

A few weeks ago, my good friend, Tom Martens (x), asked me what are my top 5 “not-so-obvious” features in Microsoft Fabric. You know, we are not talking about Direct Lake, Lakehouses, notebooks, etc, although I already covered most of these in my introductory Microsoft Fabric article. If you are completely new to Fabric, I encourage you to check this article first.
So, I sent my list to Tom, and then he sent me his picks – aside from the fact that our choices matched 3 out of 5 (“Great minds always think in sync” 😁, as Tom likes to say) – the thing that made me smile is that one of the three “matching” features was – Mirroring.
This is something I’ve been eagerly expected since it was announced, so I couldn’t wait to put my hands on it and check how it works in real life. Therefore, this article will try to examine this feature from different angles, which should help you evaluate possible use cases and real-life implementations.
DISCLAIMER: At the moment of writing, this feature is still in public preview, which means that things can change before mirroring becomes generally available
Understanding the context
First things first. Before I show you how to leverage this feature in Microsoft Fabric, let’s first explain the feature itself.
But, before we explain the feature itself, we need to go one step back and examine the key logic behind the Microsoft Fabric workloads, so that you understand the full context of the Mirroring importance.
One of the Fabric’s pillars is OneLake. Explaining OneLake is out of the scope of this article, but you can think of it as of “OneDrive for all your organizational data”. All your organizational data should be stored in one central location (OneLake), and even if your data resides somewhere else (let’s say in ADLS Gen2, GCP, Dataverse, or AWS), you can create OneLake shortcuts and have this data available for processing by all Fabric analytical engines, the same as the data would have been stored physically in OneLake. So, no data copying or movement to Fabric – you can access it via shortcuts, while OneLake manages all permissions and credentials. How cool is that! By the way, shortcuts were also on my Top 5 features list…
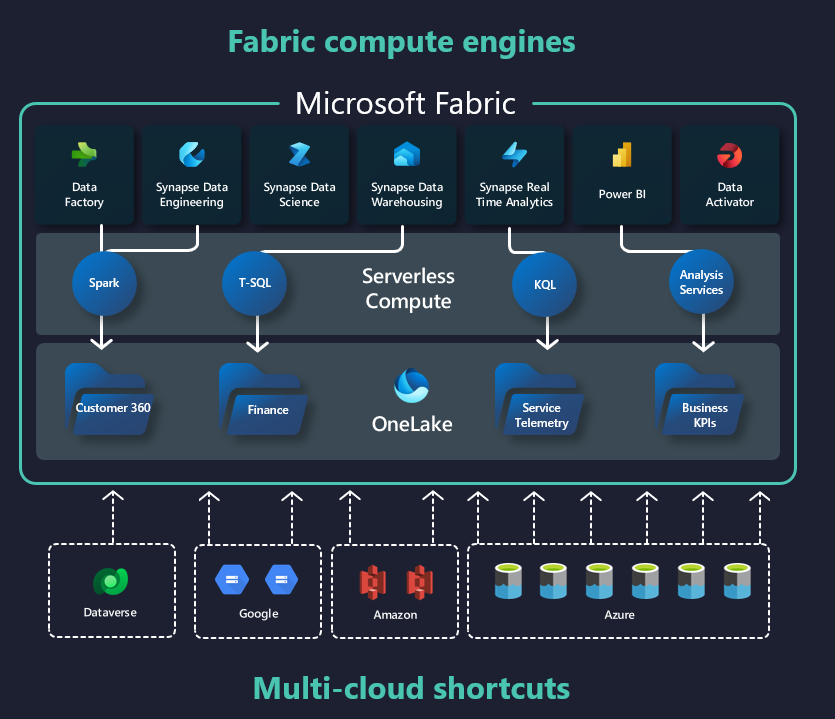
I believe you are starting to get the idea:) Microsoft Fabric is being sold as a “unified end-to-end analytics solution” – so, how it could be unified if you have your data stored somewhere else, and then you need to establish complex ETL/ELT processes to bring this data physically to Fabric?
“All right, this is cool, but I have my data stored in different sources, such as Snowflake, Azure SQL DB, or Cosmos DB…As far as I see on your illustration above, shortcuts can’t be created to these data sources, right?”
Unfortunately, you’re right (at least, at this moment)! All these databases (and many others) rely on their proprietary storage formats, and Fabric is all about Delta format. Therefore, it’s not possible to simply create shortcuts to these data sources. So, welcome back to reality and the world of creating ETL/ELT pipelines to make this data available for analytics…
What if I tell you that reality can be much better? So much better that you can have your data from Snowflake or Azure SQL DB available in Fabric in near real-time, without the need to build a single ETL/ELT process?!
Welcome to “mirrored reality”!
Remember the idea of the “unified experience”? That’s exactly what the Mirroring feature ensures for “non-shortcut-supported” data sources! You simply provide connection details of the “mirrored” database, and after the initial snapshot has been created, data will be synchronized in real-time! Whenever someone performs insert/update/delete on the source database, these changes will be automatically propagated to Fabric, hence your users will always have the latest data available for their Fabric workloads!
Before I show how this works in real life, a little more of a theory:) (Thanks to Idris Motiwala from Microsoft team working on Mirroring feature, for the clarification). Mirroring uses a special change feed tech in the background, to enable writing directly to OneLake, instead of creating “changed data” tables in the source database. Therefore, data stored in the database’s proprietary format will be “translated” to Delta format and stored as Delta tables in OneLake.
Once in OneLake, you can do all the things you are doing with “regular” Fabric workloads – query mirrored data, or even write cross-database queries to combine the data from the mirrored database, existing Fabric warehouse, or Fabric lakehouse.
I hear you, I hear you…”What if we want to leverage a Direct Lake mode in Power BI reports? No chance we can include mirrored database data, right?” You couldn’t be more wrong! Don’t forget, mirrored data is now in OneLake in the Delta file format – so, nothing prevents Direct Lake mode from reading this data the same as it would have read Fabric “native” Delta tables! And, it’s not only about Direct Lake – all Fabric capabilities, such as notebooks, for example, can be leveraged over mirrored data.
Mirroring in action
Let’s now dive deep and examine how Mirroring works in Microsoft Fabric.
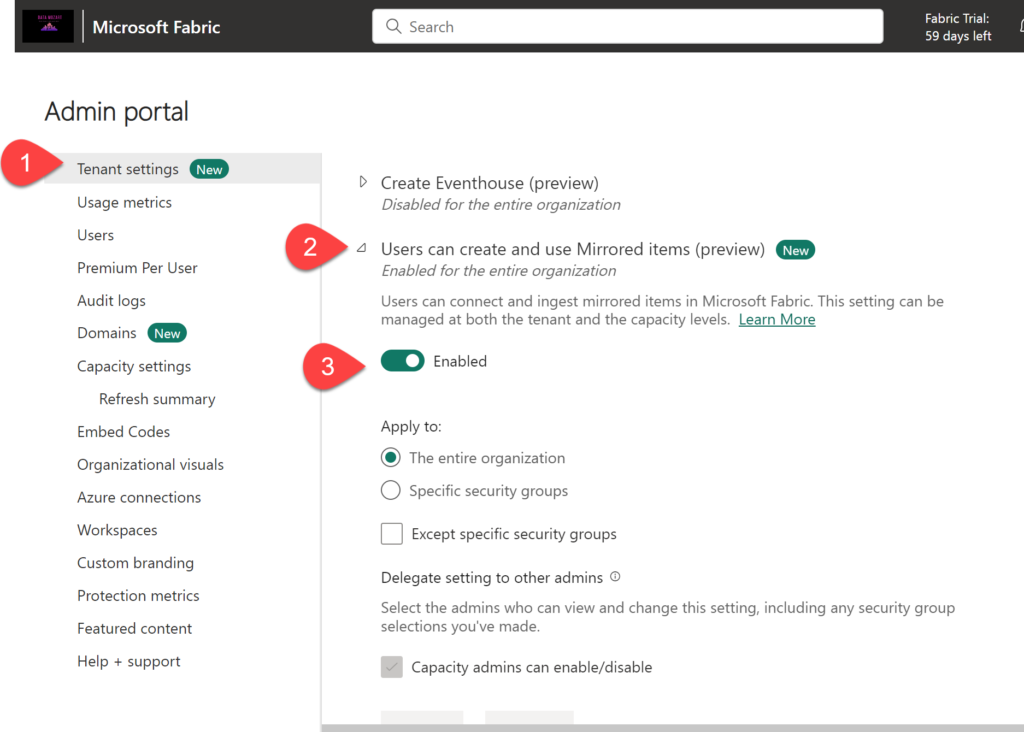
First, Mirroring must be enabled within your Fabric tenant:
Once in the Data Warehouse experience in MS Fabric, you can choose between creating Mirrored database for Azure SQL DB, Snowflake, and CosmosDB:
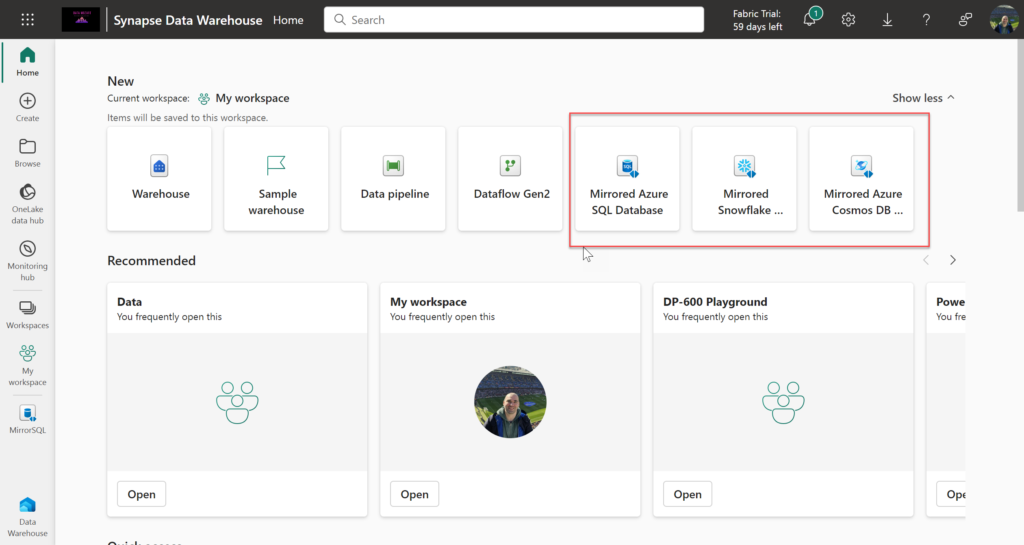
Once you select desired database for replication, there are certain prerequisites to complete before mirrored data shows within your Fabric tenant. I won’t go into details explaining how to set everything up, since there is a great step-by-step tutorial on Microsoft Learn. Also, my fellow MVP, Gilbert Quevauvilliers created a fantastic overview of how to quickly get up and running with mirrored Azure SQL DB, which you can check here.
Things to keep in mind…
Let me briefly introduce some of the (in my opinion) key facts when it comes to mirroring:
- Data is PHYSICALLY stored in your Fabric workspace (unlike with shortcuts, when there is no physical data movement)
- Because the data is physically stored in OneLake, you need to pay for the storage. At this moment, Microsoft will give you a free storage (if anything in Fabric is really free, haha) of up to the number of terabytes that equals number of CUs you purchased. Example: F2 SKU gives you 2 TB of mirrored data free of charge, F4 SKU 4 TB, and so on…
- What happens if you pause Fabric capacity? Well, in that scenario, you’ll be charged for the storage based on the regular OneLake storage pricing (~ $24 per TB)
- Direct Lake mode for Power BI semantic models is supported for mirrored tables (data is V-ordered to additionally increase the performance)
- If you delete the mirrored table, it won’t affect the original table in the source database
- Mirroring is not “ALL or NOTHING” process – this means, you can select individual tables that you want mirrored in Fabric, not just the entire database (but you can, if you want:))
- Keep in mind that if your source database is located in a different region than Fabric capacity, egress fees will be charged
- Views are currently not supported (mirroring applies only to regular tables)
What about SQL Server?!
I know that most of us are interested to hear if mirroring supports SQL Server as a data source…I got this question at least 10 times during my Ask the experts sessions at Microsoft Fabric Community conference in Vegas this March. As of today, SQL Server is NOT supported for mirroring, but according to the official Fabric release map, it’s planned for this year! So, fingers crossed that we can soon have our SQL Server on-prem data easily replicated in Fabric.
Conclusion
I can’t remember being so excited about any feature, since Fabric was officially announced, as for mirroring. This was a missing puzzle in “One Copy for All Data” mantra and I’m sure that it will immensely help in Fabric adoption across organizations that already implemented and developed mature data platform solutions. Once Mirroring becomes available for on-prem data sources, such as SQL Server or Oracle, Microsoft Fabric will become a no-brainer choice for organizations looking to modernize their data estate.
Thanks for reading!
Last Updated on March 31, 2024 by Nikola


Morten Svendsen
Hi, Thank you for a great article – as always 🙂
Do you know if there is there any news about mirroring for Oracle database onprem?
Nikola
Hi Morten,
I really don’t know. Hopefully it will come in the same wave with the SQL Server mirroring:)