

Once upon a time, there was a SQL Server! SQL Server was an emperor! It used to live alone, trying to help everyone in the “empire” satisfy their traditional, transactional data needs. After a while, since the plebs asked for additional “games”, SQL Server decided to hand over some special powers to its “senators” – SSAS, SSIS, and SSRS – each designed to support a specific requirement from empire inhabitants.
Hence, SSAS was assigned a task to enable the designing and building of powerful analytic semantic models, both multidimensional and tabular. SSIS had to empower plebs with GUI way of implementing ETL processes, whereas the SSRS was projected to unleash creativity (well, let’s put it that way😉) and support building efficient and nice-looking business reports. They all lived together in peace and harmony…
And then, the clouds (pun intended) came!
The way plebs reacted was: hey, this is cheaper (although this could be questioned), flexible, and more scalable! The poor SQL Server was starting to lose its supremacy and territory – clouds were covering more and more space! SQL Server had to react. And, to adapt! Times were changing rapidly, so SQL Server had also to follow in these footsteps and adapt quickly. You know the “law” of natural selection – if a species is not adapted to its environment, it will not survive. Now, of course, there are still many alive “individuals” of the SQL Server “species” for it to become extinct, but the change was inevitable.
The evolution started and, as a result, SQL Server can now be used in different cloud flavors.
Disclaimer: Although SQL Server in the cloud can be used across numerous cloud service providers (i.e. AWS, GCP), in this article, we are examining Azure offerings only
Depending on which cloud service model you choose (IaaS, PaaS, or SaaS), common SQL Server workloads can be leveraged by using three unique solutions:
- SQL Server on Azure VM – IaaS solution
- Azure SQL Managed Instance – PaaS solution
- Azure SQL Database – PaaS solution
Before we proceed, here are two remarks from my side: the first, explaining differences between IaaS, PaaS, and SaaS is out of the scope of this article, so please go and read this article first. Second, as you might have noticed, there is no SQL Server offering as a SaaS solution. Until NOW! So, I’m aware that I’ve just spoiled my own article, and if you don’t want to read further to understand all the nitty-gritty details about SQL database in Fabric, you can leave now, knowing that the…
SQL database in Fabric is a “SaaS Azure SQL Database”…

Let’s try to break this down into WHAT, WHEN, and HOW of the SQL database in Fabric.
WHAT is a SQL database in Fabric?
Before we answer this question, let’s briefly examine our current options for storing the data in Microsoft Fabric.
From a conceptual point of view, all the data resides in OneLake – a central storage repository for your organizational data that relies on the concept of “one single copy” of the data that can be used across different processing engines without the need to move or duplicate data. From a technical point of view, the data can be stored in a lakehouse, warehouse, eventhouse (KQL database), or Power BI semantic model (if we are talking only about the data written natively to OneLake by using Fabric engines). There are additional concepts, such as shortcuts, for example, that enable the unification of the data that resides in a different lakehouse, or even outside of Fabric (i.e. ADLS Gen2, S3, GCP, Dataverse, Snowflake).
However, let’s focus on the former – understanding various workloads with native Fabric engines, namely those that are responsible for handling batch data (lakehouse, warehouse). There are two key considerations to keep in mind regarding lakehouses and warehouses in Fabric:
- They both rely on MPP (massively parallel processing) architecture – in simple words, this means that the data is distributed across multiple nodes, and when the query needs the data, the query will be broken into smaller chunks, and multiple nodes will work in parallel to retrieve the required data. In MPP, the main focus is on the speed of data reading operations
- The default storage format in Microsoft Fabric is Parquet (or Delta Parquet, as Microsoft calls it, although I don’t like this name😀). I wrote about the Parquet format in more detail in this article. In a nutshell, Parquet stores the data in a columnar, highly compressed format, which is extremely suitable for analytical workloads. But, one of the Parquet characteristics is that it’s immutable – meaning when you change the data in the underlying table, the existing Parquet file, in most cases, can’t be modified to reflect this change. In this case, a new version of the Parquet file is created, and the delta log keeps track of all the versions. This is a great feature – in case you are not using Parquet for OLTP (Online Transactional Processing) scenarios, where data is frequently written and/or updated
Now, let’s get back to the previous point: SQL database in Fabric is a SaaS Azure SQL DB…Generally speaking, in SaaS solutions, “everything just works” (or at least should work) – without (too much) intervention from your side.
In the context of the SQL database in Fabric, creating a database is probably the most straightforward process of database creation you will ever experience, as I’ll show you in the “HOW TO” section of this article. From that point, everything happens automatically: the database will be automatically configured and will automatically scale both in terms of compute resources and storage. In addition, database backups are performed automatically, indexing also happens the same way, as well as all patches and software/hardware fixes. You want more? No more complex firewall rules and permission settings – this time, everything is done via Fabric workspace roles and item permissions, while the well-known SQL native features allow for more granular control.
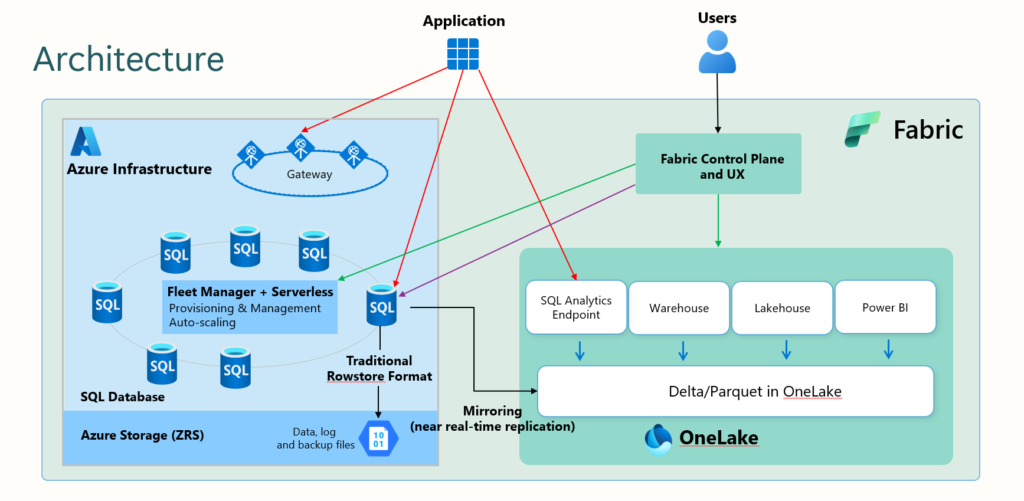
To wrap up the answer to a question: WHAT is a SQL database in Fabric? It’s an easy-to-setup, SaaS operational database, that automatically scales and automatically integrates with other Microsoft Fabric workloads.
WHEN to use SQL database in Fabric?
Ok, if you have ever read about Fabric, you’ve definitely realized that Fabric is all about the options. For example, you can ingest the data by leveraging notebooks, Dataflows Gen2, or Copy data activity in the Fabric pipeline. You can apply transformations by using T-SQL, Dataflows Gen2, or notebooks. The list goes on, as essentially any task can be done in multiple different ways.
Going back to the previous paragraph, and if we talk about the options, how many options are there for storing operational data in Fabric? 0…Zero…Nada…Ok, you can argue that Fabric is sold as “an end-to-end analytics platform” and is not meant to be used for operational data. However, business needs to leverage this operational data to uncover some insights from it. This brings us (again) to the scenario where you need to ingest that data into Fabric and start doing some analytics “magic” with it.
Since we learned that SQL database in Fabric is a SaaS solution for operational data, that is built into the Microsoft Fabric ecosystem, now all you need to start working with transactional data is – the name of the database (credit goes to my friend Ben Weissman, with whom I’m currently writing a book “Fundamentals of Microsoft Fabric” for O’Reilly).
No provisioning resources, handling security and access permissions, managing networks, or having a separate bill for this service…Everything is automatically managed and configured for you – the “beauty” of the SaaS, right😀?
And it’s not only that – part of this concept of “unification,” which is the key mantra of Fabric, is that your operational data is automatically replicated in near-real-time into OneLake as a delta table! How cool is that! This means, from that point, your data can be consumed by any Fabric workload downstream – including, but not limited to – cross-database queries, to combine your operational data with the data stored in the lakehouse/warehouse, or Direct Lake queries for your Power BI semantic models.
In addition, you might leverage the GraphQL item in Fabric to read and modify the data in the SQL database in Fabric, which is a huge boost for application developers. I cover the GraphQL feature in more detail in a separate article.
To wrap up and try to list key reasons WHEN you should consider SQL database in Fabric as the option:
- Dealing with transactional data
- T-SQL as the language of choice
- No provisioning, configuring, and managing the resource
- Source control as part of Fabric
- Seamless integration with other Fabric workloads
HOW to use SQL database in Fabric?
Ok, enough theory, let’s see SQL database in Fabric in action! I’ll start with opening a new Fabric experience, called Databases:
I’ll then choose to create a new SQL Database, which I’ll call FabricSQLDBDemo. And, that’s literally it! Have you ever created a database in such an easy way?! After a few seconds, I’ll find myself in the explorer view:
Note: If you don’t see the option to create a SQL database in Fabric, you might first go to the Admin portal and enable SQL Database in the Tenant settings.
Let’s now insert some data in our database and create a few additional database objects. The following code will create a Customer table:
CREATE TABLE [dbo].[Customer] ( [Id] INT NOT NULL PRIMARY KEY, [FirstName] VARCHAR(100) NOT NULL, [LastName] VARCHAR(100) NOT NULL, [Email] VARCHAR(100) NOT NULL ); GO
Now, let’s insert a few rows into this table:
INSERT INTO [dbo].[Customer]
VALUES (1,'John','Doe','johndoe@email.com')
, (2,'Jane','Does','janedoes@email.com')
, (3,'Marry','Poppins','mpoppins@email.com')
, (4,'Angela','Adams','aadams@email.com')
, (5,'Alex','Miles','amiles@email.com')
GO
I can also create other database objects, such as views, functions, and stored procedures. Let’s create a simple stored procedure for updating the customer email address:
CREATE PROCEDURE [dbo].[sp_updateCustEmail] ( @custId int , @email varchar(100) ) AS BEGIN UPDATE dbo.Customer SET Email = @email WHERE Id = @custId END GO;
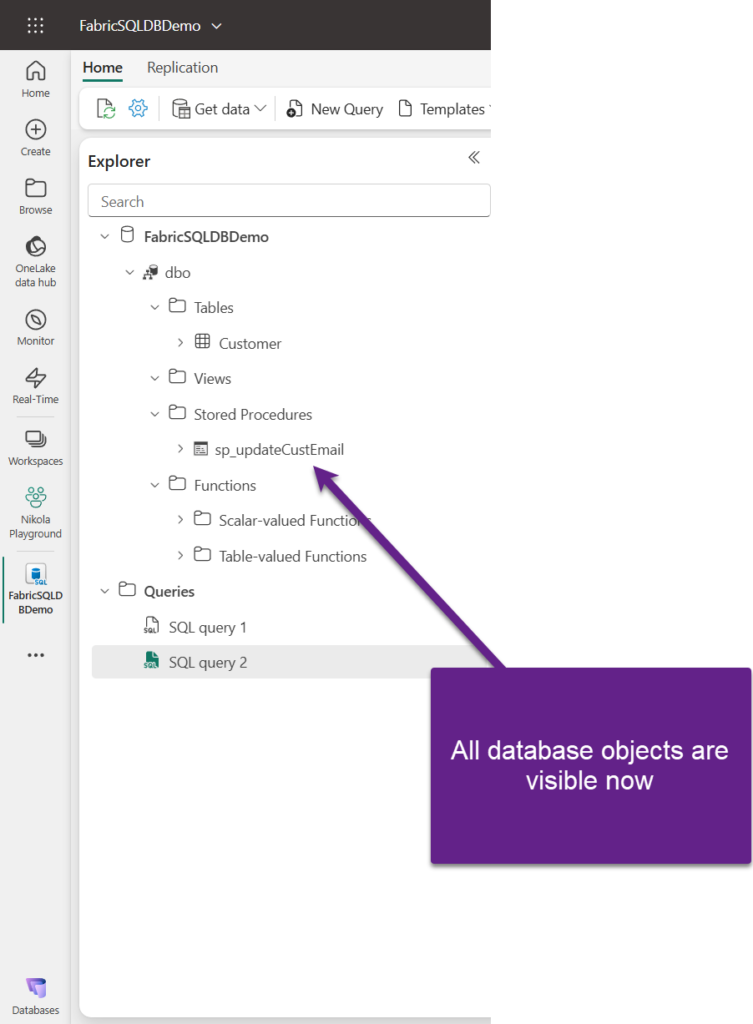
As you may see in the following illustration, all the database objects we created so far are available from the explorer:
That’s nice, but what happens inside the Fabric workspace once we start working with the SQL database in Fabric? Let’s go and quickly check this.
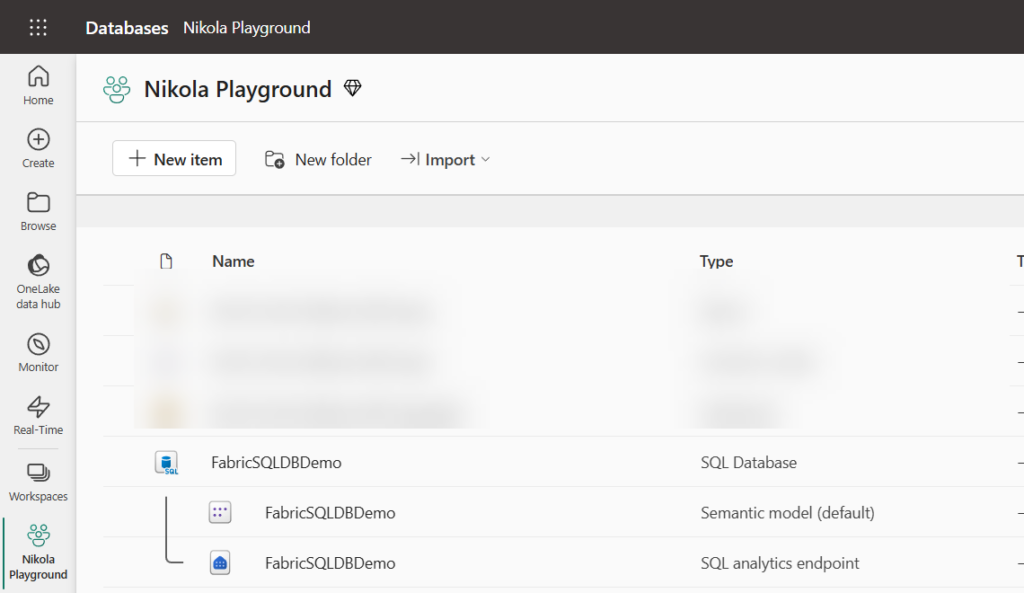
There is a new item (or items, to be more precise) in the workspace. Aside from the SQL Database itself, we also got SQL Analytics Endpoint, which exposes operational data as delta tables and enables querying from other Fabric engines, as well as the default semantic model, which is a well-known “annoying” companion of other Fabric artifacts, such as the lakehouse or warehouse.
Before we dive into this, let’s examine new options that SQL database in Fabric introduced compared to the lakehouse/warehouse. On the top, there are two tabs: Replication and Security.
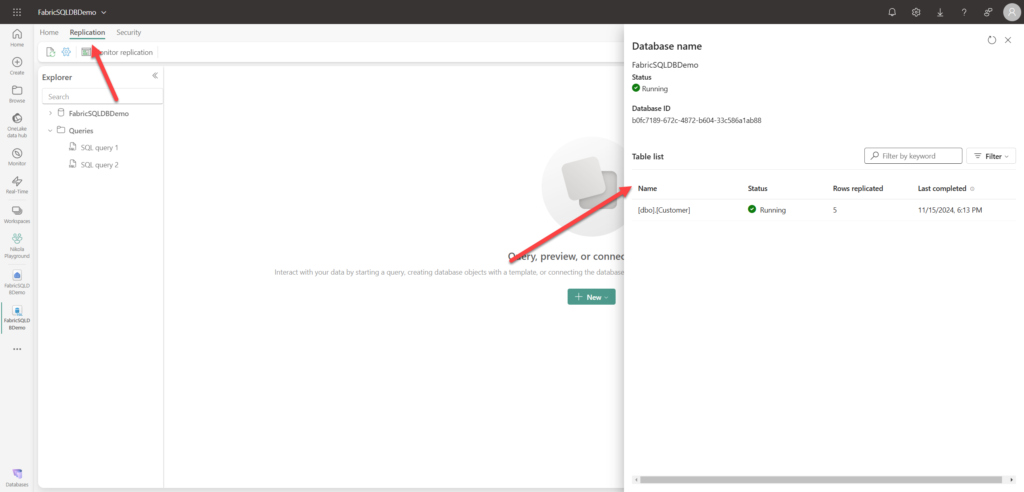
Replication provides the information about the process of replicating tables into OneLake:
From the UI, you can also manage SQL security and define new roles. Finally, from the Home tab, you can obtain the Performance summary information, which may come in very handy when troubleshooting the performance of your SQL database item:
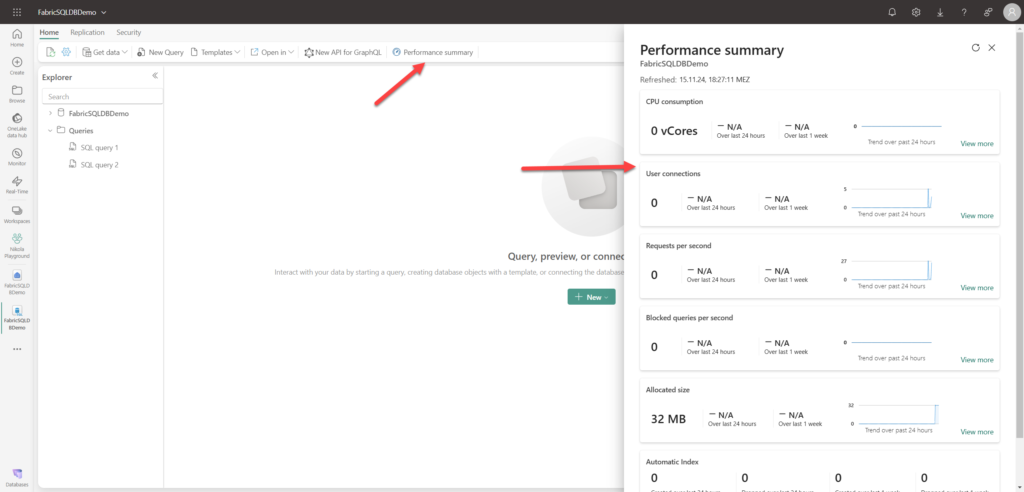
Since my database was just created and I have only a small single table in it, this performance summary doesn’t help a lot. However, in real-life scenarios, this can really be a huge thing.
The next thing I want to test is the promise of “near-real-time” data replication. So, I’ll go back to my database and execute the stored procedure, which updates the customer email. Then, let’s check how long it takes for this update to be reflected in OneLake.
exec sp_updateCustEmail @custId = 1 , @email = 'johndoe_updated@email.com'
Note: At this moment, in some regions, there is a bug that automatically concatenates the schema name as a prefix to the table name, so my table is called: dbo.dbo_Customer. As per Microsoft, this bug should be fixed by mid-December in all regions
Approximately 5 minutes later, this change was reflected in the SQL Analytics Endpoint as well:
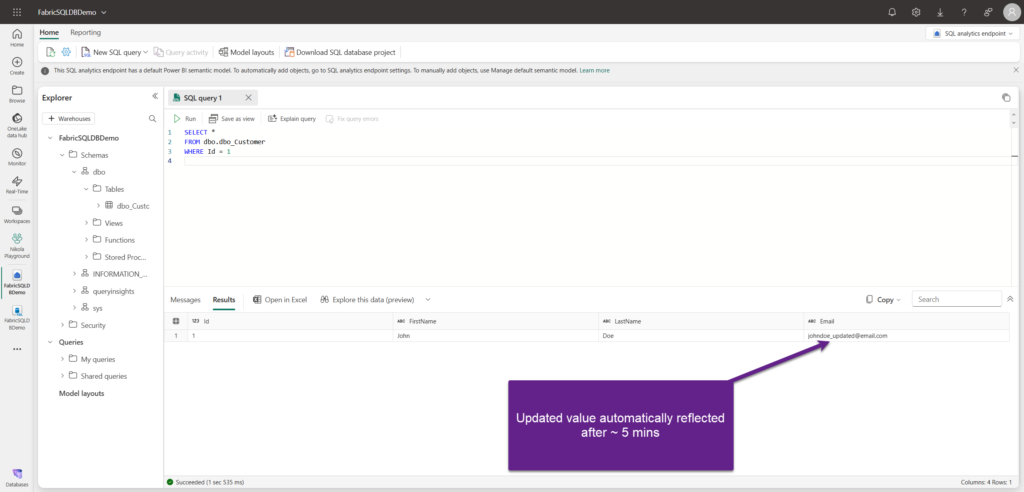
This is stored as a delta table in OneLake, and from here, every Fabric workload can leverage this data in the same way as other delta tables from lakehouses and/or warehouses. For example, I can write a cross-database query to combine the data from SQL database and the Fabric lakehouse:
SELECT * FROM FabricSQLDBDemo.dbo.dbo_Customer as cust INNER JOIN Nikola_Lakehouse.dbo.factinternetsales as sales on sales.CustomerKey = cust.Id WHERE cust.Id = 1
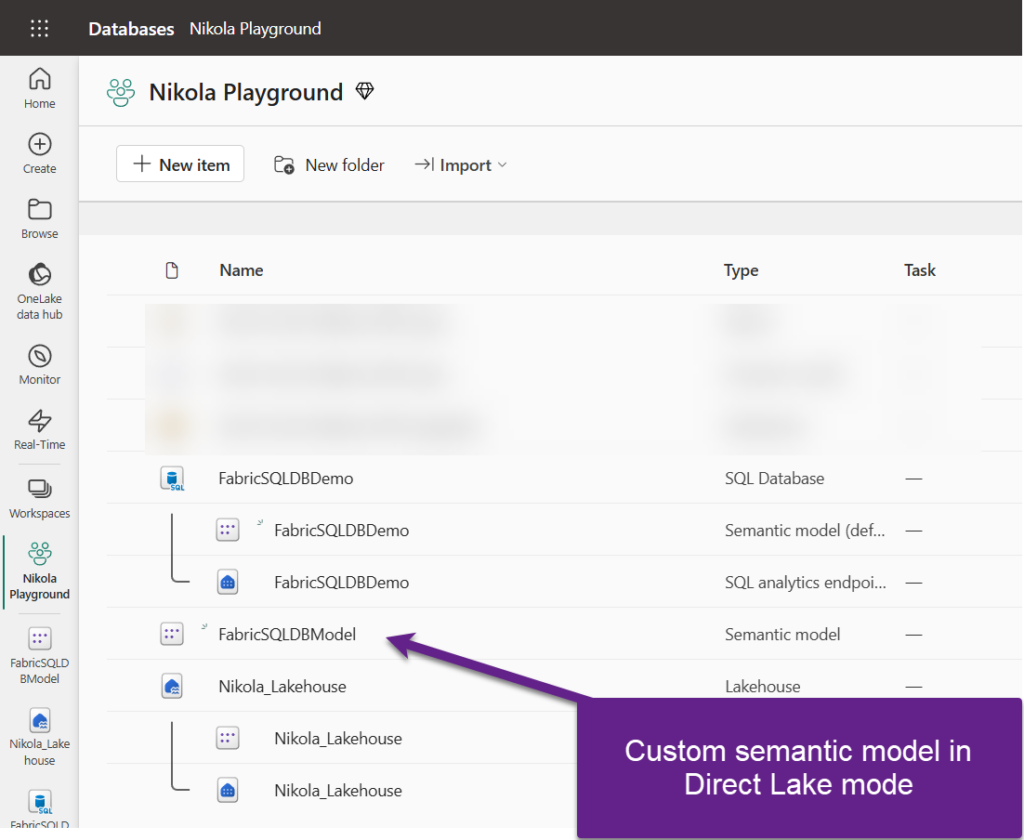
Or, I can create a custom semantic model in Direct Lake mode, for the downstream consumption via Power BI reports:
SQL database in Fabric vs. Mirrored Azure SQL DB
Again, we are going back to options…At the moment of writing (November 2024), there IS already an option to leverage Azure SQL DB data in near-real-time in Fabric. It’s called Mirroring. If you are not sure what Mirroring is and how it works, I suggest you start by reading this article.
Now, the fair question would be: What is the difference between the mirrored SQL database in Fabric data vs. mirrored Azure SQL DB data? From a purely conceptual and technical point of view – there is no difference! In both scenarios, your operational data is replicated in near-real-time and stored as a delta table in OneLake, using the same technology under the hood.
The only difference is – who is taking care of the database itself. With Mirroring for Azure SQL DB, you are still in charge of the database (security, number of DTUs, managing costs, and scalability) because, don’t forget, it’s a PaaS offering. On the flip side, as a SaaS solution, the SQL database in Fabric is managed as part of the entire Fabric ecosystem, so it automatically scales and integrates with the development and analytics framework in Fabric, whereas costs are included in the single Fabric bill, depending on the number of capacity units purchased through your Fabric (F) license. Simply said, a SQL database in Fabric is considered just another item that consumes capacity units of your Fabric SKU (the same as pipelines, notebooks, and semantic models, to name a few).
Which one is better? I’m afraid there is no correct answer to this question, as it would be the same as trying to answer the question: is it better to sit in the back of the self-driving car vs. driving the car yourself…
What now for Datamarts?
Datamarts was one of the most significant announcements at Microsoft Build 2022 (May 2022). Back then, datamarts were labeled as “a self-service relational database for analytics”, supporting workloads up to 100 GB. Two and a half years later, datamarts are still in public preview without any hint about the eventual general availability date. And, to be honest, they never really got much “love” in real-life implementations.
Datamarts are powered in the backend by automatically provisioned, fully managed Azure SQL Database. Sounds familiar, right?
So, the fair question would be: what happens now with datamarts, since we are getting basically the same functionality (plus automatic replication to OneLake and many others) with SQL database in Fabric?
Risking that I might be wrong, I’d say that datamarts are currently a “dead man walking” and that it’s a matter of time before they are officially sunsetted.

Again, this is just my personal opinion, which is not based on any official or unofficial confirmation from Microsoft, but I simply see no point in keeping datamarts alive now that SQL database is part of the Fabric family.
Conclusion
If there was a single missing part in the Fabric puzzle, that was the option for efficiently storing operational data. Not only storing it, but simultaneously making it available for further integration with other components of the Fabric ecosystem.
SQL database in Fabric aims to fill this void and provide hassle-free setup and management, thus enabling Fabric users to switch their focus to extracting insights from the operational data in a more convenient way.
Will SQL database in Fabric become a default choice for organizations that are considering Microsoft Fabric implementation? It’s a tough one and depends on many different factors, such as the current setup (did the organization already invest in other solutions for storing operational data), common data workloads (does the organization leverage operational data for analytics or not), and skillset of the team (what if the entire team is built around Python skills?), to name a few. In any case, it’s nice to have another option, and from that perspective, we should welcome SQL database in Fabric as a breath of fresh air.
Thanks for reading!
Last Updated on November 19, 2024 by Nikola



Vivek
Some day OLTP, OLAP, MPP will all become one and rule the empire singlehandedly! 😀
Nikola
Hahahaha, good one!
Bryan
Dataverse no sería igual una solución de datos OLTP SaaS? Igual con Fabric Link para el análisis casi en tiempo real
Nalaka Wanniarachchi
Nice Article Nikola !!
Nikola
Thanks mate!
Sudarshan
Hi Nikola, I’m unable to Fabric database in workload as well as in preview option in tenant setting
Nikola
Hi Sudarshan,
SQL database in Fabric is being rolled out to different regions with some latency, so it might happen that your region still has to wait a little bit (probably no longer than mid of December).
Koen Verbeeck
I’d use the SQL DB for smaller DWH projects as well. No need for massive scale of the warehouse when dealing with small datasets. And you have better T-SQL support.
Nikola
100% spot on!
Wilson Man
Hi Nikola,
Fun article that I’d been meaning to read for a while now. Thanks for sharing.
One question: The article mentions that Parquet is immutable, which is a great feature for non-OLTP scenarios. However, a SQL database in Fabric is designed to be used for OLTP right? Will this not be a problem for the SQL database replication to the Fabric OneLake?
Nikola
That’s a great question! OLTP-part of the SQL database doesn’t store the data in Parquet, but in the regular Azure SQL DB format. Only “mirrored” part (SQL endpoint) exposes data in Parquet format, so that it’s compatible with other Fabric workloads. Hope this helps.
Time Traveller
Thanks for the article Nikola. I love the simplicity in explaining SQL Database in Fabric. I am now looking at Fabric in greater depth to possibly make use of it!
Jacek
Hi,
may SQL Database in Fabric eventually replace Dataverse for building Power Apps applications?
Nikola
Hi Jacek,
Well, it depends:)…But, generally, I can see a lot of companies switching from Dataverse to SQL DB in Fabric because of easier integration.