
DP-500 Table of contents
In the previous articles of the series, we’ve explained what happens when you hit the Publish button in Power BI Desktop. Assuming that you’re not using a Live connection mode, once you publish the report, two artifacts will be deployed to a destination workspace – the report itself, but also a dataset on which the report is based. Then, this dataset can be reused again as the source for other reports, but we will cover this in the next sections.
However, besides these two artifacts, report and dataset, there are also additional options available for handling your analytic workloads. One of these options is a Dataflow. It’s a very important concept, especially in enterprise-grade implementations, and as such, deserves a thorough understanding and explanation.

Let’s first demystify what a dataflow is. In most simple words, a dataflow is a set of tables and/or queries containing the data, and that set of tables/queries can be reused across multiple reports within the organization. Think of a Date or Calendar table, that is basically an integral part of every reporting solution. Instead of using DAX code to create a Date table within each and every Power BI report, you can leverage Dataflows, create a Date table as a dataflow, and then reuse that table across all the reports.
It’s not just about reusability, but also about creating a single source of truth, so you can be sure that all your reports and downstream artifacts apply the same logic.
From a technical point of view, a Dataflow is nothing else but the CDM, or Common Data Model format, stored in the Azure Data Lake.
Dataflows use cases
Before I show you how to create dataflows, let’s first examine the possible use cases for dataflow:

- There is no proper data warehouse within the organization, or you don’t have direct access to it
- Extending the data from the data warehouse, by implementing an additional logical layer on top of it
- For slower data sources, dataflows may be a solution, because the data will be extracted only once, and then reused multiple times
- For data sources that you pay for – instead of connecting multiple times to this data source, you’ll connect only once
- Reducing the data source complexity – instead of connecting to multiple data source objects, and having all of them in the dependency circle, you can transform and prepare the data within the dataflow, thus reducing the overall complexity
- Horizontal data partition – meaning, you can create multiple dataflows based on the same data source. Then, let’s say that you have a group of users that needs to see the whole data – you can expose the dataflow that contains all the data to this specific group, while you can create additional dataflows, containing only a subset of the data, to other groups of users
It’s not all that rosy in the Dataflows world…
Ok, it’s not all that rosy in the dataflows world. No matter how powerful they are, there are also certain limitations to keep in mind if you decide to use dataflows in your enterprise reporting solutions.
First, and most important, dataflows are not and should not be a substitute for the data warehouse. A data warehouse should still be a central place for the organizational data workload needs, while dataflows should be considered as a supplement to a data warehouse.
The next limitation is the inability to use RLS. Then, if you’re operating in a shared capacity, meaning that your organization has to share the resources with others, you may run into performance issues with dataflows.
Finally, you can’t create Linked entities in a shared capacity. They CAN exist, but they have to be disabled for loading. In addition, computed entities can’t be created in shared capacity dataflows, while an incremental refresh is also not supported.
Ok, maybe you’ve noticed that I mentioned Linked and Computed entities previously. And, now, you’re probably wondering:
What are linked and computed entities?
So, let’s try to explain the different entity types that exist in the dataflows ecosystem.
First of all, let’s go one step back and understand how to create a dataflow in the first place.
Dataflows can’t be created from Power BI Desktop! That’s the first and most important thing to keep in mind. If not in the Power BI Desktop, then where? This time, no Tabular Editor or other external tools…You create a dataflow in the Power BI Service! And, for creating a dataflow, you’re going to use Power Query Online – which, more or less, works the same way as a “regular” Power Query in Power BI Desktop.
Now, my question to you is: have you ever used the Reference option in Power Query Desktop? Here is the short explanation: by using the Reference option, you are basically creating a new entity, which is referencing the original query, but you can then extend this new entity with some additional transformation steps. So, in this scenario, the original query, the original entity, is a prerequisite for this new query.
Understanding Computed entity
Now, if you choose to go this way in Power Query online, in the dataflows scenario, once you click on Reference, you are creating a Computed entity. I’ll give you one very simple, yet very commonly used example. Remember when we were explaining aggregating the data, and having the original, detailed table, together with aggregated version of this same data? That’s exactly what you can do with the computed entity in the dataflow.
Let me quickly show you what I’m talking about:
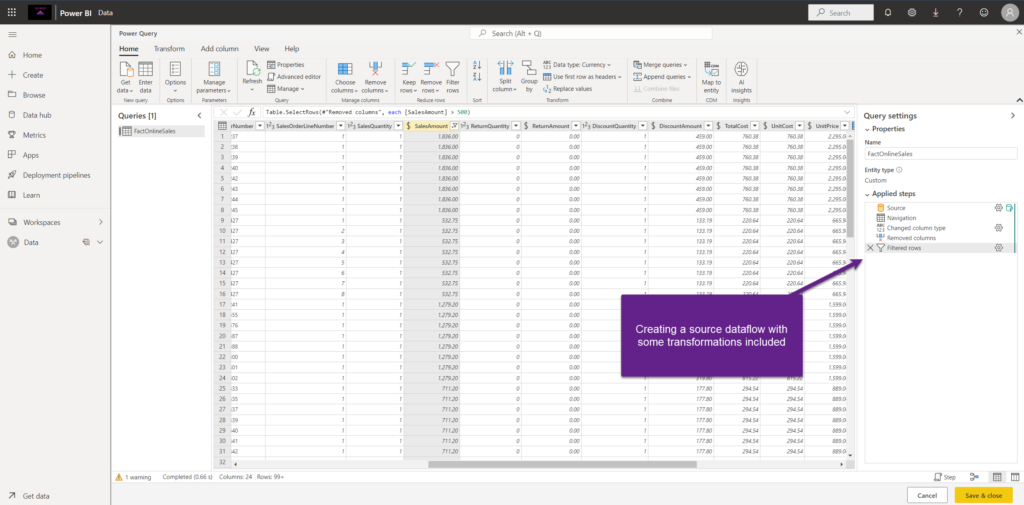
As the first step, I’ve created a new dataflow, which I’m going to use as the source dataflow for my computed entity. As you may notice, I’ve already applied certain transformation steps to this source dataflow – for example, I’ve changed the column data type, removed a few columns, and also filtered out some data.
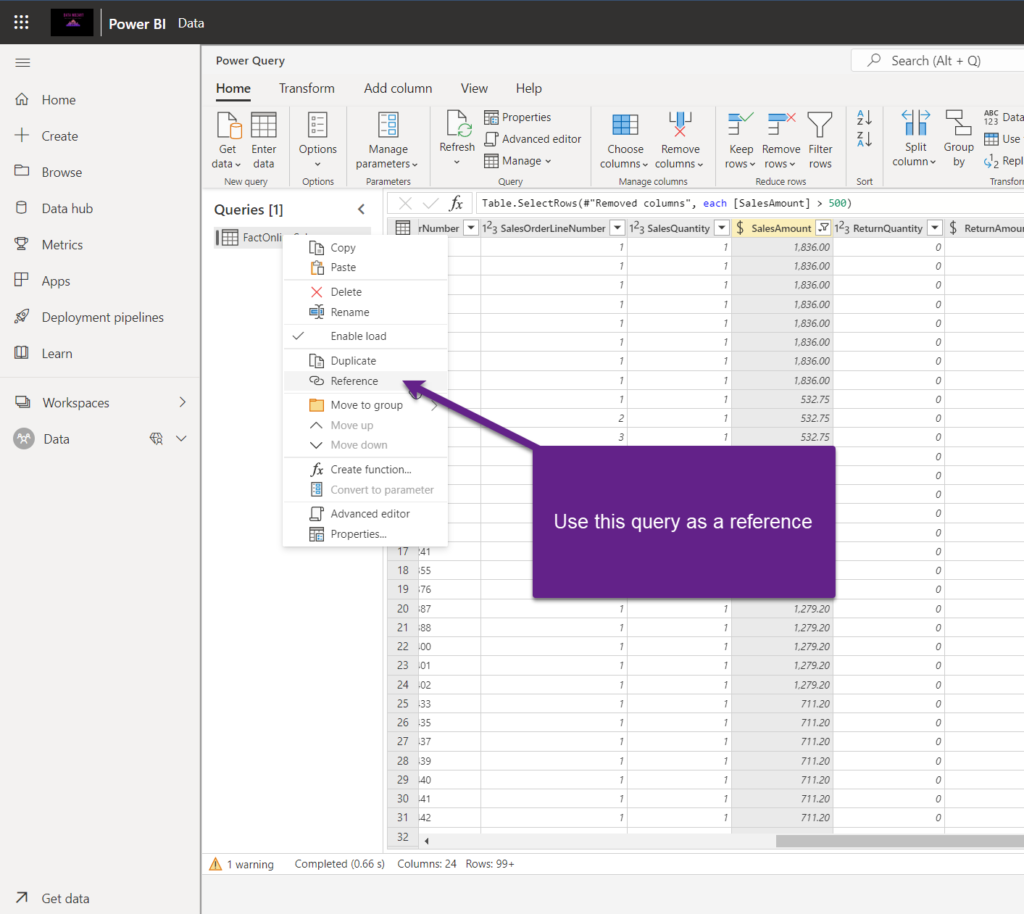
Now, I’ll use this source query as a reference for my computed entity – which means, this new entity will use the source query as a reference:
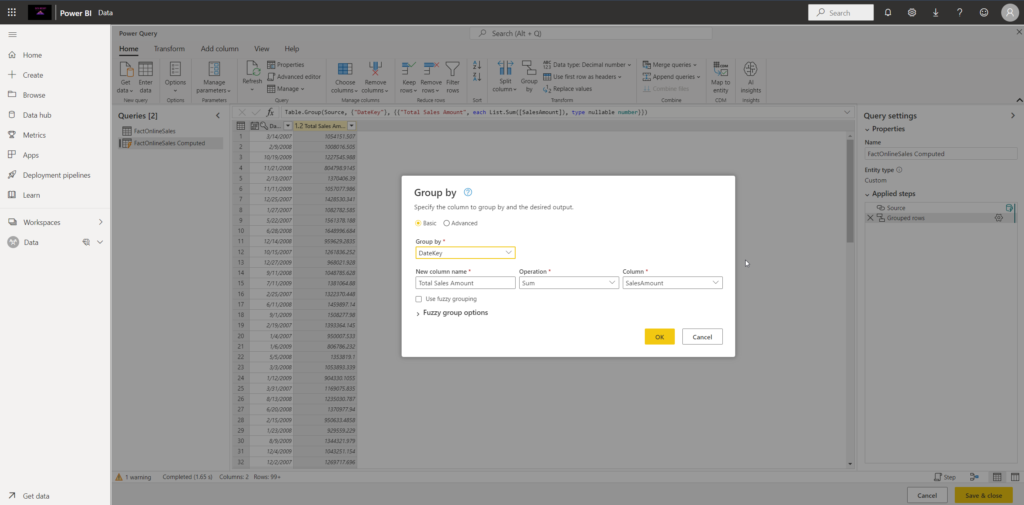
Let’s keep it simple and create a basic aggregation, that will calculate the total sales amount per date:
The only “sign” that this entity is different is the small lightning icon:
Now, you may think – ok, that’s also how it works in the Power BI Desktop version of Power Query. And, you’re almost right:) But, there are some subtle differences in the background, mainly related to the execution logic.
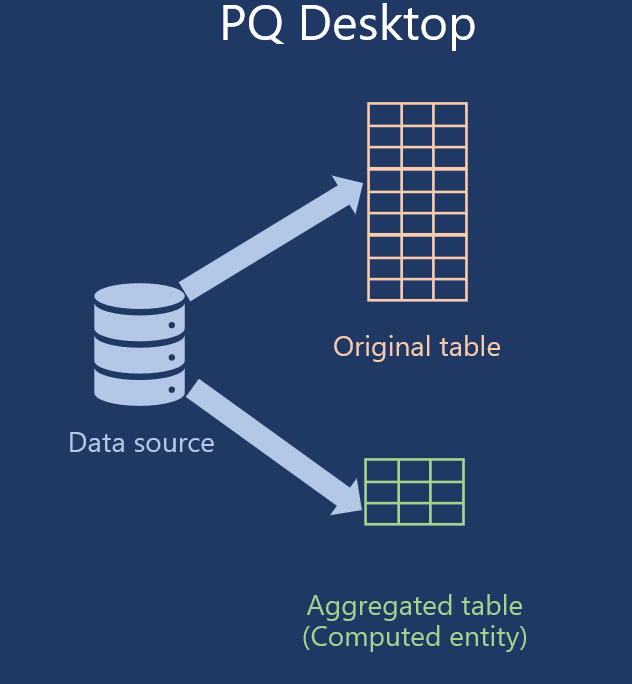
Power Query Desktop vs Power Query Online execution logic
Let’s say that you want to refresh your data in Power BI. In the “regular” Power Query, assuming that you have these two queries that we’ve created, both queries, so both detailed AND aggregated table, will be populated directly from the data source. Something like this:
On the other hand, it’s different with dataflows. The original query, in our case FactOnlineSales table, will be populated directly from the data source, and then it will be loaded into Azure Data Lake. Then, the next query, this computed entity, will target this one from the data lake, and not the original data source.
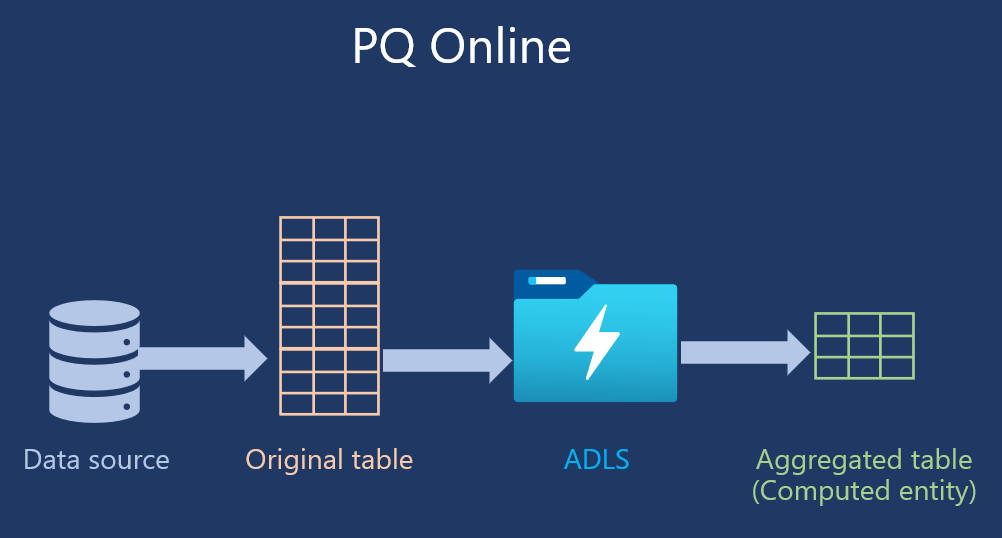
Once again, keep in mind that at this moment, creating computed entities is not supported in the shared capacities, so you need to have some kind of premium license.
Computed entity – with or without transformations?
Now that you know that computed entities should improve the data transformation performance, a legitimate question would be: should I apply all of my transformations on the computed entity or should I encapsulate them into the source entity?
As usual, it depends!
No data transformation for Text/CSV files
When you’re dealing with data sources that don’t support query folding (such as Text/CSV files), there’s no benefit in applying transformations when retrieving the data from these sources. Especially if we are talking about large data volumes.
So, you should simply load the data from the Text/CSV file to this source entity without applying any transformations. Then, computed entities can reference the source entity and apply necessary transformations on top of this source data.
You are now probably wondering, what’s the point in creating a source entity that simply loads the data from the source? However, in many cases, this approach makes sense, because if you reuse the source data across multiple entities, it reduces the load pressure on the data source. Computed entities are therefore very useful in those situations where you handle large data volumes, or when you are accessing data sources via the on-prem gateway, since using a computed entity will reduce the traffic on the gateway.
Transform for a SQL table

If your data source supports query folding, it would make sense to perform foldable transformations in the source entity because the query will be folded to the data source, and transformed data will be retrieved. Same as in the regular Power Query, this approach improves the overall performance. So, all common transformations that are part of the transformation logic of all the downstream computed entities, should be applied within the source entity. And, then, all additional, entity-specific transformations, should be applied on the computed entity.
Understanding Linked entity
Unlike in the previous case with the computed entity, where you’ll probably add some additional transformation logic on top of the source entity, as we did by aggregating the data, with a linked entity you don’t extend any transformation logic – you simply need a copy of the existing entity from another dataflow.
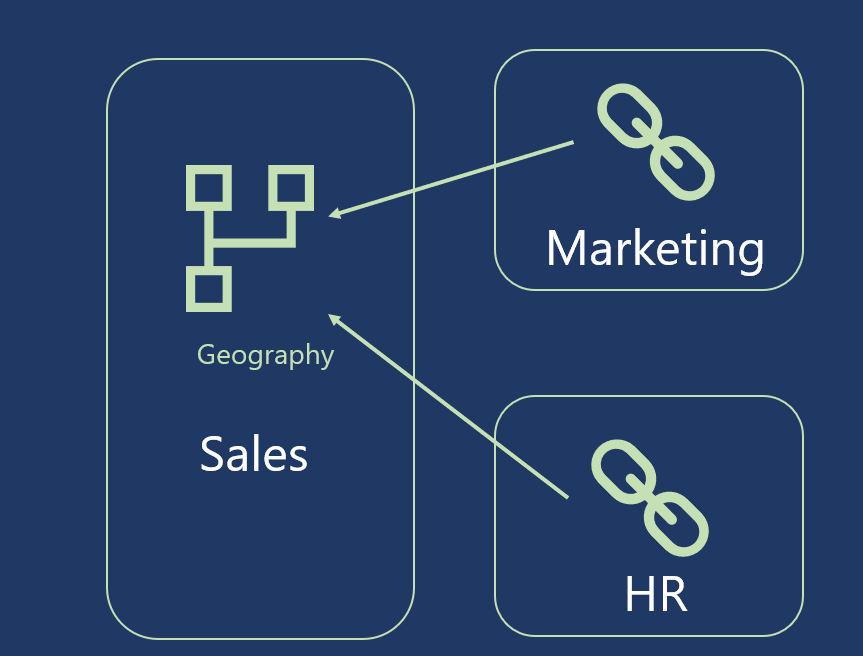
When would you use a linked entity in your Power BI solution? Well, let’s say that I’ve created a Geography entity in the Sales dataflow. And, this entity contains all the attributes I need – continent, country, city, zip code, and so on. Now, chances are that I’ll need this Geography data for other departments in my organization, like Marketing, HR, etc. Instead of creating the very same entity in each of these departments, I can simply use a copy of the existing entity, or just link to it from the current dataflow:
It’s fairly simple to create a linked entity in the dataflow:
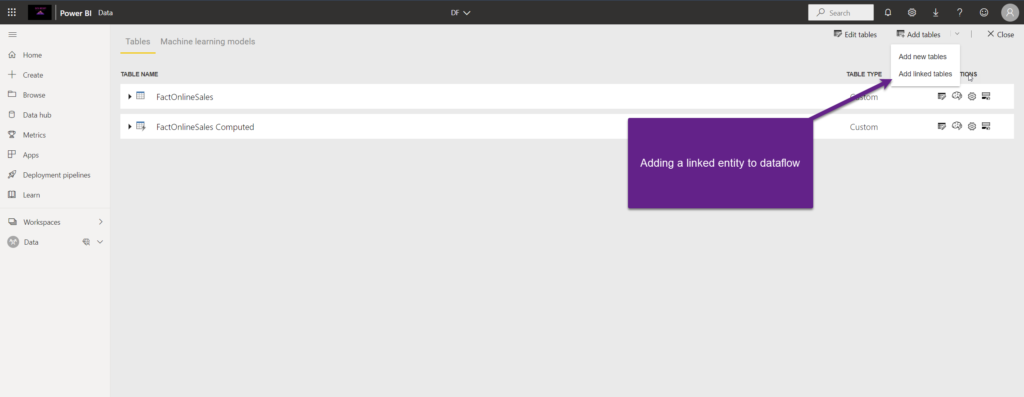
Because I’m just using a link to this entity, and not physically creating a new instance of this same entity, I can’t apply any additional transformation steps on top of the linked entity!
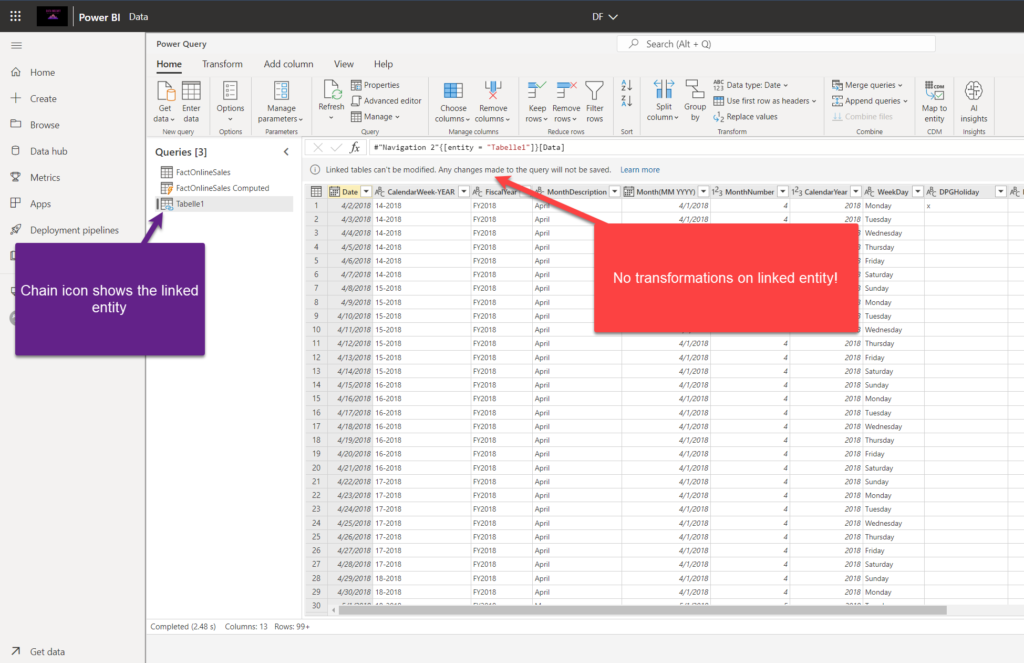
If anything has to be changed, you must go to the original instance of the entity and then apply desired modifications on it.
As already mentioned, if you’re operating on a Pro license, you can’t refresh the dataflow that contains the linked entity, unless this entity is disabled for loading.
Refresh logic in Power BI
The default refresh logic of linked entities depends on whether the source dataflow is in the same Power BI workspace as the destination dataflow.
Links between workspaces: Refresh for links from entities in different workspaces behaves like a link to an external data source.
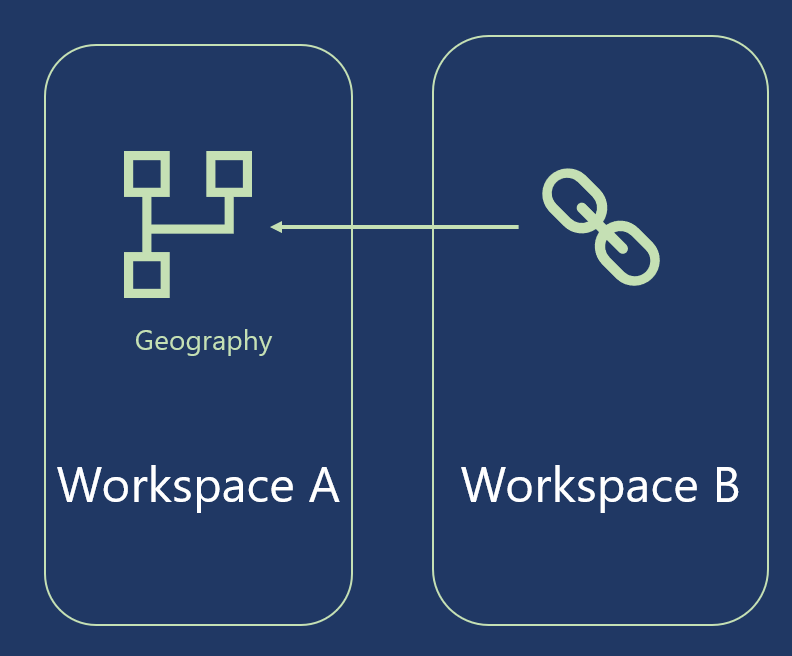
When the dataflow is refreshed, it takes the latest data for the entity from the source dataflow. If the source dataflow is refreshed, it doesn’t automatically affect the data in the destination dataflow.
Links in the same workspace: When data refresh occurs for a source dataflow, that event automatically triggers a refresh process for dependent entities in all destination dataflows in the same workspace, including any calculated entities based on them.

All other entities in the destination dataflow are refreshed according to the dataflow schedule. Entities that depend on more than one source refresh their data whenever any of their sources are refreshed successfully.
Dataflows vs Azure Data Factory
Maybe you’ve heard about Azure Data Factory, Microsoft’s robust cloud solution for performing ETL tasks. Moreover, you may have heard of ADF Wrangling dataflows, which is also powered by the Power Query online. Now, you are probably wondering: which one of these two should I use?
Of course, you can combine both within one solution, but here is a brief overview of the key characteristics and differences between Power BI dataflows and ADF wrangling dataflow:
| Feature | Power BI Dataflow | ADF Wrangling Dataflow |
|---|---|---|
| Sources | Huge number of sources | Only a few sources supported |
| Destinations | ADLS or Dataverse | Huge number of destinations |
| Power Query transformations | All Power Query functions | Limited set of functions |
| Scalability | Depends if there is a Premium and enhanced compute engine | High scalability |
Conclusion
Dataflows are one of the most powerful data modeling features in Power BI. By leveraging dataflows, you can significantly reduce the complexity of the data integration process and improve the overall efficiency of your Power BI data models.
However, don’t jump to a quick conclusion that dataflows can be a direct replacement for the enterprise data warehouse. Having a robust, scalable, and well-designed data warehouse is still the preferred way to go, but for the users that don’t have access to this data warehouse, dataflow can be this missing part to complete their Power BI data modeling puzzle.
Thanks for reading!
Last Updated on January 20, 2023 by Nikola


EL-FIGHA
The content of the article remains too thin compared to an ambitious title like “Everything you need to know”
Would it be possible to update the article by including the following points:
-Scenario where a workspace is connected to an ADLS Gen2
-Consumption of dataflows, especially in a datamart
-incremental update
– access permissions, in particular permission to modify a dataflow
Nikola
Thanks for your comment.
These are all valid points, but it would probably be a chapter in the book if I covered them all in one article:)…I’ll cover some of these topics in the next articles.
Jagadeesh
Created new dataflow using SQL server, need to refresh the dataset everytime after dataflow refresh or automatically the data will update on dataset?
In this case both dataflow and dataset schedule refresh is needed? even my dataset is only connected to dataflow?
Paulo Martins
Hi Nikola,
Thanks for the great article!!
Can you extend your comparison between Power Bi data flows and ADF wrangling data flow to consider Azure Synapse Data Flow?
I’m just surprised with the ADF limitations and curious to understand if Synapse is also very limited, which will make PBI dataflow the best option for most use cases.
Nikola
Hi Paulo,
Great suggestion! I’ll cover this in one of the next articles.
Best,
Nikola
Utkarsh
Thanks for putting this together. This is by far the most helpful explanation (for me at least) on granular details about the Dataflows.