Get the data architecture right, and everything else becomes easier.
I know it sounds simple, but in reality, little nuances in designing your data architecture may have costly implications. Hence, in this article, I wanted to provide a crash course on the architectures that shape your daily decisions – from relational databases to event-driven systems.
Data architecture is the blueprint that determines where your data lives, how it moves between systems, what happens to it during transformations, and who gets access to what. Think of it as the layout of a city: residential areas, commercial districts, industrial zones, and the transportation networks connecting everything together.
Before we start, I want you to remember this: your architecture determines whether your organization is like a well-planned city with efficient highways and clear zoning, or like a metropolis that grew without any planning and now has traffic jams everywhere.
I’ve seen this firsthand. A company that had grown rapidly through acquisitions had inherited data systems from each company they bought, and nobody had ever taken the time to think about how all of it fit together. Customer data lived in five different CRM systems, financial data was split between three different ERPs, and each system had its own definition of basic concepts like customer and revenue. Their “weekly” business review took two weeks to prepare. Six months later, after implementing a well-thought-out data architecture, they could generate the same review in under two hours.
The difference wasn’t the latest technology or huge budgets. It was simply having a thoughtful approach to how data should be organized and managed.
In this blog post, adapted from a chapter of the book Analytics Engineering with Microsoft Fabric and Power BI, which I’m writing together with Shabnam Watson for O’Reilly, I’ll walk you through the core data architecture types, their strengths, weaknesses, and where each one truly shines. Fasten your seatbelts!
1. Relational Database – The Fine Old Wine
Relational databases date all the way back to the 1970s, when Edgar F. Codd proposed the relational model. At its core, a relational database is a highly organized, digital filing cabinet. Each table is a drawer dedicated to one thing, think of customers, orders, products. Each row is a single record, each column a specific attribute.
The relational part is where the power comes from. The database understands how tables are connected. It knows that Customer X in the Customers table is the same Customer X who placed an order in the Orders table. This structure is what allows us to ask complex questions using SQL.
When working with relational databases, you follow a strict rule called schema-on-write. Think of building a house: you must have a detailed blueprint before you can start laying the foundation. You define every room, every window, and every doorway upfront. The data must fit this blueprint perfectly when you save it. This upfront work ensures everything is consistent and the data is trustworthy.
The opposite approach, called schema-on-read, is like dumping all your building materials into a big pile. There’s no blueprint to start. You only decide how to structure it when you need to build something. Flexible? Absolutely. But it puts the burden of making sense of the chaos on whoever analyzes the data later.
2. Relational Data Warehouse – The Analyst’s Playground
Relational databases were (and still are) fantastic at running the daily operations of a business – processing orders, managing inventory, updating customer records. We call these operational (OLTP) systems, and they must be lightning-fast.
But this created a huge challenge – what I like to call the “Don’t touch the live system!” problem. Business leaders needed to analyze data. But running complex analytical queries on the same live database processing thousands of transactions a minute would grind everything to a halt. It’s like trying to do a deep inventory count in a busy supermarket during peak hours.
The solution? Create a separate playground for analysts. The relational data warehouse was born: a dedicated database built specifically for analysis, where you centralize copies of data from various operational systems.
Two Schools of Thought: Inmon vs. Kimball
There are two fundamental approaches to building a data warehouse. The top-down approach, introduced by Bill Inmon – “the father of the data warehouse” – starts with designing the overall, normalized data warehouse first, then creating department-specific data marts from it. It gives you consistent data representation and reduced duplication, but comes with high upfront costs and complexity.
The bottom-up approach, championed by Ralph Kimball, flips this around. You start by building individual data marts for specific departments using denormalized fact and dimension tables. Over time, these connect via conformed dimensions to form a unified view. It’s faster to get started, more flexible, and cheaper, but risks inconsistencies and data silos if not managed carefully.
Neither approach is universally “better.” Top-down works well for large organizations needing enterprise-wide consistency. Bottom-up shines when you need quick wins and iterative delivery. Most real-world implementations end up being a pragmatic blend of both.
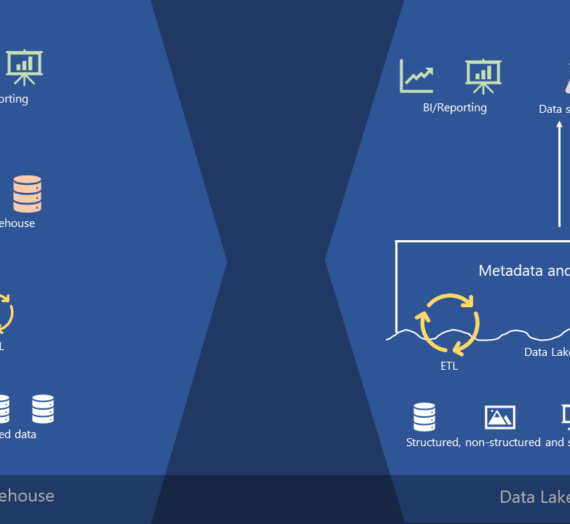
3. Data Lake – The Promise and the Swamp
Around 2010, a new concept emerged promising to solve all our problems (sounds familiar?): the data lake. The sales pitch was alluring – unlike a structured data warehouse, a data lake was essentially a massive, cheap storage space. You don’t need a plan, just dump everything in there: structured data, log files, PDFs, social media feeds, even images and videos. Store everything now, figure out what to do with it later.
This is the schema-on-read approach in practice. And unlike relational data warehouses, which provide both storage and compute, a data lake is just storage – no bundled compute engine. It relies on object storage, which doesn’t require data to be structured in tabular form.
For a while, the hype was real. Then reality hit. Storing data in a lake was easy – getting it out in a useful way was incredibly difficult. Business users were told: “Hey, all the data is in the lake! Just open a Jupyter notebook and use some Python to analyze it.” Most business users didn’t have advanced coding skills. The crystal-clear lake quickly became a murky, unusable data swamp.
But the data lake didn’t disappear. The industry realized the initial vision was flawed, but the core technology remained incredibly useful. Today, the data lake has found its true calling – not as a warehouse replacement, but as a staging and preparation area: the perfect place to land raw data before deciding what to clean, transform, and promote for reliable analysis.
4. Data Lakehouse — The Best of Both Worlds
When you combine a data warehouse and a data lake, what do you get? A data lakehouse. Databricks pioneered this term around 2020, and the concept has been gaining serious traction ever since.
I can almost hear you asking: “Wait, didn’t you just say data lakes failed spectacularly trying to satisfy exactly these requirements? Why would this work now?”
Fair question. There was a single change to the classic data lake approach, but it was big enough to shift the entire paradigm: adding a transactional storage layer on top of existing data lake storage. This layer, exemplified by Delta Lake, Apache Iceberg, and Apache Hudi, enables the data lake to work more like a traditional relational database management system, with ACID transactions, schema enforcement, and time travel.
The lakehouse promotes a compelling idea: remove the need for a separate relational data warehouse and leverage only a data lake for your entire architecture. All data formats: structured, semi-structured, and unstructured, are stored in the lake, and all analysis happens directly from it. The transactional layer is the missing ingredient that makes this feasible.
5. Data Mesh – Decentralizing Data Ownership
So data lakehouses solved the storage and analysis problem. Case closed, right? Not exactly. As companies grew, even a great centralized data platform created a new bottleneck.
Think of your central data team as the kitchen of a very popular restaurant. Marketing, Sales, Finance, and Logistics all place complex “orders” (data requests). The kitchen staff – your data engineers – are skilled but swamped. They don’t have deep, nuanced understanding of every “dish.” The marketing team asks for a customer segmentation, and the kitchen has to first ask: “What do you mean by an active customer?” The result? A long line of frustrated “customers” and a burned-out kitchen staff.
Data mesh asks a radical question: what if, instead of one central kitchen, we gave each department its own specialized kitchen station? And what if we made the domain experts – the people who truly know their own data – responsible for preparing high-quality data products for everyone else?
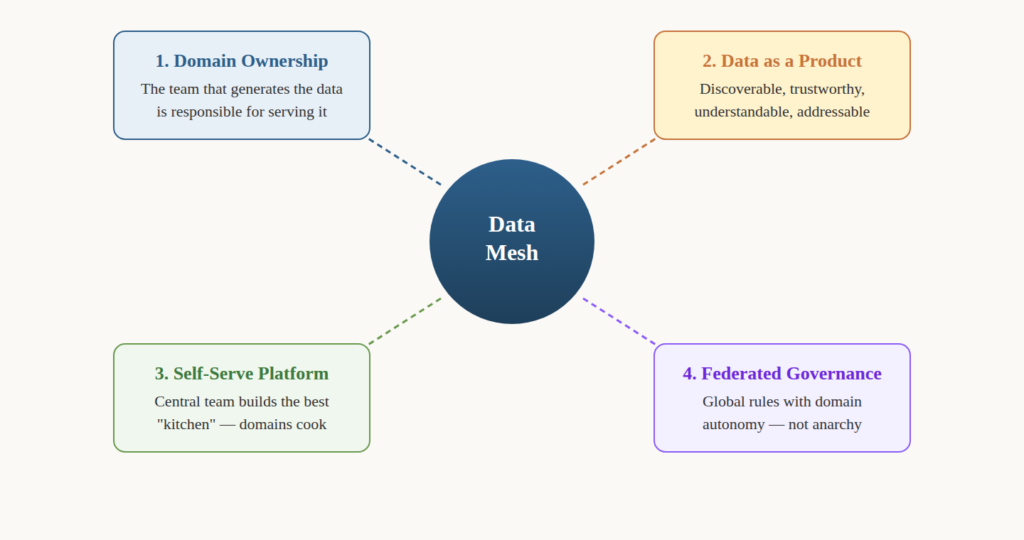
Data mesh rests on four key principles: domain-oriented ownership (the people closest to the data own it), data as a product (treated with the same care as any customer-facing product), a self-serve data platform (central team provides the infrastructure, domains build the products), and federated computational governance (global standards enforced through a council with domain representatives).
A word of caution: Data mesh isn’t a technology you buy and install. It’s a sociotechnical shift, as much about organizational structure and culture as it is about technology. It’s not for every company, especially smaller ones. Domain teams need genuine technical expertise and long-term commitment, and data sharing can easily become a political issue.
6. Event-Driven Architecture – The Gossipy Neighbor
Now let’s switch gears. Think of event-driven architecture as the gossipy neighbor approach to data – systems that react instantly to things happening, rather than constantly checking for updates. Instead of System B asking System A every five minutes “Hey, did anything happen yet?” (like checking your fridge hoping food has magically appeared), an event-driven system taps you on the shoulder the moment something important occurs.
A customer places an order? That’s an event. The system that creates it is the producer. The systems that listen and react are consumers. And the intermediary where events get posted is the event broker – think Apache Kafka, Azure Event Hubs, or Eventstream in Microsoft Fabric.
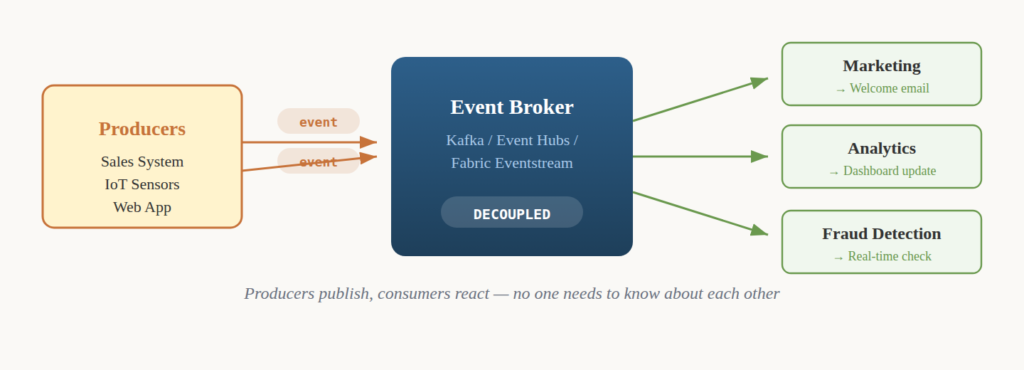
The beauty lies in the words loosely coupled. The Marketing team can spin up a new service that listens to “Customer Signed Up” events without requiring the Sales team to change a single line of code. If the welcome email service crashes, new customers still get signed up – the events just pile up in the broker, waiting for the service to recover.
But this power comes with trade-offs. You now have a new piece of infrastructure to manage. Debugging gets harder because when something goes wrong, tracing a single event across multiple decoupled systems can be a serious challenge. And the broker doesn’t always guarantee the order of delivery: you might get an “Order Shipped” event before the “Order Paid” event.
When to use it: Real-time analytics (IoT, clickstream, fraud detection), microservices integration, and asynchronous workflows.
When NOT to use it: Simple CRUD apps, tightly coupled workflows requiring immediate guaranteed responses, and strictly transactional systems where multi-step processes must succeed or fail atomically.
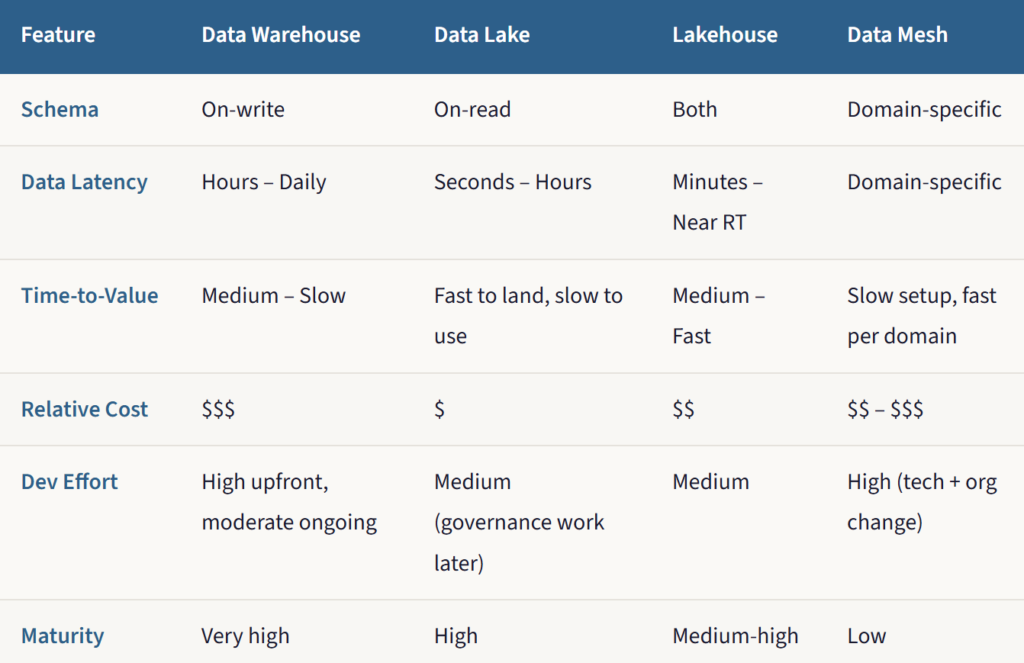
The Cheat Sheet
There’s no magic bullet – each architecture has its place. Here’s the quick comparison to help you decide:
The Key Takeaway
Understanding when to use what is the crucial skill for any analytics engineer. Every single day, you make decisions about how to structure data, where to store it, how to transform it, and how to make it accessible. These decisions might seem minor in the moment: Should I create this as a view or a table? Where should I put this transformation logic? – but they add up to create the foundation your entire analytics ecosystem sits on.
The data architecture landscape has evolved from normalized relational databases, through the “don’t touch the live system!” era of data warehouses, past the spectacular rise and fall (and redemption) of data lakes, into the lakehouse paradigm that gives us the best of both worlds. Modern approaches like data mesh push ownership to the people closest to the data, and event-driven architectures let systems react instantly rather than constantly polling for updates.
This article is adapted from the “Analytics Engineering with Microsoft Fabric and Power BI“ book.
Want the full deep dive with hands-on examples? Check out the book for the complete picture – including data modeling, medallion design pattern, and real-world Fabric implementations.
Last Updated on February 12, 2026 by Nikola