

Options, options, options…Having the possibility to perform a certain task in multiple different ways is usually a great “problem” to have, although very often not each option is equally effective. And, Microsoft Fabric is all about “options”…You want to ingest the data? No problem, you can use notebooks, pipelines, Dataflows, or T-SQL. Data transformation needed? No worries at all – again, you may leverage notebooks, T-SQL, Dataflows…Data processing, you asked? Lakehouse (Spark), Warehouse (SQL), Real-Time Intelligence (KQL), Power BI…The choice is yours again.
In a nutshell, almost every single task in Microsoft Fabric can be completed in multiple ways, and there is no “right” or “wrong” tool, as long as it gets the job done (of course, as efficiently as possible).
Therefore, this article is not about bringing the on-prem SQL Server data to Fabric in the “right” way, but more an overview of the current options we have at our disposal. The main motivation for examining these options and writing about them is the question I’ve been frequently asked in recent months: “We have our data (or chunks of data) stored in an on-prem SQL Server. How can we leverage this data within the Microsoft Fabric landscape?”
So, let’s check what can we do as of today (June 2024)…
Prerequisites
On-Premises Data Gateway
First things first…To be able to bring on-prem data into cloud, you need a special piece of software called on-premises data gateway, which you can download for free from here. Explaining on-premises data gateway is out of the scope of this article, but in a nutshell, you can think of it as a bridge between your non-cloud data (i.e. SQL Server, Oracle, etc.) and various cloud services, such as Power BI, Logic Apps, etc.
Gateway is responsible for ensuring a secure connection to on-prem data sources and reliable data transfer from on-prem sources to cloud.
Simply said, you MUST have a gateway installed, to be able to bring your SQL Server data to Microsoft Fabric.
Connection to SQL Server data source
Once you have the on-prem gateway up and running, you need to create and configure a connection to the specific instance of the SQL Server. In this step, you must provide details such as server name, database name, and login credentials.
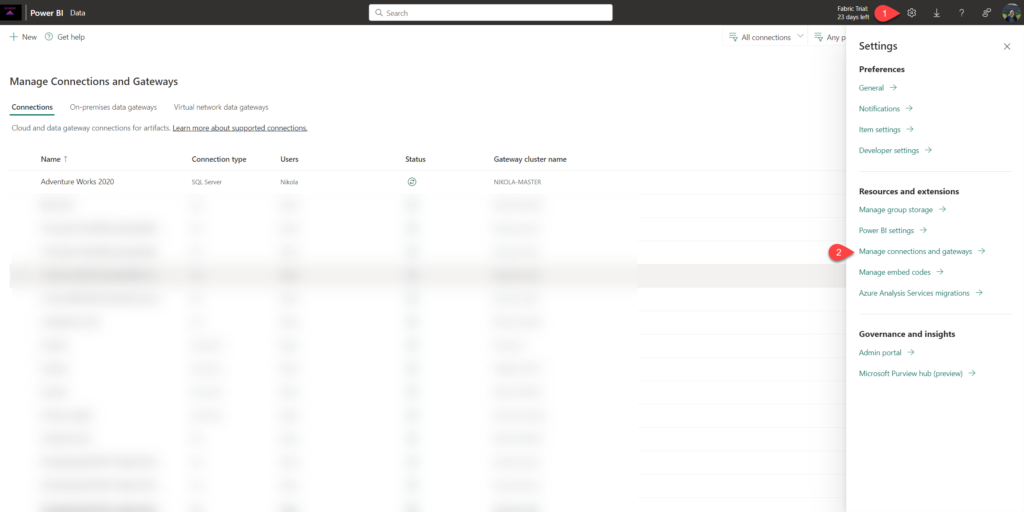
In the illustration above, you can see how to access Manage Connections and gateways from the Admin portal in Microsoft Fabric. You may also notice that I already configured a connection to the Adventure Works 2020 database on my SQL Server local instance.
Since we installed a gateway and configured the connection, we can now move forward and learn how to bring the data from SQL Server to Microsoft Fabric.
Option 1: Dataflows Gen2
This is a low-code/no-code approach for bringing (any) data into Fabric. For anyone who ever worked with Power Query in Power BI (both in Power BI Desktop and/or Power Query Online), the entire scenery will look very familiar. From a user interface perspective, nothing changed in Dataflows Gen2, except one key thing – you can now choose the output for your data!
If you go to the Data Factory experience, there is an option to create a new Dataflow Gen2:
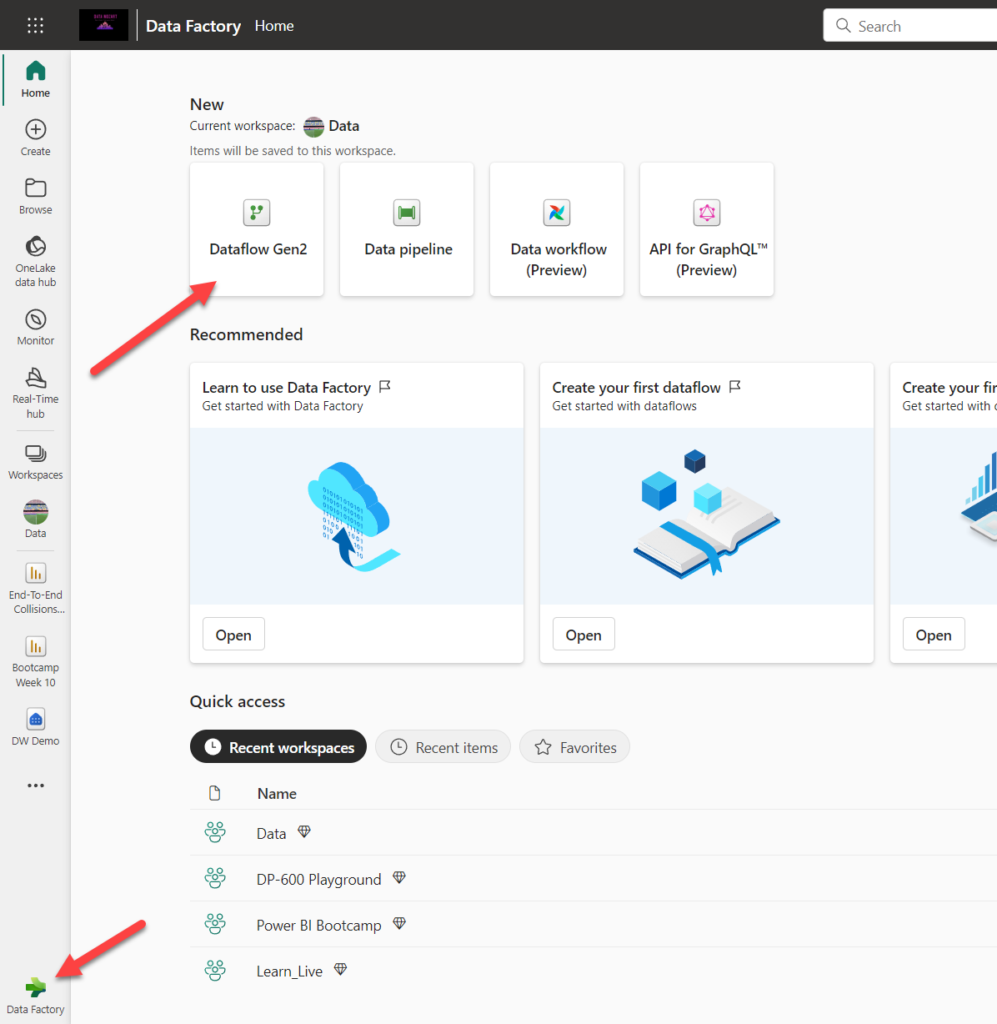
I’ll select SQL Server as a data source and then configure my connection to the local instance of SQL Server and AdventureWorksDW2020 database. Since I’ve already created the connection, it will automatically appear in the dialog window:
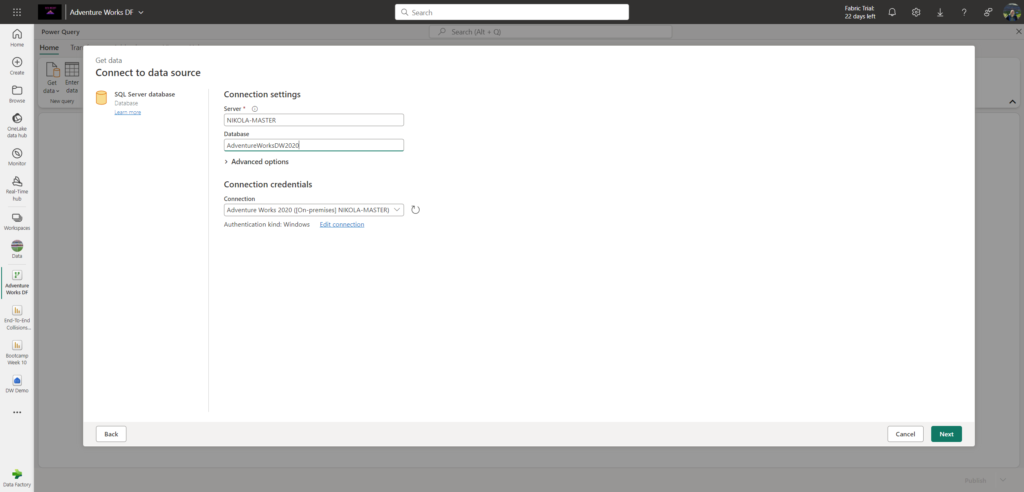
From there, the process is fairly straightforward – you choose tables and/or views you want to bring into Fabric, and you can optionally apply data transformations using a rich set of options of the Power Query Editor:

Finally, the key step in the entire process is to set the data destination. Currently, you can choose between a lakehouse, warehouse, KQL database (Kusto) and Azure SQL database:

Once you are happy with all the settings, you publish the dataflow, and, depending on the amount of the data that needs to be transferred from the on-prem SQL Server to Fabric, it may take some time to see the data available in the form of delta tables within a Fabric destination you specified. By default, all of the tables will be v-ordered and ready for further downstream consumption by all Fabric engines, including Direct Lake mode for Power BI.
Option #2: Pipelines
With Dataflows Gen2, it was super easy! Let’s now examine another option – Data pipeline.
In a nutshell, a pipeline plays two different roles in the Microsoft Fabric ecosystem:
- Data ingestion option – using the COPY command via the graphical user interface, you can quickly and easily ingest data from various external sources into Fabric. Think of it as a copy/paste of your data from “somewhere” to Fabric
- Data orchestration tool – in this “role”, a pipeline extends beyond pure COPY activity and enables you to add additional activities, orchestrate the order of execution and define the logical flow of the data ingestion process. For example, once you ingest the data into Fabric with a pipeline COPY activity, you can add a Notebook, T-SQL stored procedure, or Dataflows Gen2 tasks to further shape your data
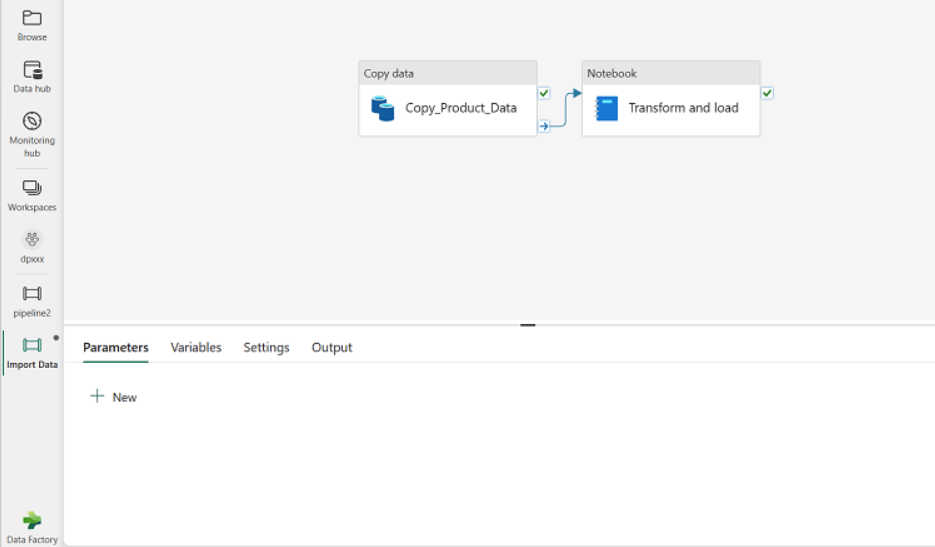
And, I’ll immediately tell you two things to keep in mind if you choose to use Pipelines for bringing your SQL Server data into Fabric:
- This feature (bringing on-prem data into Fabric) is still in preview as of June 2024. This means, some of the functionalities may not work, or may work in a different way than you expect, or may simply still be missing from the feature
- Pipeline behavior for this specific task may vary significantly between the lakehouse and warehouse in Fabric as a destination, so it’s important to choose which one you are using, as this can have a huge impact on the process
Option #2a: Lakehouse as a data destination
Similar to Dataflows Gen2, this one is fairly straightforward. After I’ve chosen to create a new Pipeline in the Data Factory experience, and then Copy data assistant, I’ll be prompted to enter a data source connection details:
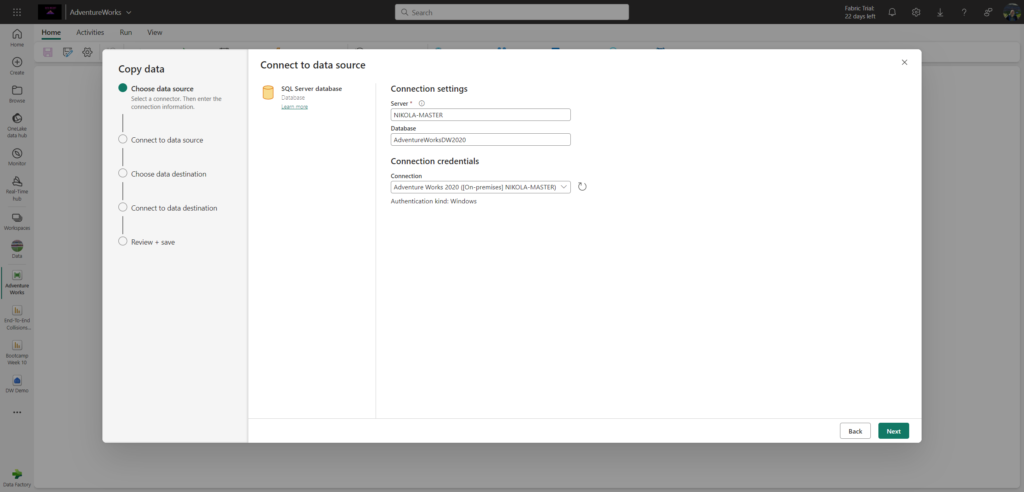
I’ll then select tables and/or views I want to bring from my Adventure Works database and I’m done. I can also write a T-SQL query to create brand-new delta table in the Fabric lakehouse:
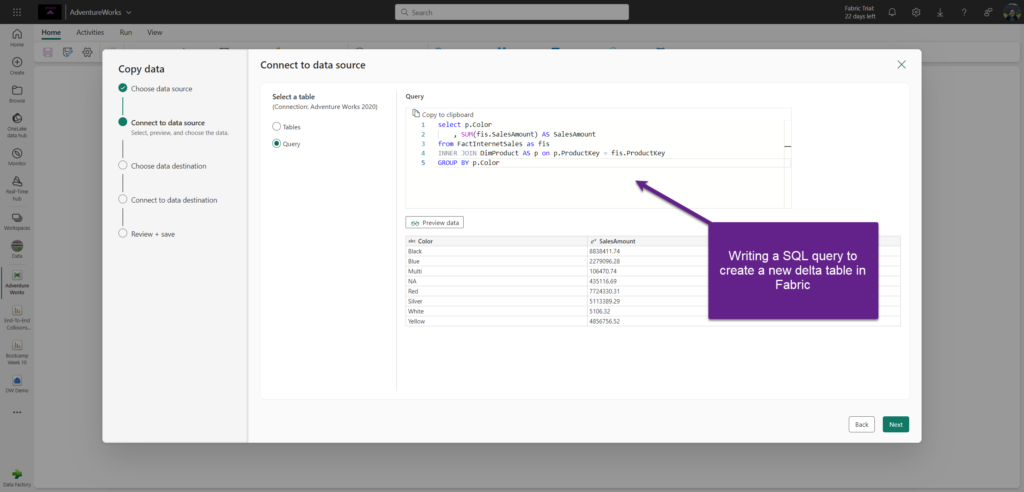
Next, I’ll choose a Lakehouse as the data destination. I can select both the existing lakehouse (which I’ll do for the sake of this example), or create a new lakehouse for this data specifically (which might be useful because of the certain limitations I’ll soon introduce).
I’ll then configure destination details and column data types, and I’m good to go:

After a few seconds, I’m able to see new delta tables in my Fabric lakehouse:

From here, I can leverage the data from these tables for all Fabric workloads, including Direct Lake for Power BI.
This was super easy and straightforward, life is good:)
Option #2b: Warehouse as a data destination
Let’s say that your tool of choice when working with Microsoft Fabric is a Warehouse. You would expect that the same process explained above is relevant in this scenario as well, right? Because, the official documentation doesn’t say a word that it’s different, right? Well, I have to disappoint you…
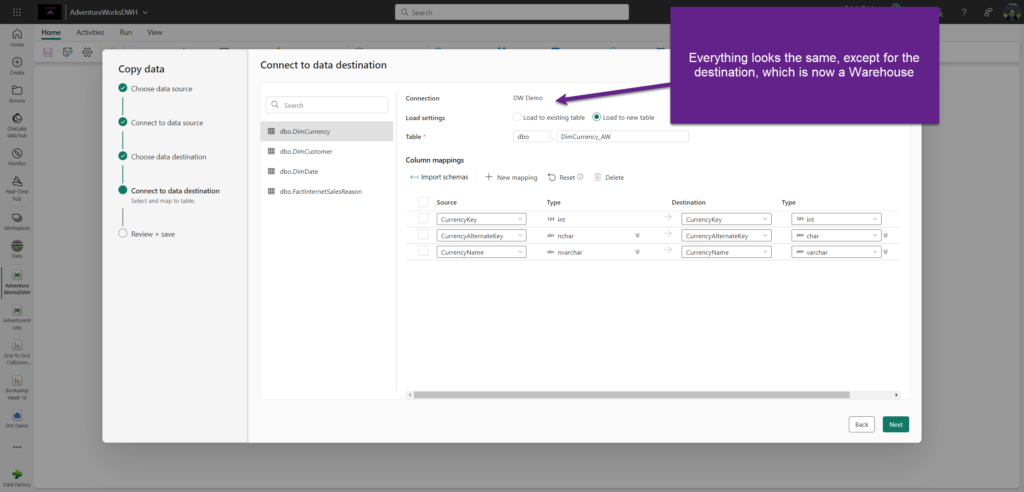
Let’s create a new pipeline and repeat all the steps from the “lakehouse scenario”, except for the data destination, where I’ll choose to move my SQL Server data into the Fabric warehouse:
As soon as I click “Next”, I see an error message at the bottom, written in red:
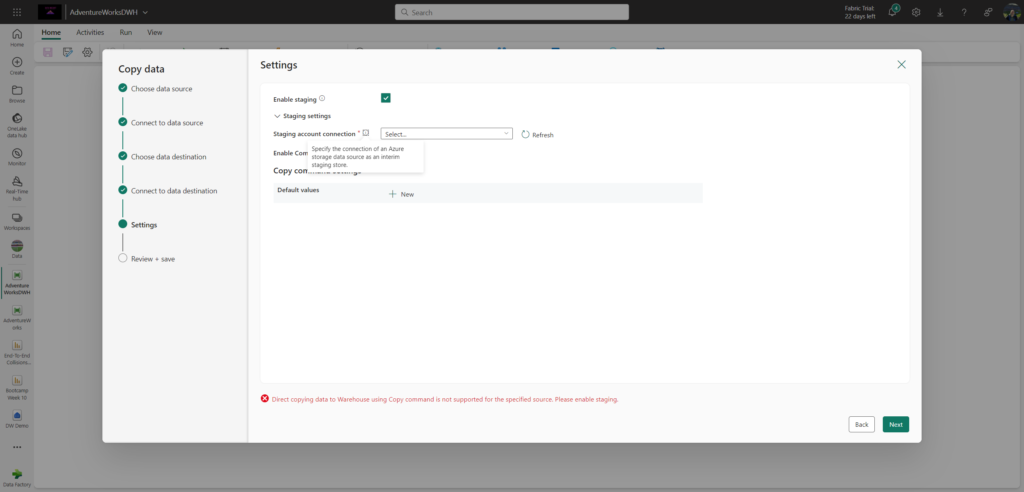
It requires me to enable the staging (which is enabled, by the way). So, essentially, what it asks me to do is to define an intermediate staging area (an Azure Storage account), and then connect to this external account (external to Fabric) to bring the data into Warehouse! What the f…rench toast?!
A few things to mention here: first of all, I consider this a VERY BAD user experience, and I already provided this feedback internally to Microsoft. The answer I received was that the warehouse connector relies on the COPY INTO command to write into the Fabric warehouse. If the source is something that is not supported by COPY INTO (such as on-prem SQL Server, for example), it is necessary to stage the data first and then run the COPY INTO from that staging area (external storage account). So, it is a connector limitation…
But, I still consider it a bad user experience, and let me explain why: Fabric is “sold” as a SaaS solution (“Everything just works!”). And, the latter is very true for the Lakehouse “use the pipeline to bring SQL Server data to Fabric” scenario, but it’s not true for the Warehouse scenario. Why would I (when I say I, I refer to the Fabric user, my clients, etc.) need to set and configure any additional storage myself?! This is SaaS, right? So, I would expect that this intermediate storage (staging) is provisioned for me behind the scenes if it’s required “by design” of the Warehouse workloads (connector limitations, etc.).
What should I tell clients who want to bring SQL Server data with pipeline into Fabric? “Folks, you should not use Warehouse, because then you need to configure XYZ in addition…But, hey, if you use Lakehouse, it just works…” That’s an inconsistency IMO between these two, and this should be explicitly mentioned in the official docs, so that everyone knows what are prerequisites if they plan to go the “Warehouse route”.
As already mentioned, I provided this feedback internally to Microsoft, and let’s hope that this is just a temporary limitation, which will be resolved once this feature goes GA…
As a current workaround, you can either use a Dataflow Gen2 to bring your on-prem SQL Server data directly into the Warehouse, or use Pipeline to bring the data into Lakehouse, and then write cross-database queries to combine the SQL Server data from Lakehouse with the other data in Warehouse.
What about Shortcuts, Mirroring, Notebooks…
Fine, now that we learned all the caveats of bringing on-prem SQL Server data to Fabric by using Dataflows Gen2 and/or Pipelines, let’s examine how other data ingestion options measure against this task.
- Shortcuts – I’ve already written about Shortcuts here. I honestly consider Shortcuts one of the greatest features in the entire Fabric ecosystem. However, there is (still) no option to create shortcuts to SQL Server data
- Mirroring – Another feature that I consider a “big thing”. In a nutshell, Mirroring “translates” a proprietary format of the source database to delta format on the fly, and creates a near-real-time replica of this data in OneLake, so that it can be leveraged for all “regular” Fabric downstream workloads (including cross-database queries and Direct Lake for Power BI). Unfortunately, as of today, SQL Server is not supported as a data source for Mirroring. In the official blog post that announced Mirroring, it was mentioned that SQL Server should be supported in CY24, but looking at the official release plan for Fabric Warehouse, there is no single word about SQL Server support coming this year…Therefore, let’s hope for “SQL Server Mirroring Santa” coming out of the blue and make us all happy:)
- Notebooks – Notebooks are a super-powerful data ingestion (and data transformation) option! Unfortunately, notebooks are not supported for on-prem data sources in Fabric (as far as I understand, this is because of the gateway limitations for notebooks support, but I might be wrong). In any case, I’m not aware of the possibility of using notebooks for bringing on-prem SQL Server data to Fabric. If anyone knows how to do it, I’d be happy to update this article:)
Conclusion
Bringing data from the on-premises SQL Server databases to Microsoft Fabric is one of the key requirements for many companies considering moving to Fabric.
Since Fabric is all about the options – don’t forget, one single task can be performed in multiple different ways – I hope this article shed more light on various tools and features that can be leveraged to make your SQL Server data available in Fabric. As you’ve seen, the choice can be very nuanced, and depending on your specific use case, you might want to consider certain limitations/workarounds before you decide which path to take.
Thanks for reading!
Last Updated on June 17, 2024 by Nikola



Klara
Hello Nicola,
this article was very simple but informative and finally I understand my company’s new DLH and DWH. As I checked how it is made I have a few questions, maybe you will help me:
1) I can see that creating our DLH and DWH IT team were using data pipelines (one for copying data, another for updating and other for ingesting data) as well as 2 dataflows. What is the following steps for these two? From your article I understood, that you can transform data in dataflows (same as in Power Query) or you can copy and transform data in data pipelines. Why they used both of them to create DLH and DWH? From the first view it looks like the task was done twice, but maybe is there logical explanation for using both? Could it be because our data is quite big or smth? What are the steps for doing it or how they combine those two (data pipelines and dataflows for the same DLH and DWH) did that?
Nikola
Hi Klara,
It’s verey hard to answer without knowing more details. Generally speaking, pipelines are predominantly used for two purposes:
1. Data orchestration – you can define a flow of different tasks within the pipeline. For example, you first copy the data, then you run a Dataflow, after that you run a notebook, and then finally you refresh Power BI semantic model. So, the pipeline orchestrates the execution and you are controling this flow of execution.
2. Copy data – this is a very fast way to load data as-is, without any further transformations
Dataflows Gen2 may also be used to load the data in the LH, but their main purpose is low-code data transformation. Based on what you wrote, I ASSUME that the pipeline first copy data as-is from the data source, and then a Dataflow Gen2 is used as an activity in the pipeline to transform the data.
Hope this helps.
michelle
Hello Nicola
Thanks for this document . i also struggle the “Warehouse as a data destination” , the stage setting even i find the storage account key also test connection is work when go to next still fail.
jean
Hi Nicola, thank you so much for this article. I have been trying to import data from sql server to Fabric for weeks without success. I have tried dataflow gen2 and add lakehouse or warehouse as my destination, but both generate errors in the publishing phase. I didn’t know copy data would solve the issue, so thanks a lot for the article. And I agree that dataflow gen2 is not user friendly, the error message is not helpful, our IT teams has tried several time to open the endpoints for dataflow gen2, but they didn’t succeed so far. I wish someone could share knowledge about how to set up firewall for data flow gen2.