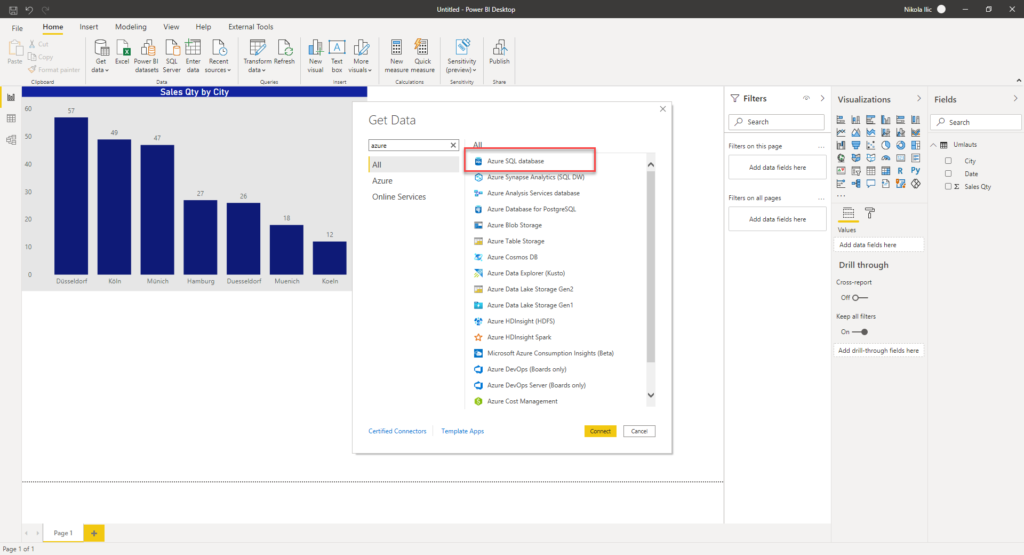
Now, when I put two visuals next to each other – one based on the data coming directly from the CSV file, and the other based on the data “collated” in Synapse Serverless SQL pool, I’m getting the following results:
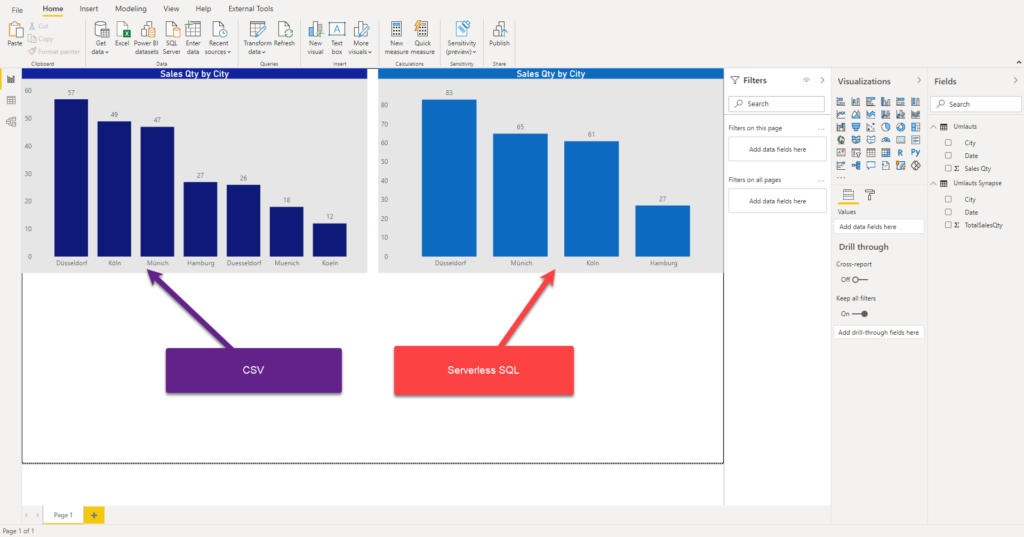
No need to say which visual provides correct and expected outcome!
Conclusion
As you witnessed, you don’t need to use Synapse Analytics, and Serverless SQL pool within it, to manage only some usual generic tasks – such as querying data coming from various disparate sources (CSV, JSON, Parquet files; Cosmos DB; Spark Tables).
You can take full advantage of Serverless SQL pool features to solve some niche challenges, like this one I’ve faced recently in a real-life scenario!
Of course, my scenario required to find a specific solution to German “umlauts”, but you can perform the same approach if you are dealing with Scandinavian, Turkish, or whatever alphabet in the world that contains non-standard letters! You just need to find an appropriate collation for the respective set of characters you are dealing with.
Now, my problem was solved, client satisfied, so I can enjoy a pint of Münchner (or Muenchner) beer:)!
Thanks for reading!
Last Updated on January 28, 2021 by Nikola


