

Sometimes, things are happening for a reason.
A few weeks ago, I was attending Benni De Jagere’s session about Power BI performance tuning at Data Grillen. It was a great session and one of the tips Benni shared was related to the IsAvailableInMDX property in Tabular models. I remember hearing about it sometimes somewhere, but honestly rarely had an opportunity to apply it in a real-world scenario. But, as I said at the very beginning, things are happening for the reason…
Last week, I was working on optimizing the Power BI solution for a client. I made sure to pull all the aces up my sleeve to make the data model more efficient – removed unnecessary data, reduced the cardinality wherever was feasible, adjusted column data types, and applied some additional recommended practices…And, then, I’ve remembered Benni’s tip and decided to give it a shot and see what happens if I disable the IsAvailableInMDX property…
But, let’s start by explaining what is the IsAvailableInMDX property…
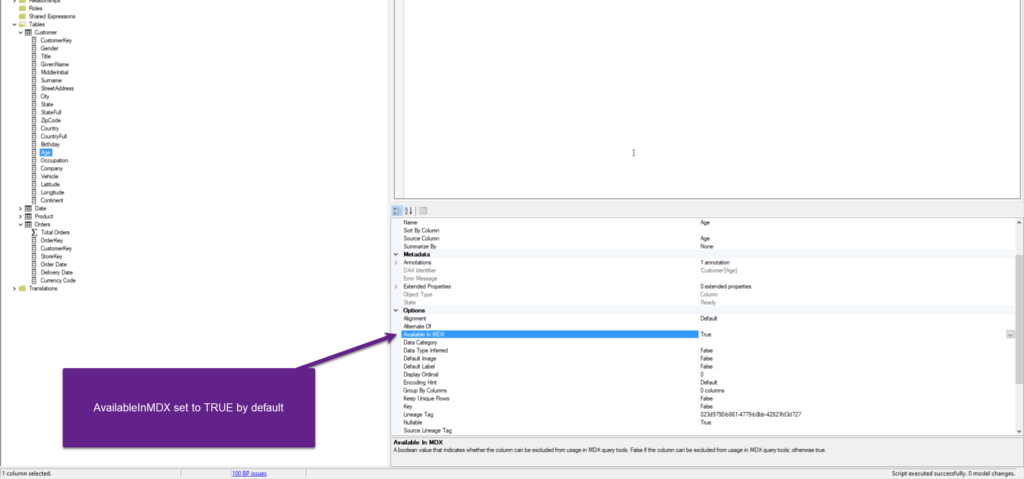
If you go to Microsoft Docs, you’ll probably be disappointed, as there is an obscure definition of the property. However, Chris Webb wrote a great blog post (one of many) a while ago, explaining the property and the way it works. In case you don’t want to read Chris’s original post for whatever reason (even though I encourage you to read it), in a nutshell, the IsAvailableInMDX property value (TRUE or FALSE) determines if the attribute hierarchies on the columns will be built or not.
Now, the fair question would be:
What is the attribute hierarchy?
[Date].[Fiscal Year].&[2022] ,[Product].[Category].[Bikes] ,[Sales Territory].[Sales Territory Group].&[Europe] ,[Measures].[Internet Sales Amount]
Hands up, all of you that recognized good old MDX! The language used for querying SSAS Multidimensional models…As you may (or may not) see, each column belongs to a certain hierarchy: Fiscal Year belongs to Date hierarchy, Bikes are part of the Category hierarchy, where the parent level is Product…Also, measures are part of the hierarchy as well! That’s important to understand, as you’ll find out soon. These are all User-defined hierarchies!
However, SSAS Multidimensional also creates Attribute hierarchies, where each regular attribute becomes the part of the 2-level hierarchy, with “All” as a top level:
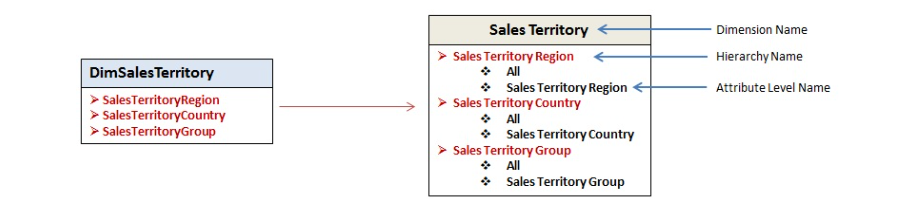
The key characteristic of the attribute hierarchy is that the column which is part of the hierarchy can be used both as a row and column in an MDX query. Ok, now you (hopefully) know what are attribute hierarchies, but…Hey, Nikola, we’re talking about Power BI here, the Tabular model…SSAS Multidimensional is a legacy technology, right? Well, we can argue about that, but it is obviously out of the scope of this article:)
However, it’s still a valid question:
What on Earth does MDX have in common with Power BI?!
Quiz question: which language does Excel use when connecting to Analysis Services Tabular model (bold and italic with purpose on Tabular)? I’ll help you a little bit: it’s not DAX…
Yes, Excel generates MDX queries when connecting to AS Tabular model! And, this brings us to a key takeaway: as Excel relies on MDX, it also relies on the data structures present in the multidimensional model! This implies, unless you explicitly set the IsAvailableInMDX property to FALSE, the attribute hierarchies will be part of your data model!
Now, the next question is: why this property is not by default set to FALSE? Well, in many real-life cases, Excel is the tool of choice for many data analysts. They should be able to connect to the Analysis Services Tabular model behind Power BI (don’t forget, Power BI stores the data in the instance of Analysis Services Tabular), so if this property would have been disabled by default, they shouldn’t be able to perform their analysis!
What’s even more interesting, most of the Power BI developers are not aware of this property at all! And, why they should? It’s not accessible from the Power BI Desktop, attribute hierarchies are not visible in the Power BI Desktop at all, while in the Power BI itself, you won’t notice any difference in the figures displayed in the visuals! So, why bother with it when everything works perfectly in Power BI, while your Excel analysts are also happy with creating their Pivot tables using the data from the Power BI dataset?
Now, we come to the point when THIS matters…To the point that helped me make astonishing improvements in the client’s Power BI solution.
I won’t waste time demonstrating the difference between the Excel and Power BI when displaying the data stored in the Tabular model (again, go and read Chris Webb’s blog post where everything is explained), but rather focus on the differences in the data model performance when this property is enabled or disabled.
Data model starting point
In this article, for the demo purposes, I’ll use a Contoso sample database, the version containing 100 million records in the fact table (courtesy of SQLBI.com guys, you can download and customize different versions of the Contoso database here).
So, let’s import our data into Power BI and check the numbers behind the data model. As usual, I’ll use a VertiPaq Analyzer tool in the DAX Studio:

As you see, the total size of my dataset is almost 6.3 GBs! Now, there are two possible options if you decide to play around with the IsAvailableInMDX property:
- Set the property value to FALSE for all the columns in your data model – meaning, no Excel analysis at all! So, the main question here is: do you want to restrict connecting to the data model from Excel completely?
- Set the property value to FALSE for some columns in your data model – namely, non-attribute columns, such as facts (measures) and keys. This will still enable Excel connections, but disabled columns won’t be available as a part of the hierarchy
I’ll show you the impact on the data model size and processing time for both options.
Set IsAvailableInMDX to FALSE for ALL columns
Let’s start with the holistic approach and disable attribute hierarchies for all the columns in the data model. So, we will measure two metrics: data model size and full data processing duration. Our initial benchmarks are 6.27 GBs and 143 seconds. Obviously, data process duration depends on multiple different aspects, but I’ll try to isolate this on my (quite powerful) local machine.
Of course, you can go and manually change the property value for each column, but that would take forever, especially in large models. So, here is the simple script that you can execute from the Advanced Editor window of Tabular Editor, that will set the IsAvailableInMDX property to FALSE for all the columns in the data model:
foreach(var column in Model.AllColumns)
column.IsAvailableInMDX = false;
Once I save the changes back to my model, let’s refresh the dataset and check if something changed:
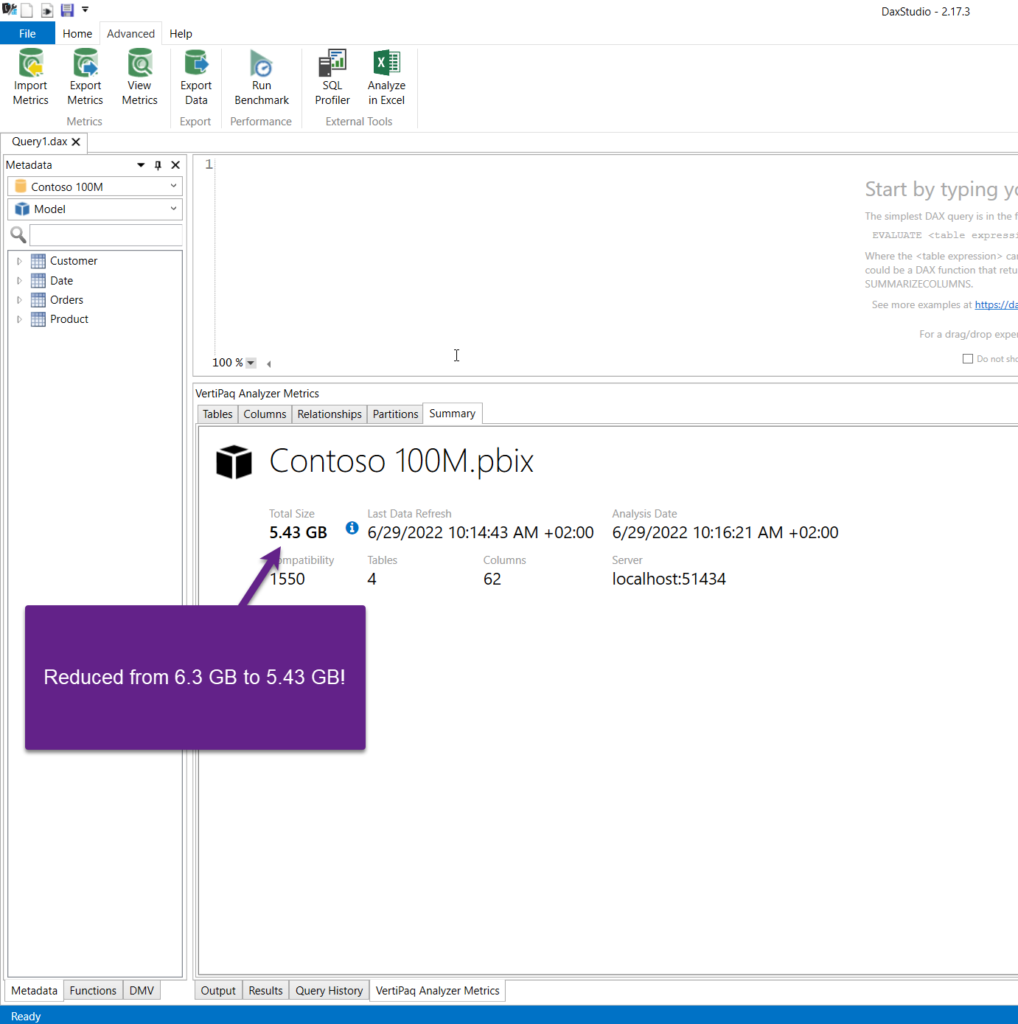
Oh, wow! 15% of savings just by changing the value of one “hidden” property! In terms of the data processing, time went down to 118 seconds, which is 25 seconds faster than previously!
| Metric | IsAvailableInMDX = TRUE (All columns) | IsAvailableInMDX = FALSE (All columns) |
| Data Model Size | 6.27 GB | 5.43 GB |
| Data Processing Time | 143 seconds | 118 seconds |
Remark: In a real-life case, the fact table had ~500 million rows, and many more dimensions (some of them containing 2-3 million records), thus the performance improvement was even more remarkable
That’s great, but the client’s requirement was to keep Excel users happy and enable them to continue using their favorite tool.
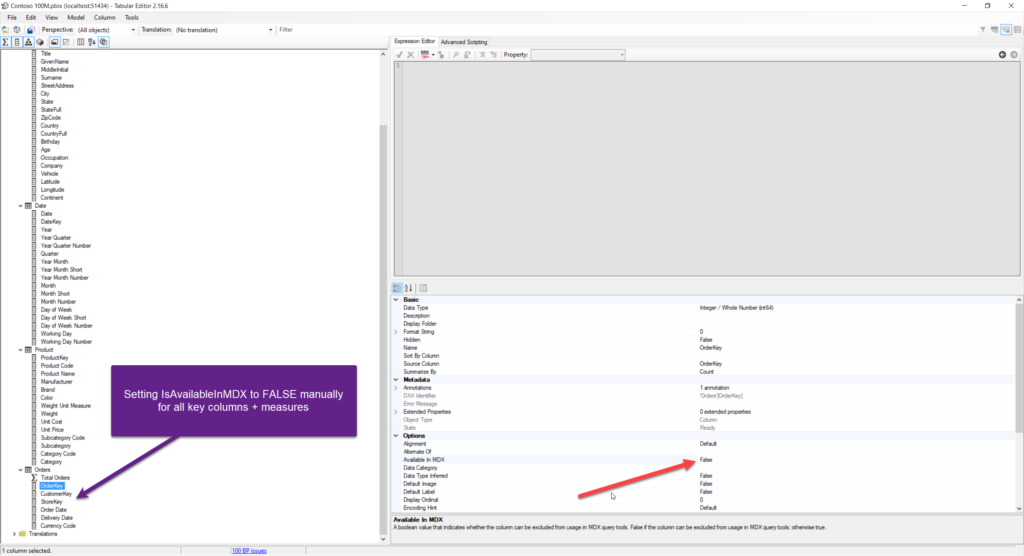
So, let’s set the IsAvailableInMDX property to FALSE only for the facts (columns that are used for creating measures) and key columns (that should be hidden from the end-user anyway, in accordance with the recommended practices).
Two ways of handling IsAvailableInMDX property for “some” columns
Now, it’s the right moment to discuss an additional point that is useful when you want to disable only some columns for MDX queries. There are two possible ways to handle the IsAvailableInMDX property and I’ll show you both. Let’s start with a simpler one, but the one that requires a lot of manual work!
Another, more convenient and I’d dare to say recommended way to achieve exactly the same outcome, is to leverage a Best Practice Analyzer extension in Tabular Editor to do the tedious work for you! Best Practice Analyzer is the amazing tool created by Michael Kowalsky, that can immensely help you to optimize your data models. In a nutshell, it scans the whole data model and based on findings, lists all the rules that were not followed. You can then decide if you want to apply recommended practices on your own, or let Best Practice Analyzer do that for you!
Now, there is a little catch in this specific scenario: BPA has a rule that sets the IsAvailableInMDX property to FALSE only for hidden columns or for columns whose table is hidden, as explained in this article by Michael Kovalsky:

In simple words, if you didn’t follow the recommended practice to hide non-attribute columns in the first place (fact table columns and keys), the rule for setting the IsAvailableInMDX property to FALSE wouldn’t work! That’s what Michael calls “Rule Synergy” in his article…
Anyway, let’s do a final check of our benchmarks with non-attribute columns disabled for MDX queries:
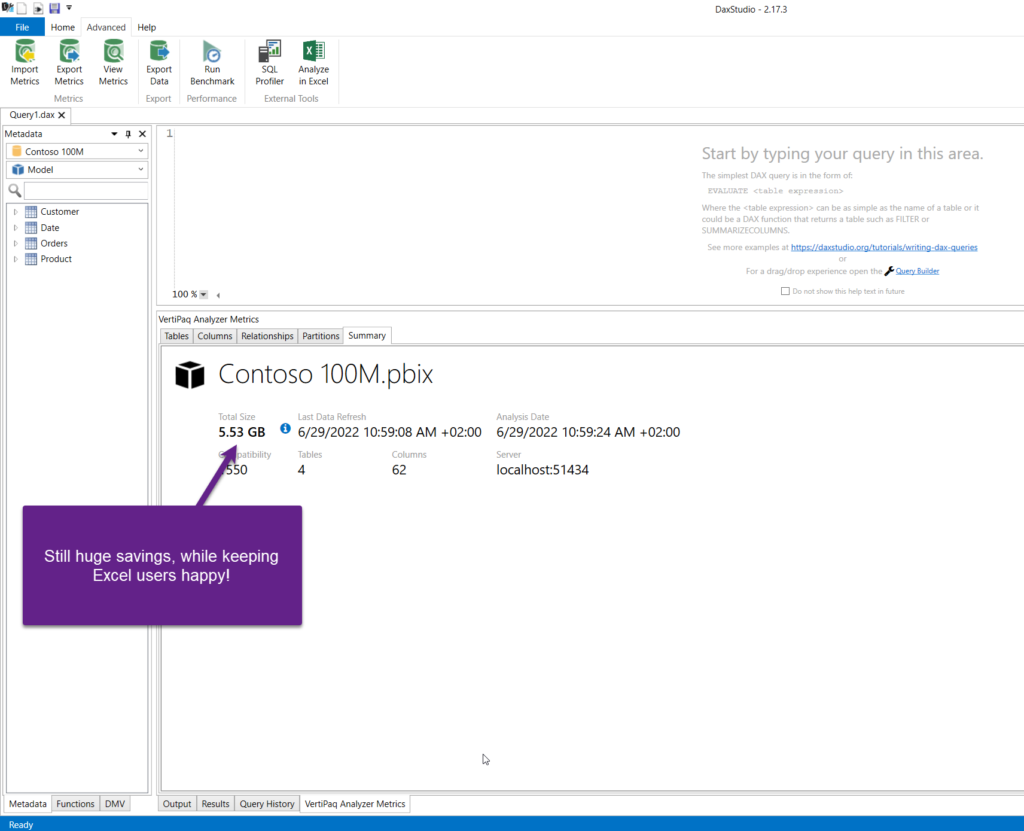
This change added 100 MBs to the overall data model size, but we are still 750 MBs below the starting point! And, don’t forget, in this scenario, it’s a win-win situation – we reduced the data model size, while keeping our Excel users happy! Processing time slightly increased to 124 seconds, so here is the overview after the second use case:
| Metric | IsAvailableInMDX = TRUE (All columns) | IsAvailableInMDX = FALSE (All columns) | IsAvailableInMDX = TRUE (attribute columns); FALSE (non-attribute columns) |
| Data Model Size | 6.27 GB | 5.43 GB | 5.53 GB |
| Data Processing Time | 143 seconds | 118 seconds | 124 seconds |
Word of warning
I feel obliged to warn you about the side-effects of disabling the IsAvailableInMdx property. Attribute hierarchies store some important information, such as the number of distinct values in that column, also stored in alphabetical order. Consequentially, you can also quickly pull MIN and MAX values from the column.
If you frequently use operations such as DISTINCTCOUNT, MIN, MAX, over one single column, without including filtering results by another column, the Tabular model that has the IsAvailableInMDX property enabled could perform better.
So, should you ALWAYS disable this property? As usual, it depends:)
Conclusion
Power BI (and the Tabular model) are full of hidden gems! Sometimes, these gems are really hard to find (or hard to understand their possible impact), but once you manage to do it, you can make significant improvements to your Power BI solutions.
As you’ve witnessed, by simply changing the default value of the property that is hidden deeply in the Tabular model, I was able to increase the efficiency of the Power BI solution, without sacrificing the overall users’ experience and core functionalities (namely, using Excel for querying Power BI dataset).
Thanks to Benni for the tip, and Chris for the wonderful blog post.
Thanks for reading!
Last Updated on November 13, 2023 by Nikola


cbi
i do not see the property in Tabular Editor
i open my PBI model in PBI desktop; i go to external tools and I open Tabular Editor
the property is not anywhere to be found
what am i doing wrong?
is
Nikola
You might need to enable experimental features in Tabular Editor (under File -> Preferences). Hope this helps.
Carlos Cantu
Great article, very useful, thanks for sharing!
David
I don’t quite get the ” using Excel for querying Power BI dataset).”
Is this the analyze in excel feature that’s only in the service ? Or is it connecting to excel files as a dataset?
Nikola
Hi David,
No, not connecting to Excel files as a data source. Simply said, Fields param will work ONLY in Power BI, so if you try to consume Power BI model from Excel, they won’t be available. Hope this clarifies your question.
Anders
Hi,
Question, setting this to false on all columns would mean none of the columns would be available for the excel users, right?
Is there a way to set this on table level, so that the developers would be able to see the table, but not the Excel users?
Nikola
Hi Anders,
That’s correct, setting IsAvailableInMDX to false will prevent any tool sending MDX queries (which Excel does) to have these columns available. Unfortunately, it can be set only on a column level.