
A few days ago, while preparing materials for the customer training on Microsoft Fabric, I stumbled upon a very interesting article at Microsoft Learn. The article describes how to integrate Power BI semantic models (aka datasets) into OneLake.
At first glance, this doesn’t sound like something epic, but when I started thinking more and more about it, I realized that this really might be a huge thing in many different scenarios. First of all, at the moment of writing, this feature is still in preview – this means, it can change to some extent in the coming months, before eventually becoming GA. Nevertheless, I decided to take a shot and explore what can be done with OneLake integration for semantic models.
Setting the stage
If you’re still not sure what Microsoft Fabric is, I strongly encourage you to start with this article, where I cover all the necessary details. Let’s get straight to the point here and explain what OneLake integration for semantic models provides:
This feature enables creating Delta tables in OneLake for all your Power BI semantic models which contain at least one table in import mode!
Ok, nice, but what’s the deal with that? Stay tuned and I try to explain why this may be beneficial in certain scenarios.

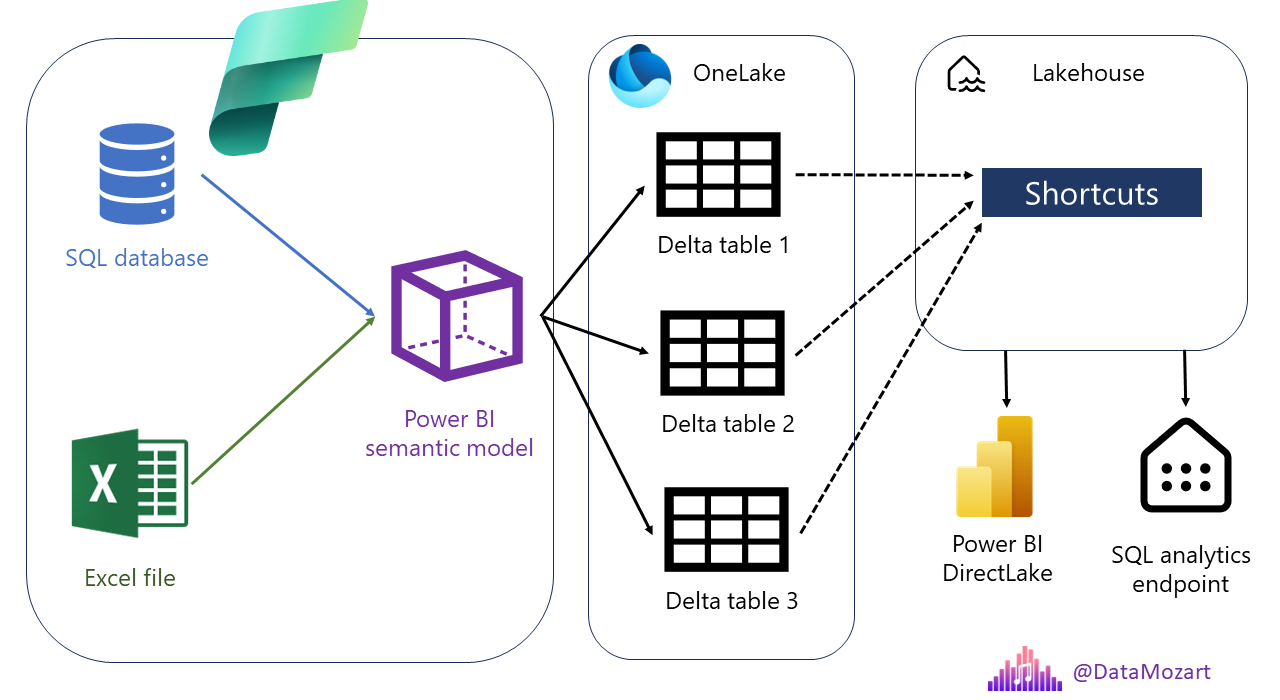
Let me quickly walk you through the diagram above and I’m sure you’ll understand the potential behind the entire concept. So, in a traditional Power BI deployment workflow, you would go and import the data from various sources – think of SQL databases, Excel files, SharePoint lists, etc. Once you import the data into Power BI… Congratulations – you’ve just built a semantic model! That semantic model may be (and in reality it often is) enriched with various additional logic and/or calculations – think of DAX calculated tables, columns, and measures. The entire semantic model is stored in the instance of the Analysis Services Tabular (the purple cube icon in the illustration).
And, here the magic starts! You can then export tables from the Power BI semantic model as Delta tables in OneLake!!! Wait, what?! Yes, I’ll quickly show you how to do it and which possibilities this feature offers. Once in OneLake, you can do to these tables everything you can do to “regular” Delta tables – including creating shortcuts. From there, again, you can do whatever you can do with the “regular” shortcuts – create Power BI reports in DirectLake mode, and/or leverage the SQL analytics endpoint of the Lakehouse to directly query the data (although the latter is not supported during the preview).
Why is this huge?
Well, currently, there are only a few data sources that support the native shortcuts concept: other Fabric lakehouses, KQL (Real-time-analytics) databases in Fabric, as well as the following non-Fabric sources: ADLS Gen2, Amazon S3, and Dataverse. With the OneLake integration for semantic models, you can basically create a shortcut to SQL Server table, or even wilder, DAX calculated table!!! This already sounds unbelievable, so let’s jump into the action…
First of all, you need either a Power BI Premium-per-capacity license (P1 or greater), or F SKU. Next, this feature must be explicitly enabled from within the Power BI semantic model settings.

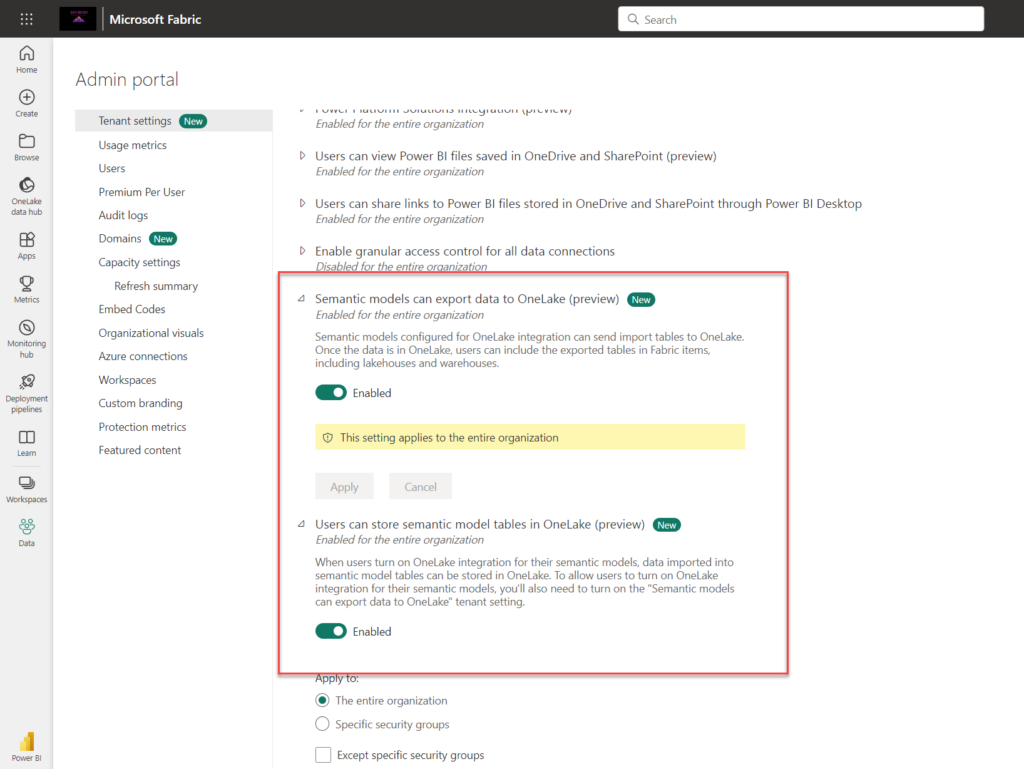
Then, Integration settings must be configured in the Admin portal of the Fabric tenant:
Ok, now we are ready to rock! Here is the sample report I’ve just created in Power BI Desktop. I have various data sources, such as a few tables from the Contoso database in SQL Server, a few Excel files, and also some DAX calculated tables:

Once I publish the report to the Fabric-enabled workspace, I’m ready to export my semantic model tables to Delta tables which will be stored in OneLake.
This time, I’ll use SSMS to execute the following XMLA query:
{
"export": {
"layout": "delta",
"type": "full",
"objects": [
{
"database": "Chef Big Book"
}
]
}
}
After the query successfully completed, I can open OneLake file explorer and find my newly created Delta tables:
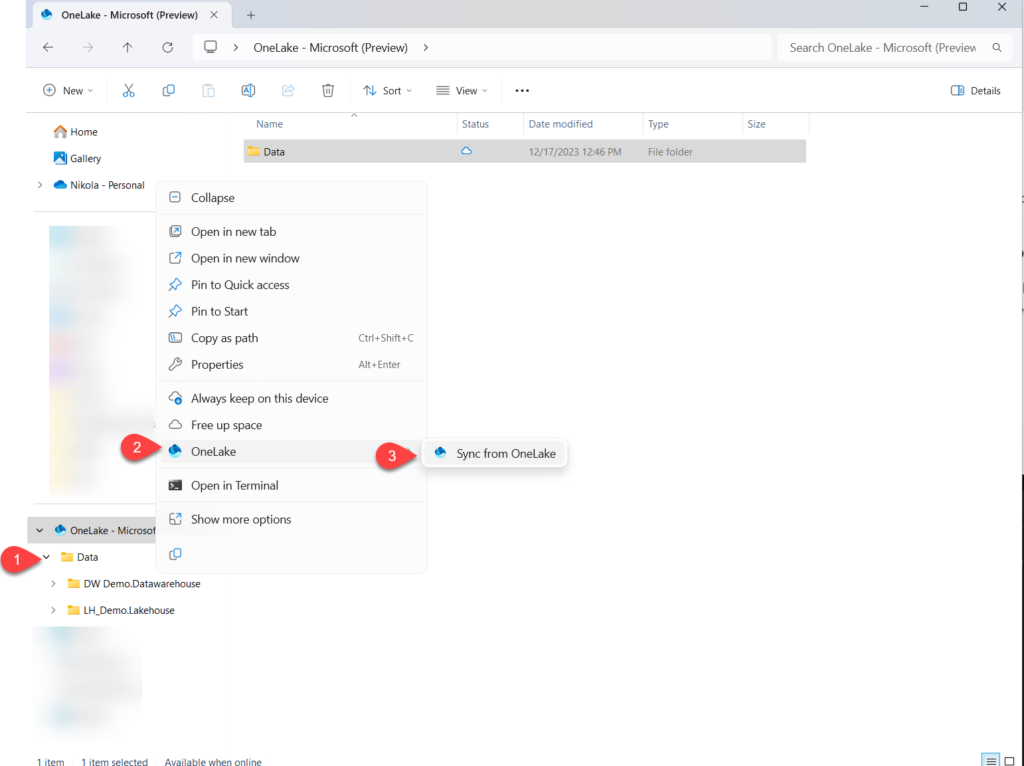
If you right-click on Data, and then choose Sync from OneLake under the OneLake dropdown list, you should be able to see the brand new folder available:

As you may notice, there is a new artifact in OneLake, which has a .SemanticModel suffix. Let’s go and explore what’s in there…

That’s incredible! So, we basically transformed the Excel file, SQL Server table, and DAX calculated table into Delta format! To be 100% honest, not directly, but through the intermedium called Analysis Services Tabular…Now, as I mentioned at the beginning, you can use these tables the same way as any other Delta tables in OneLake.
Let’s create shortcuts to these tables from our Fabric Lakehouse:

I’ve intentionally chosen tables coming from all the different sources (Sales per Brand is DAX calculated table, ContosoProduct is SQL Server table, Premium Type was created by using the “Enter data” option in Power BI Desktop, whereas Premium comes from the Excel file).

…which brings us to a key question…
Why is this a BIG deal?!
Let’s examine a few potential use cases for this new feature (and I’m sure others from our community will find many more):
- Refresh once – use it everywhere! I have a huge SQL Server table (or tables) that’s already part of the Power BI semantic model, and this table should be reused by other data professionals in my organization (data analysts want it in other Power BI reports, data scientists need it for their tasks, etc.). Instead of establishing a data ingestion workflow for that table, using Dataflow Gen2, a pipeline, or a notebook, to ingest the same data into the lakehouse, I can simply export it to OneLake and access it via the shortcut from any workload that requires data from that table
- Democratize the data from DAX calculated tables in Power BI semantic models – In the Power BI semantic model, I’ve identified a table that contains the important business logic, but it’s implemented by using DAX. I wish to make this data available to multiple data professionals within the organization – instead of rewriting the logic and creating a new physical copy of the same data, I can create a shortcut and let everyone access the table
- More granular access control – I want to have more granular control over tables from the Power BI semantic model. I can export them to Delta tables in OneLake and then configure different set of rules for Delta tables
These are obviously just a few scenarios that immediately come to mind. Now, the fair question would be:
What happens with the data in OneLake when the data in the original data source changes?
Is it somehow automatically synchronized or not? Let’s try and check.
Since we are using the Import mode for this semantic model, we obviously need to refresh the model in Power BI Service, so that we have the latest data available.
My main concern is: once I refresh the semantic model, will the latest data also be automatically available in the Delta table, or not? In other words, do I need to export the latest version of the semantic model again?

I have good news and great news for you… The good news is: you don’t have to export the semantic model again. The great news is: you should just hit the Refresh button and the latest data is here and ready to be consumed by all the downstream workloads – think of Power BI Direct Lake scenarios, or querying SQL analytics endpoint! This is…simply amazing!!!
Before we wrap it up, please be aware that this feature, no matter how incredible is, is still in the preview. So, make sure to understand all the possible limitations. You can find the whole list of considerations and limitations on the official Microsoft Learn page.
Conclusion
OneLake integration for semantic models is one of the potential game changers, because now your Power BI semantic models can be leveraged as a data source for various additional workloads across the entire organization.
Not only that – by using this feature, you can significantly reduce the amount of workload in your Fabric tenant, since there is no need to create redundant data movement and multiple physical copies of the same data.
And, although we (still) can’t create native OneLake shortcuts to SQL Server tables or DAX calculated tables, OneLake integration for semantic models provides an elegant workaround, and essentially enables you to create a “shadow shortcut” over literally any data source that is part of the Power BI semantic model!
Personally, I’m really curious to see how this feature develops and to learn about more potential use cases in the future.
Thanks for reading!
Last Updated on December 18, 2023 by Nikola



Ricky Schechter
Hi Nikola, thank you for your post. In my short experimentation with shortcuts, I found that the table that I created in the LW (from the shortcut) did not get updated even if I do “refresh” the shortcut and the table.
Perhaps this is not an issue with shortcuts, rather with Lakehouse tables…here the sequence of events…
1. uploaded a small csv file to the Lakehouse “Files”
2. created a shortcut to it
3. clicked “Load as Tables” from the shortcut’s contextual menu -> a new table gets created
a. I believe that to consume the file contents from different Fabric areas, I need to make it a table first, right?
4. modified the original file on my local box (adding 1 row)
5. re-uploaded the file to the Lakehouse Files
6. refresh the shortcut -> I see shortcut shows the updated file
7. refresh the table -> the file content has NOT refreshed
a. I must “Load as Table” (new/existing) again, so the table would reflect the updated content… Why is that? I can do the same using pySpark using saveAsTable
· Additionally, “Viewing Files” for the table, I see each (every loaded) and every parquet file it was behind before even if data is not in use any more, is this due to the feature of TIME_TRAVEL and why the parquet files remained undeleted?
Nikola
Hi Ricky,
Hm, not sure if that is “by design” (that you need to re-load as a table to refresh the content), or is it a bug…Honestly, I’d expect to see it automatically refreshed once you uploaded the newer version of the file. Maybe this is because the Files are is considered as unmanaged and Spark manages only metadata. Have you tested what happens if you add a new column maybe?
Ricky Schechter
Just tried by adding column -> no difference in behavior. Also if I look at the “view files” for the table, there is nothing indicating the latest refresh.
Ricky Schechter
I also just tried loading to table from the original file (not the shortcut) and then, updating the file, then refreshing the table. Still no updates to the table data. That proves that it is not a shortcut issue, rather than the way load to table has been designed, or that there is a bug. Thanks
Troy
Hi Nikola,
Thanks for the post. Just curious, is there a point to doing all of this is the sql endpoint is not query-able from this type of shortcut?
This seems to be a huge limitation during the preview window of this feature.
Use OneLake Integration for Semantic Models in Data Ingestion within Fabric | Blog Renato Lira
[…] can find more details on how to set this up here, here, and here. But mainly, you need to have Fabric enabled on your capacity, set your semantic model to […]