

Doing (proper) indexing on your tables is one of the most challenging and trickiest tasks you will face when working with databases. In my opinion, indexing is science “per-se” within database theory and praxis and choosing right index strategy can reward you with many benefits, but on the other side, doing indexing wrong can significantly affect your workload and decrease overall performance of your database.
I will not going into details over indexes themselves, there are really tons of articles and resources out there. Just keep in mind that there is no perfect and “one-suits-all” solution – it’s always a trade off between improving query performance and index maintenance overhead. For sure, you should test, test, test and measure performance to see the real impact of your index.
Show me the real thing…
Ok, so in my scenario, one fact table that stores data about customers’ surveys, is being queried by multiple reports. Table has approx. 8,5 million rows and following indexes:
- clustered index on primary key (surveyID)
- non-clustered index on columns sourceID and surveySourceID (these values come from source system)
- non-clustered index on column chatID (survey is related to specific chatID)
And here is the query which is heavily used in the reports:
select s.sourceID
,s.surveySourceID
,s.chatID
,s.startdate
,s.submitdateUTC
,s.question
,s.answer
,case when s.surveySourceID = 731481 then 1 else 0 end productID
from factSurvey s
where s.startdate between @dFrom and @dTo
So, nothing special here in terms of complexity: retrieving data from fact table. For testing purposes, I will set parameters to retrieve data about all surveys from March 2020. Let’s go and check what SQL Server will come with.
First, let’s turn on statistics to see what is going on in the background:
set statistics io on;
set statistics time on;
There is a nice handy tool for parsing statistics, called Statistics Parser, which gives you more readable overview of query statistics.
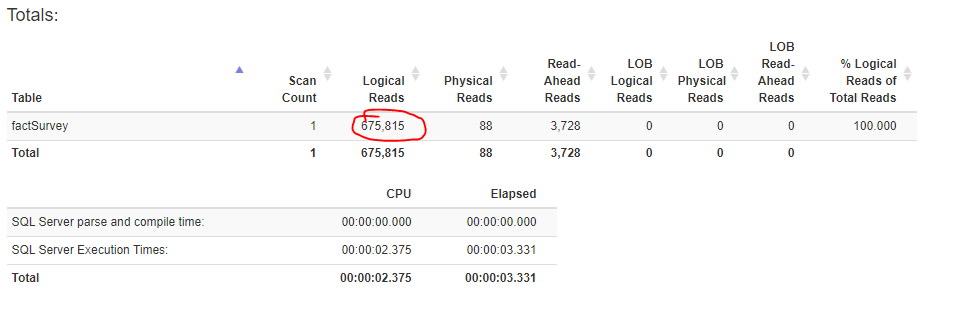
And here is the actual execution plan:
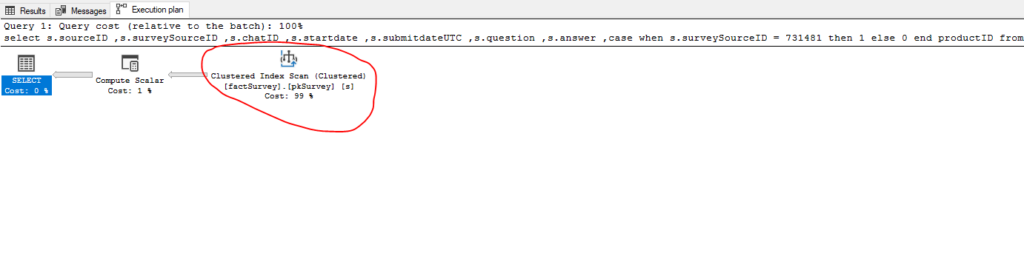
In this case, SQL Server decided to perform clustered index scan to return 89.306 rows, because it assumed that this is gonna be faster/cheaper than doing non-clustered index seek and then lookup for other output columns in clustered index. You rightly noticed that there is no suggestion from SQL Server to create an index.
But, what can we do to make life easier to our SQL Server? Let’s try to create non-clustered index on predicate (startdate column) and id columns (sourceID and surveySourceID). We will also include other columns required by our query (keep in mind that include columns store data on leaf level).
CREATE NONCLUSTERED INDEX [ix_startdate_idcolumns] ON [factSurvey]
(
[startdate] ASC,
[sourceID] ASC,
[surveySourceID] ASC
)
INCLUDE ( [ChatID],
[submitDateUTC],
[question],
[answer])
GO
Now, let’s run our query again and check if SQL Server thinks that it’s better fit.
Let’s first check execution plan:

SQL Server uses our newly created index. Oh, man, this is awesome! Instead of almost 700.000 logical reads, SQL Server now reads only around 1.000 pages!!! And that’s only for 10 days of March 2020, imagine the impact on larger time frame.
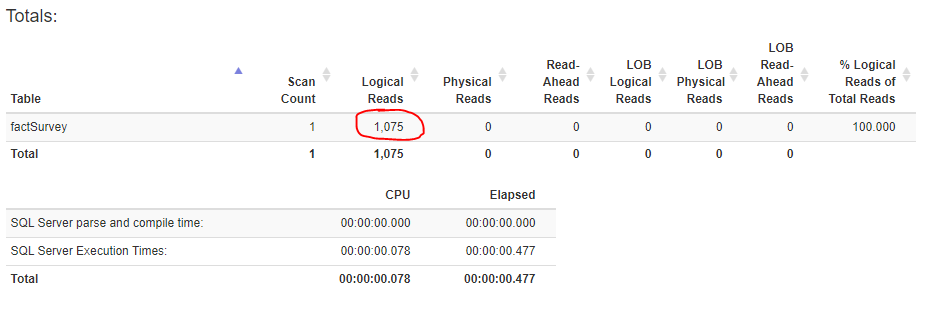
Conclusion
As I already mentioned, indexing is always a trade-off between the benefit you will get for querying and overhead you will have for maintaining that index. Since my fact table is not being constantly hit by inserts/updates/deletes, this index completely makes sense.
If you want to find out more about indexes, refer to this page. I also highly recommend reading Brent Ozar’s posts on this topic, he makes this stuff looks like a piece of cake with his great presentation skills.
Last Updated on March 11, 2020 by Nikola


