

Since Microsoft Fabric public announcement in May 2023, there have been many blogs, videos, articles (I also wrote a few), and sessions, helping people understand various components of this, still-fresh SaaS data platform offering from Microsoft. As I’ve been in touch with Microsoft Fabric since its early days in private preview, and lately also been involved in multiple PoCs for different clients, there are certain “points of confusion” that can be singled out based on the experience so far.
Probably the biggest confusion is: should I use a lakehouse or warehouse in Fabric? Or, what is the difference between Direct Lake and DirectQuery mode for Power BI reports?
And, while these two points mentioned above are of paramount importance to clarify, in this article I’ll focus on explaining another potential caveat, which is relevant when working with the lakehouse in Microsoft Fabric.
Setting the stage – what are Tables and what are Files?
I will assume that you’ve already created a lakehouse in the Microsoft Fabric workspace, so I’ll skip this part and jump straight into explaining two main folders of the lakehouse:
Before we dive deeper into the Tables vs Files folders, let’s take a step back and explain two main table types in Spark. In case you missed it, Spark is the compute engine for processing the data in the Fabric lakehouse (opposite to Polaris engine which handles SQL workloads of the Fabric warehouse). Spark is not something brand new and exclusively related to Microsoft Fabric – on the contrary, it’s an open-source technology that’s been around for years.
Spark supports two types of tables…
- Managed tables – these are internal to Spark, which means that Spark is responsible for managing both data and metadata. Data resides in a storage directory, whereas the metadata is located in a metastore and includes information about all the objects, such as databases, tables, views, partitions, etc. The key thing to keep in mind here: when you drop a managed table, you lose everything! Both data and metadata are gone!
- Unmanaged (external) tables – In this case, Spark handles metadata only. You are responsible for specifying the location where the data is stored. Unlike in the previous scenario, if you drop an unmanaged table, only the metadata is gone (your data will still exist in the external location).
Going back to the Tables vs Files folders comparison, there are a few more nuances to be aware of:
Tables folder in the Fabric lakehouse
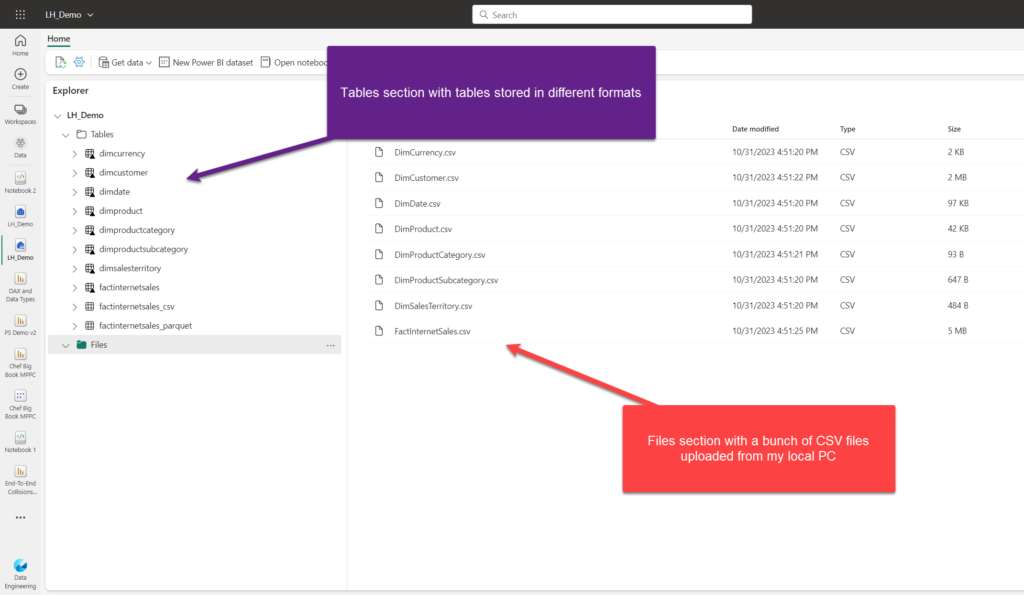
Tables folder represents the managed area of the lake. You can store tables in various formats here: so, it’s not only Delta, but Parquet and CSV as well. However, there are certain limitations if you use non-delta formats, so stay tuned:)
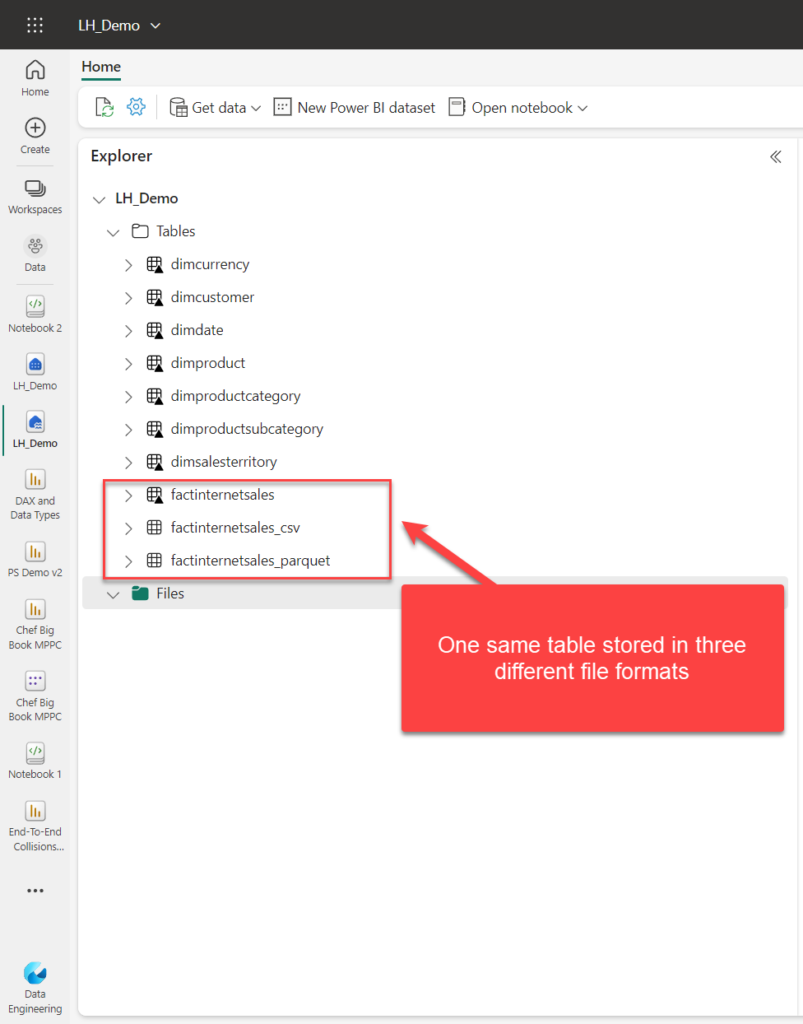
In the above illustration, I’ve created three versions of the same table: one with the small triangle in the bottom right corner of the table icon is in Delta format. I also have the same data available as csv and Parquet. If you are wondering what’s the difference between Parquet and Delta file formats, I have you covered in this article.
As you may notice in the following screenshot, the file type doesn’t affect the managed vs unmanaged table distinction we discussed previously:

On the other hand, if I expand the Properties pane of the original FactInternetSales csv file, stored in the Files folder, I see different information:
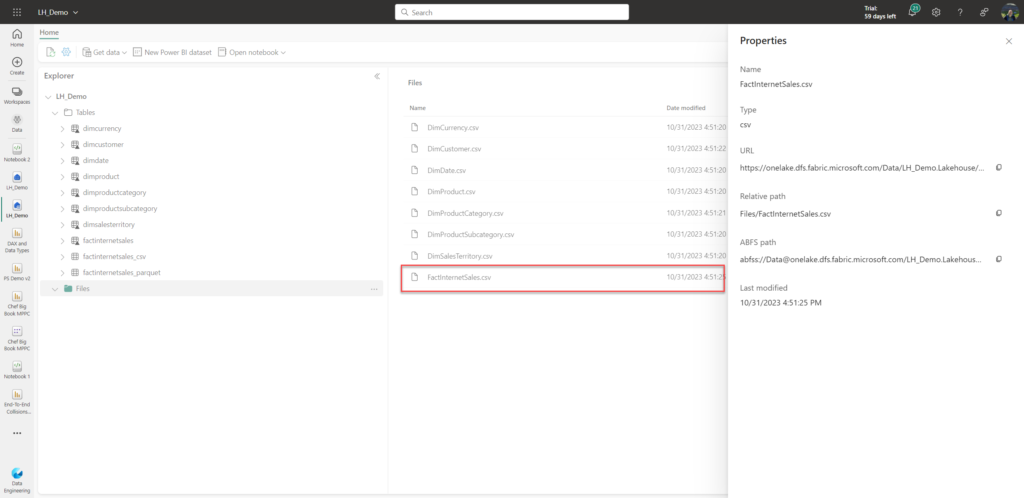
Files folder represents the unmanaged section of the lakehouse.
This means, you can store literally any type of file here: not only CSVs, but also images, videos, and so on.
Nuances to keep in mind…
Now, remember when I told you that there are some nuances to keep in mind when creating tables in the Tables folder? Despite having the possibility to create non-delta formats, a trade-off is that these tables will not be available for querying via the SQL endpoint provided by the Fabric lakehouse, nor for the Direct Lake scenarios with Power BI reports.

Creating managed and external tables in Microsoft Fabric
Before I show you different ways to create both managed and external tables in Microsoft Fabric, one more important thing to keep in mind:
- You may create an external table, but if it points to the /Tables folder in the lakehouse, Fabric will still consider it as an internal table
1. Creating a Managed table from the user interface
This is the simplest and most straightforward way.
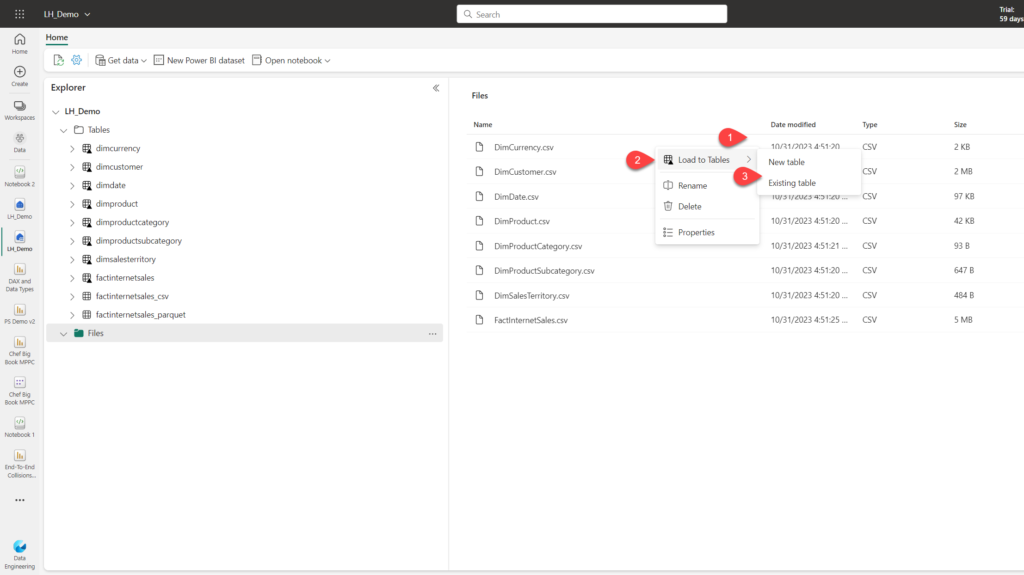
Just click on three dots next to the file name, choose the Load to Tables option, and then specify if you want to create a new table, or overwrite the existing one. This option will create a Delta table by default (there is no option to change the file format).
2. Creating a Managed table using saveAsTable()
This method lets you define the format of the table other than Delta.
#Load data
df = spark.read.format("csv").option("header","true").load("Files/FactInternetSales.csv")
# df now is a Spark DataFrame containing CSV data from "Files/FactInternetSales.csv".
# Managed Delta table using saveAsTable()
df.write.format("delta").mode("overwrite").saveAsTable("FactInternetSales")
The last line of the code in the Notebook lets you specify the format. So, instead of delta, I could have also used Parquet or csv.
3. Creating a Managed table using SparkSQL
If you are coming from a SQL background (like me), you may feel more comfortable leveraging SQL skills.
%%sql CREATE TABLE IF NOT EXISTS FactInternetSales USING DELTA AS SELECT * FROM FactInternetSales_view
Or, if you want to start from scratch, by using a well-known INSERT INTO statement:
%%sql CREATE TABLE FactInternetSales ( CustomerID STRING, ProductID STRING, CurrencyID STRING, SalesAmount STRING, .... ) USING DELTA; INSERT INTO FactInternetSales SELECT * FROM FactInternetSales_view;
4. Creating a Managed table using Save()
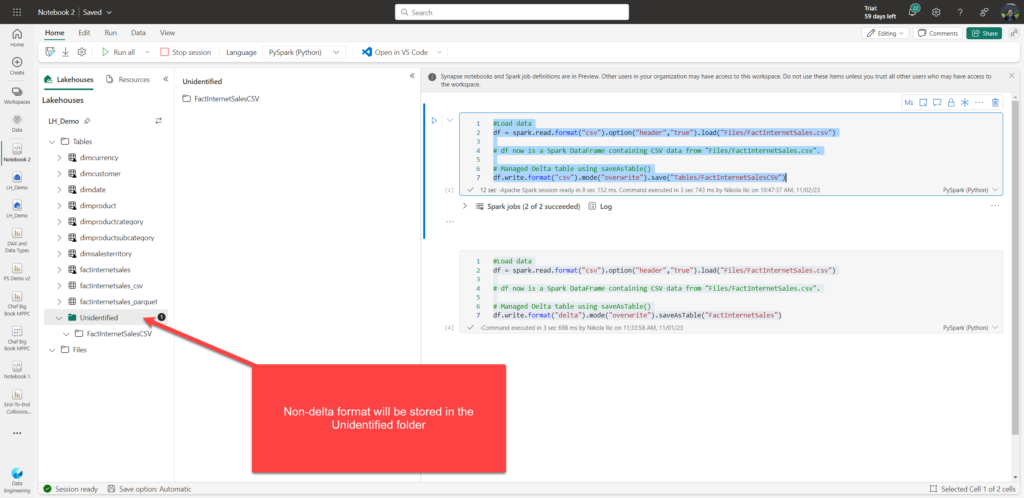
This one is very similar to option 2 (SaveAsTable), but with one important difference: it will work only for the delta format! If you try to save in non-delta format, a table will be stored in the Unidentified folder:
#Load data
df = spark.read.format("csv").option("header","true").load("Files/FactInternetSales.csv")
# df now is a Spark DataFrame containing CSV data from "Files/FactInternetSales.csv".
# CSV table using save()
df.write.format("csv").mode("overwrite").save("Tables/FactInternetSalesCSV")
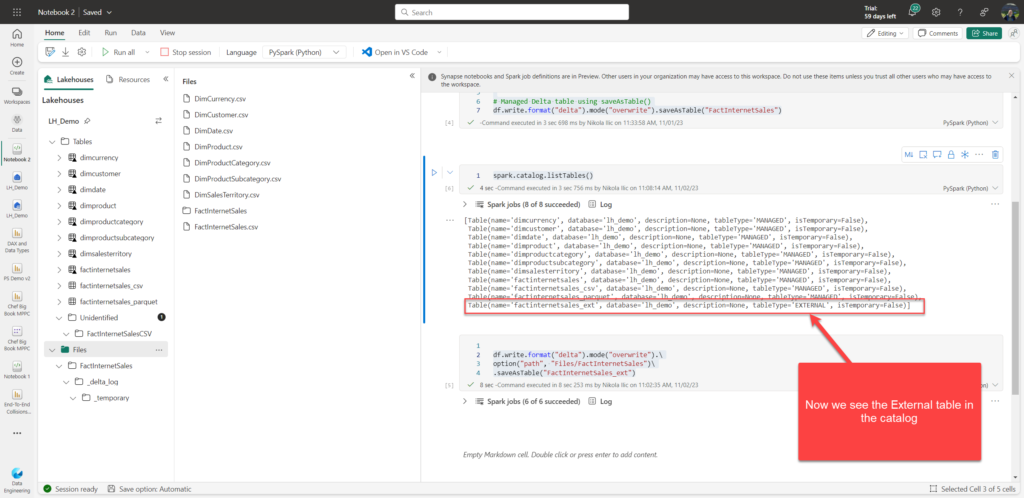
You can always check all the tables in the Spark catalog, by running the following command:
spark.catalog.listTables()
This will return all the tables from the catalog, including their type:

Finally, if you need a more in-depth view of the specific table, you can execute the following SparkSQL command to retrieve the detailed information:
%%sql DESCRIBE EXTENDED LH_Demo.FactInternetSales

5. Creating an External table using SaveAsTable()
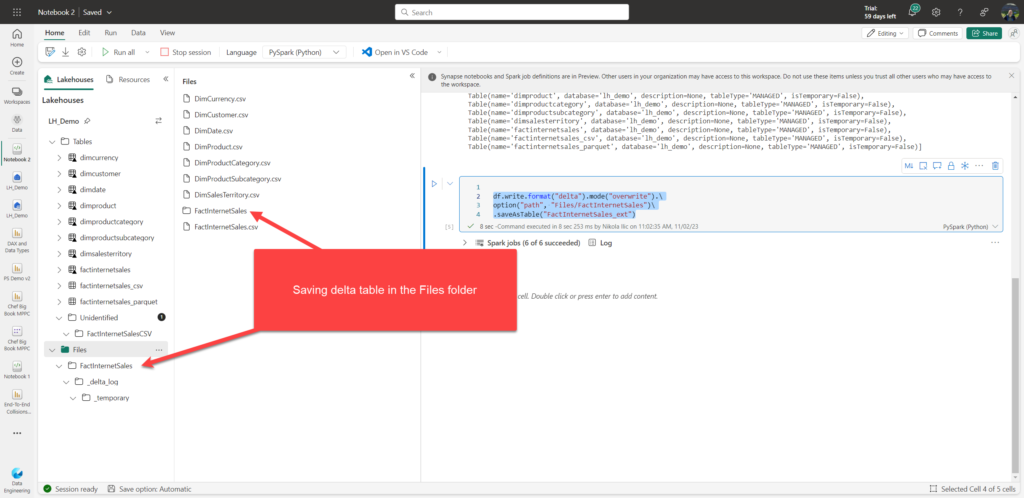
Similar to creating a Managed table using this method, we can expand the PySpark code to include additional parameter for the file path:
df.write.format("delta").mode("overwrite").\
option("path", "Files/FactInternetSales")\
.saveAsTable("FactInternetSales_ext")
By using the same approach, I could have saved this table by accessing other locations, such as ADLS Gen2, for example.
Once I list the tables in the catalog, the newly created external table is also included in the list:
6. Creating an external table using SparkSQL
This one is again very similar to creating a managed table. The only difference is that we must include an additional OPTIONS parameter when executing the INSERT INTO statement:
%%sql CREATE TABLE FactInternetSales_ext ( CustomerID STRING, ProductID STRING, CurrencyID STRING, SalesAmount STRING, .... ) USING DELTA OPTIONS (path 'Files/FactInternetSales_ext'); INSERT INTO FactInternetSales_ext SELECT * FROM FactInternetSales_view;
Dropping the external table
As we’ve already mentioned at the beginning of this article, a key distinction between Managed and External tables is that, in case you drop the external table, only metadata will be removed, but the “real” data will stay untouched in the external location.
Let me run the following command to drop an external table we’ve just created:
%%sql DROP TABLE LH_Demo.factinternetsales_ext
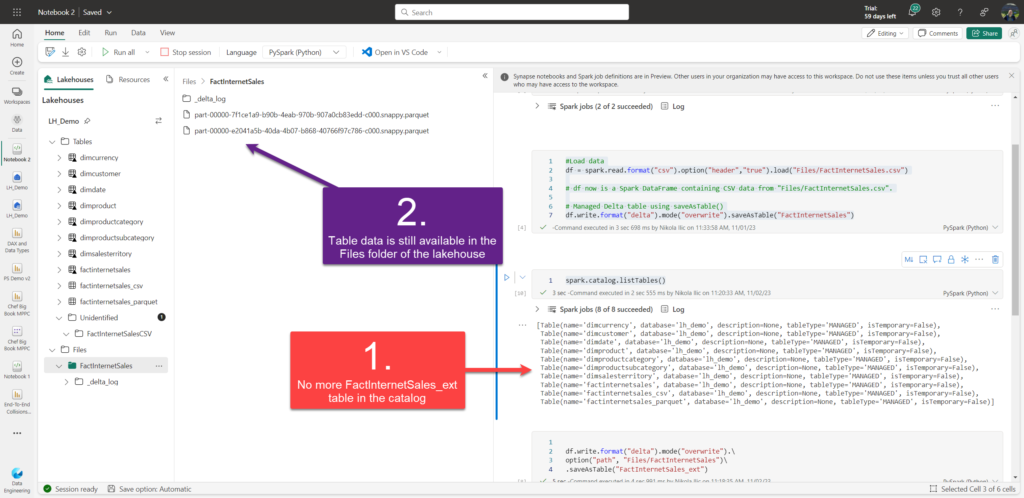
As you may see, there is no more FactInternetSales_ext table in the catalog (metadata has been removed), but the “real” data is still available in the external location (in this case, in the Files folder of the lakehouse).
Conclusion
Working with tables in the Microsoft Fabric lakehouse may look like a straightforward task – however, there are many nuances to be aware of before you decide to go one way or another. Additionally, it’s good to know that there are multiple methods to achieve the same outcome (for example, using PySpark vs SparkSQL), although I would say that applies to Fabric in general – for almost every task, you can choose between various tools at your disposal.
Thanks for reading!
Last Updated on November 2, 2023 by Nikola


Michael
Thank you very much for your wonderful post.
However I tried to follow your tutorial and I do not understand several things:
1. When I click on a folder under /Files and say ‘Create Table’ a new table gets created this table is always managed. However when I delete the table the folder used to create it still remains. How was the table managed then? Does it mean that when i create a managed table from a folder in files all data is copied?
2. Using pyspark or pysql I was easily able to create a table in the /Tables section which is unmanaged/external. This table still resides in the /Tables section, I thought this section is supposed to be reserved for managed entitys exclusively.
3. If I click on a shortcut folder I can also create a managed table, how is this possible? Does the data get copied?
4. Is there any relation between building a table on a shortcut and the definitions of managed and unmanaged? so far it seems i was able to create both types of tables of a shortcut.
5. What is the use of an external table? It seems like i can always create a managed table off any type of data why would i ever create an unmanaged one? These freshly created managed tables can be deleted and the original data source seems to still remain.
Martin
Creating external tables seems to not be working anymore. I’ve tried several approaches and I keep getting an error message saying “Only managed tables are supported”.
Mohammad
Seems like
comment on column is not supported for tables in lakehouse till now, is there any workarounds?
Thanks