
Microsoft Fabric is all about the options. The same task can be completed in multiple different ways. And, it doesn’t necessarily mean that one way is better than the other. Sometimes, it boils down to the skillset of the individuals in your organization performing the data task or maybe a personal preference. However, sometimes, these decisions might have a larger impact on the entire data platform workload. Hence, it is of paramount importance to understand the implications of choosing Option A vs. Option B, for example,to complete Task XYZ in Microsoft Fabric.
In this article, I will do my best to provide you with guidance on the most common Fabric dilemmas. Please bear in mind that the list of dilemmas is not definitive – I simply handpicked some of the challenges that Fabric practitioners face most frequently, and where I believe that such guidance would make the lives of these practitioners much easier in their day-to-day work with Microsoft Fabric.
General recommended practices and edge-case scenarios…
Before we proceed, an important disclaimer: the guidance I’m providing here is based on both my experience with implementing Microsoft Fabric in real-world scenarios, and the recommended practices provided by Microsoft.
Please keep in mind that the guidance relies on general recommended practices (I intentionally avoid using the phrase best practices, because the best is very hard to determine and agree on). The word general means that the practice I recommend should be used in most of the respective scenarios, but there will always be edge cases when the recommended practice is simply not the best solution. Therefore, you should always evaluate whether the general recommended practice makes sense in your specific use case.
Choosing the Analytical Engine

All Microsoft Fabric roads lead to OneLake! You’ve already learned that mantra. However, which road is right for you? Should you pick a lakehouse, a warehouse, or maybe an eventhouse for storing your data in OneLake? There are numerous factors to take into account, so let’s explore three that I consider most relevant: data volume, supported data formats, and supported programming languages.
Data volume
Let’s first talk about the data volume. Although there is no single number that differentiates small and big data, and you’ll probably find dozens of opinions in the various resources on the web or books, we often refer to big data as an extremely large and diverse collection of data that continuously grows over time. However, for the sake of setting boundaries when making decisions, we will consider big data anything above 5 TB of stored data, and 100+ GB of ingested data per day.
When choosing the optimal analytical engine in Microsoft Fabric, there is no such thing as the minimum amount of data suitable for a warehouse versus a lakehouse, or vice versa. In theory, you can store only a few records of data in any of the analytical stores in Fabric, but you’ll start reaping the benefits of Massively Parallel Processing (MPP) architectures, which are implemented in both Fabric lakehouse and Fabric warehouse, with large amounts of data only.
Explaining the details about MPP is beyond the scope of this article, but you can find more details here.
To wrap up – data volume shouldn’t be a determining factor when deciding which analytical engine to use, as each lakehouse, warehouse, and eventhouse, scales to support petabytes of data if necessary.
Supported data formats
When choosing a storage option in OneLake, you’ll need to first consider the data format. The table you see depicts supported data formats in the three Fabric analytical storages.
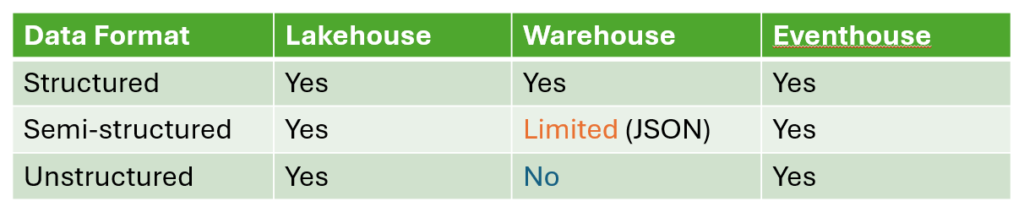
As you can see, both lakehouse and eventhouse support all data formats. So, the fair question would be: when should I use a lakehouse over an eventhouse?
The short answer is: whenever you need to handle any type of streaming, or event-based data, choose an eventhouse. A few examples of event-based data are: telemetry and log data, time series, data collected from IoT devices, etc.
Of course, the long answer to the question about Lakehouse vs. Eventhouse is more nuanced and depends on numerous factors, such as:
- Using data downstream – For example, if you are using Direct Lake mode for Power BI semantic models, data must be available in Delta format, which is not the case in the eventhouse (unless you enable the Eventhouse OneLake Availability feature)
- Optimizing storage cost – Generally speaking, storage is more expensive for eventhouse than for lakehouse, since eventhouses use OneLake Cache Storage to provide the fastest query response times at an additional cost, as described here. A point worth mentioning is that when you set the caching policy to move the data to cold storage in the eventhouse, it’s billed the same as regular OneLake storage. Hence, only keeping the data in the hot cache (which improves the query performance) will cost you more
- Processing streaming data – Eventhouse is optimized for processing streaming data (indexing and partitioning happen automatically), whereas processing streaming data using a lakehouse will force the creation of multiple small parquet files that must be vacuumed and optimized later, which can lead to increased capacity unit consumption. Explaining the vacuum and optimize operations is out of the scope of this article, but you can read more about it here
Supported programming languages
Let’s now examine how supported programming languages might affect the storage choice. This is undoubtedly one of the key factors when making a decision, not only about the analytical engine, but also when designing the entire Fabric architecture. The reason is obvious – let’s imagine that the entire data team in your organization consists of hard-core T-SQL developers. Would you force them to learn another programming language (Python, for example)? Or would you rather choose a Fabric component that plays to their strength?
The following table shows supported programming languages for both read and write operations.
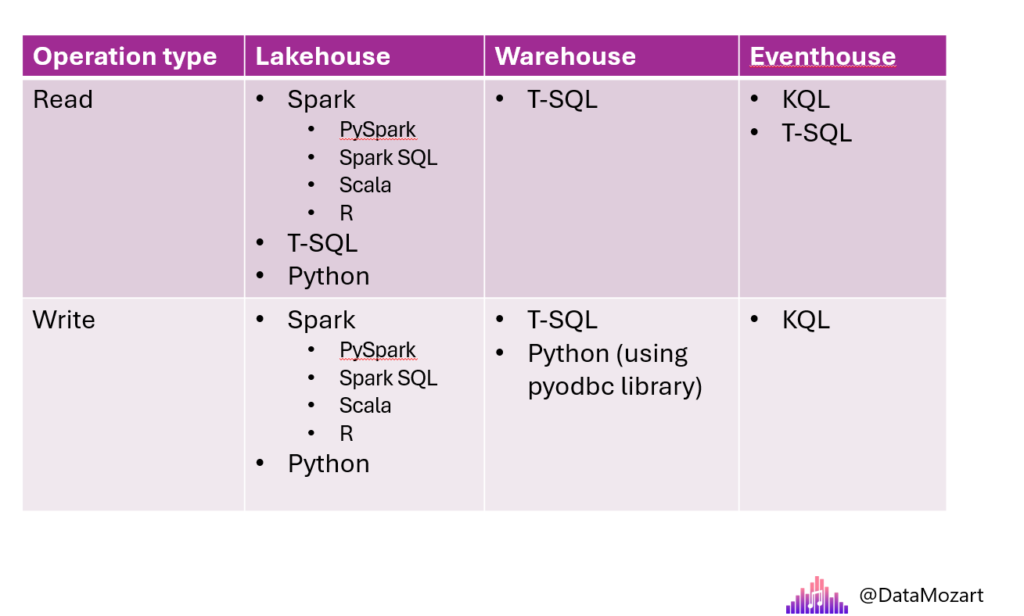
Let’s stop for a moment and examine the importance of the selection you make based on this information. Imagine that you’re implementing a medallion design pattern in Microsoft Fabric. In accordance with the recommended practice of building a Star schema dimensional model in the final layer (gold/curated), you’d need to apply various data transformations to implement business rules and logic. Hence, if your data engineers or analytics engineers are feeling comfortable writing T-SQL, you should probably choose a warehouse for this layer, since T-SQL can’t be used for inserting, updating, or deleting the data in the lakehouse and/or eventhouse.
On the flip side, if the majority of the data team is proficient with Python or any language that can be used to manipulate the data using the Spark engine, you’d probably go all the way with the lakehouse. Although, in full honesty, the road between the T-SQL and Spark SQL is not that long, in case you plan to leverage SQL skills while using the lakehouse.
OneLake Interoperability
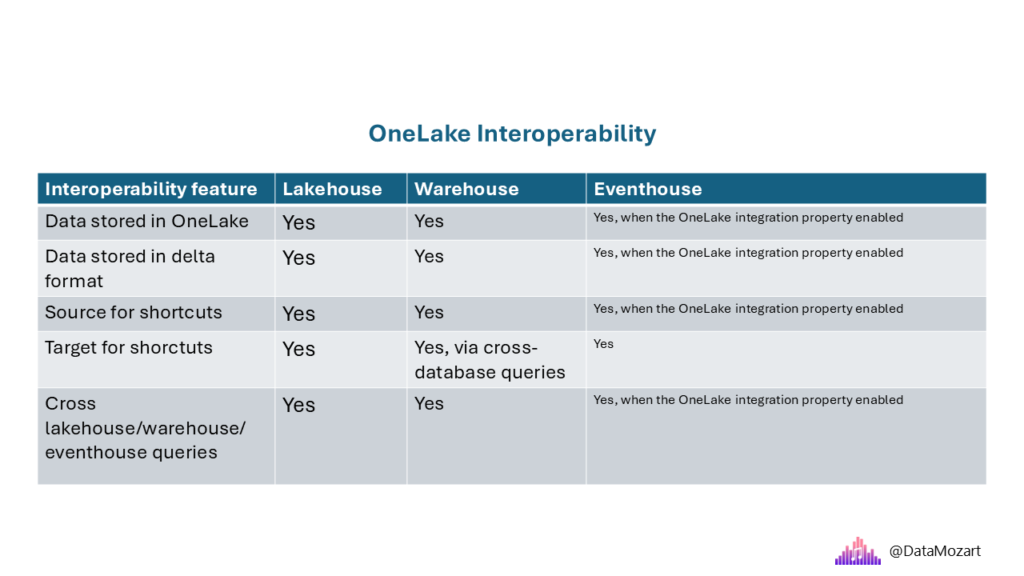
Now, things become more complex…“What if I choose the lakehouse for my silver layer, and the warehouse for the gold layer? Can I combine the data from both the lakehouse and the warehouse?” This is a very common question asked by data professionals considering or already using Microsoft Fabric. Hence, in this table, you’ll find an overview of the interoperability between various analytical engines in Fabric.
Scenario-based Decision Guide
Based on all of the aforementioned criteria and typical analytical requirements, I identified a few common scenarios you might face when deciding which Fabric component to pick for the particular use case. The table below illustrates the level of suitability of each analytical engine for the scenario in the scope. A 5-star rating means that the particular engine is a good fit for the specific use case. A 3-star rating means that the required scenario may be accomplished by using the particular analytical engine, but with some limitations or considerations. Finally, a 1-star rating means that I don’t recommend using the particular engine for that specific use case.
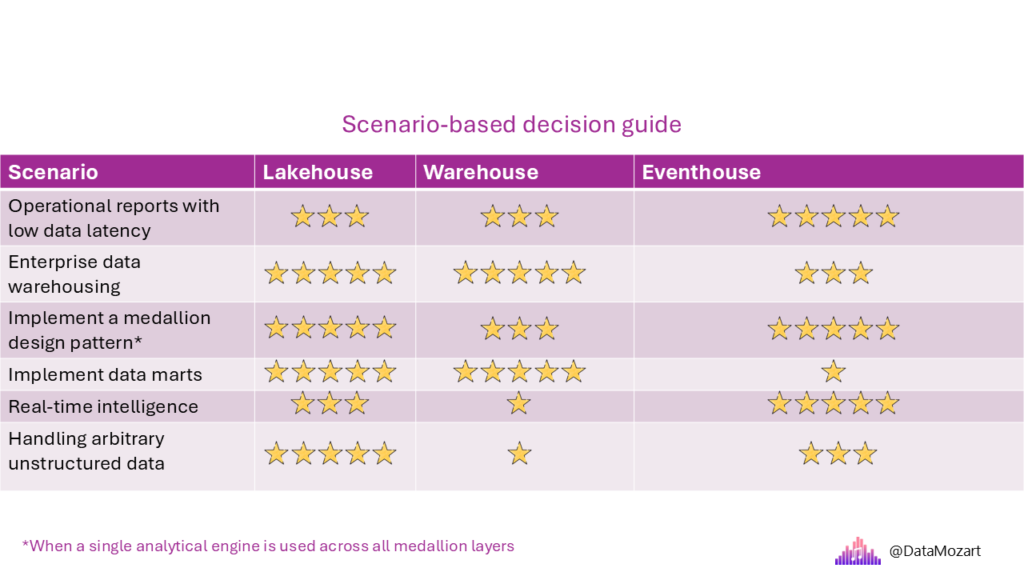
For the sake of clarity, I would like to provide a brief overview of each of the scenarios
- Operational reports with low data latency – Emphasis is on providing low latency and high concurrency for small to medium volumes of structured data
- Enterprise data warehousing – Emphasis is on providing scalability for storing and analyzing medium to high volumes of structured, semi-structured, or unstructured data
- Implement a medallion design pattern – Refers to a design pattern where data goes through multiple layers (for example, bronze, silver, and gold, or if you prefer, raw, validated, curated) on its way from ingestion to consumption-ready. In real life, there are dozens of scenarios where a medallion pattern is implemented by combining multiple analytical engines. One of the most common implementation methods is leveraging the lakehouse for the bronze and silver layers and the warehouse for the gold layer. Of course, this is not set in stone, and depending on the specific use case, you may use a lakehouse-only or warehouse-only approach when implementing a medallion pattern. On the flip side, the eventhouse would be a good fit when implementing a medallion pattern for the streaming data
- Implement data marts – Emphasis is on providing efficient analytical capabilities for structured data, as a subset of an enterprise data warehouse focused on a particular line of business, department, or subject area
- Real-time analytics – Emphasis is on providing efficient processing and analytical capabilities for the data as soon as it becomes available. In streaming data scenarios, an eventhouse is the most obvious choice, although you might also pick a lakehouse in some cases where query concurrency is not a concern
- Handling arbitrary unstructured data – A lakehouse is a no-brainer here, because of its support for all data formats
Let’s wrap up this part with the high-level decision tree for the analytical storage engine.
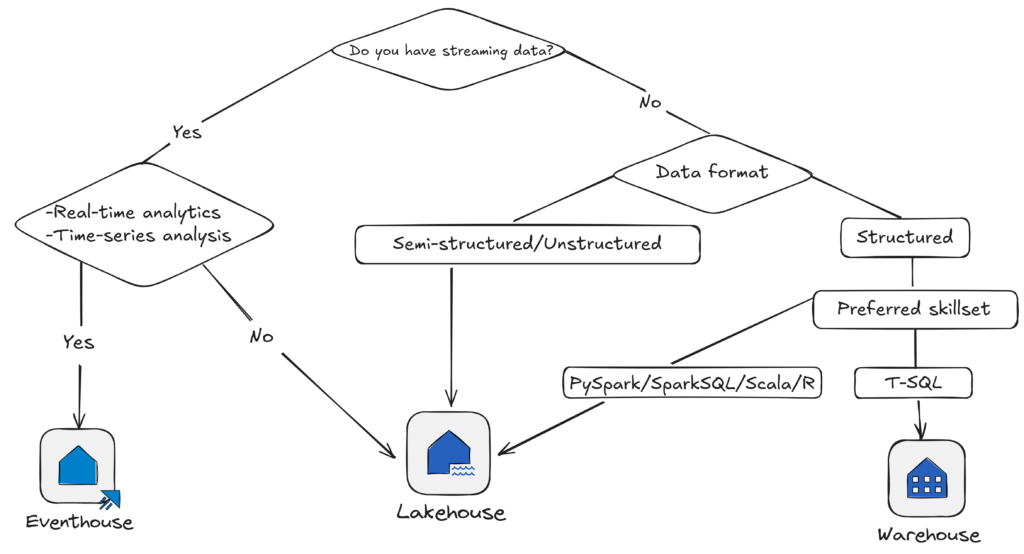
Please keep in mind that it shows a simplified overview based on the common scenarios we previously examined, and it’s by no means definitive guidance when choosing the optimal analytical engine. In addition, I would also like to emphasize that combining multiple engines should be an option when you need to incorporate diverse analytical workloads across the data platform.
Mirrored Azure SQL Database or SQL database in Fabric?
I already wrote about both Mirroring and SQL database in Fabric. And, if you wondered after reading these two articles, what is the difference between the mirrored Azure SQL Database and SQL database in Fabric? I don’t blame you, as these two are “children” of the same “mother” – Azure SQL Database.
Hence, from a purely conceptual and technical point of view, there is very little difference between the mirrored Azure SQL Database and the SQL database in Fabric. In both scenarios, your operational data is replicated in near-real-time and stored in delta format in OneLake, using the same technology under the hood.
The key difference and the key factor that you should consider when choosing between these two is: who is taking care of the operational database itself?
If you choose mirroring for Azure SQL Database, since we are talking about the PaaS (Platform as a Service) offering, you are still in charge of the database – security, number of vCores or DTUs (database transaction units as a blended measure of CPU, memory, reads, and writes), managing costs, scalability, and so on. On the flip side, as a SaaS (Software as a Service) offering, the SQL database in Fabric is managed as part of the entire Fabric ecosystem. This means, it automatically scales and integrates with the development and analytics framework in Fabric, whereas costs are included in the single Fabric bill.
Sitting in a car or driving it?
Mirrored Azure SQL Database or SQL database in Fabric. Which one is better? I’m afraid there is no correct answer to this question, as it would be the same as trying to answer the question: is it better to sit in the back of the self-driving car vs. driving the car yourself?
The following figure depicts the key difference between the mirrored Azure SQL Database and the SQL database in Fabric:

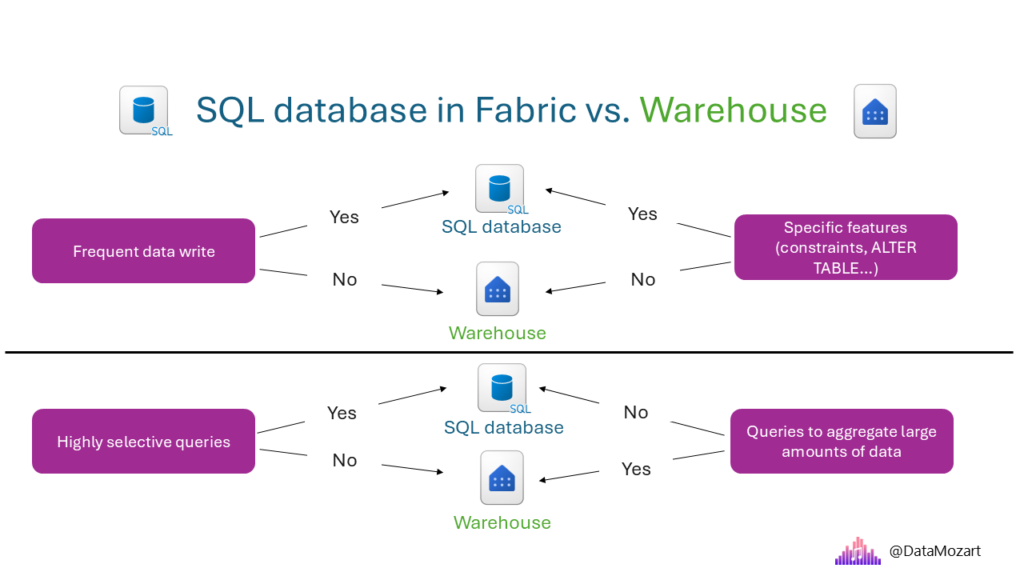
SQL database in Fabric or Fabric Warehouse?
Another common question about storing options in Fabric comes from people proficient in using the T-SQL language. There are two Fabric items that support the so-called CRUD (Create, Read, Update, and Delete) set of operations using T-SQL: Fabric warehouse and SQL database in Fabric. Therefore, the fair question would be: when and why to choose one over the other?
I’ve prepared another high-level decision tree to help you pick the right tool for the job. Although, if I need to summarize the key difference, or use case, for each of these two, I’d say: SQL database in Fabric is suitable for OLTP workloads, whereas a Fabric warehouse is a good fit for OLAP scenarios.
Conclusion
Although this article is by no means a definitive guide to building your “dream” Fabric architecture, I sincerely hope it provides a solid starting point when choosing the optimal analytical engine for data processing. Again, it’s worth reminding that this guidance relies on general recommended practices, which means that the practice recommended in this article may be used in most of the respective scenarios, but there will always be specific cases when the recommended practice is simply not the most optimal solution.
Thanks to Slava Trofimov for his blog post, which inspired a significant portion of this article, and Miles Cole for creating amazing Fabric icons library for Excalidraw, which I’m extensively using to illustrate various Fabric concepts and features.
Thanks for reading!
Last Updated on May 13, 2025 by Nikola



Koen Verbeeck
I did some test with Fabric SQL DB and it’s capacity consumption is so high (running a couple of lightweight queries on a small table already consumes 50% of a F4), I really wouldn’t run a real demanding OLTP load on it, but rather use Azure SQL DB.
Predrag Manigoda
Great article!
Thank you Nikola