

If you’ve ever worked with traditional relational database management systems (RDBMS) and/or data warehouses, and you’re now trying to be a “modern data platform professional” and apply your skills in Microsoft Fabric, you may find yourself in uncharted territory. Not only because of the SaaS-ification of the environment, but also due to many puzzling “solutions”, or maybe it’s better to say – lack of the features that we were taking for granted in the “previous” (pre-Fabric) life.
The goal of this article is to introduce you with different approaches for overcoming the limitation of non-existency of the identity columns in Microsoft Fabric. Please keep in mind that all of these approaches are considered workarounds and it may happen that Microsoft in the future provide the out-of-the-box solution
One of these features is the identity column. In a nutshell, the identity column automatically assigns a unique identifier to each new row in the table. Most often, this value doesn’t have any business meaning – it’s just an artificial value generated by the database system to uniquely identify each record in the table. Hence, it’s often called a surrogate key. Unlike business keys (AKA natural keys), which may hold business meaning (for example, a combination of the store initials, location detail, and some numeric value, such as GC-USA-123), surrogate keys are completely meaningless and are usually represented by an integer value starting from specific value (usually 1, but it can also be a negative value) and linearly increasing by particular whole number value (again, usually, but not necessarily, by 1).
Setting a column like this in SQL Server, or any other traditional relational database management system, was as simple as providing a few additional properties when executing a CREATE TABLE statement:
CREATE TABLE customer (
customerID INT IDENTITY(1, 1),
firstName VARCHAR(20),
lastName VARCHAR(100),
email VARCHAR(100)
);
In the above code snippet, by defining the additional IDENTITY property, we are delegating to SQL Server the task of ensuring that each new row is automatically assigned a unique integer value, starting from 1 and linearly increasing by 1. Hence, whenever a new record comes into the table, SQL Server is responsible for handling the data integrity and uniqueness of every single record.
This was (is) true for every similar RDBMS (Oracle, MySQL, PostgreSQL). However, the same can’t be said for Microsoft Fabric. Before we examine how to overcome this limitation in Fabric in multiple possible ways, let’s first try to explain WHY something so essential as the identity column is not supported in Fabric.
Single-node vs. Distributed architecture
The aforementioned RDBMSs (SQL Server and co.) are all single-node architectures. This means, all the data resides on a single node, and the system can guarantee that the data is written and stored at one single location.
In a distributed architecture, the work is spread across multiple nodes, where each node is responsible for handling smaller chunks of the data. Ensuring that each node in the distributed system assigns unique values, without any overlap or data integrity violations, would require complex synchronization between nodes, which can then cause performance issues.
Unlike Microsoft Fabric, Databricks does support creation of identity columns in their lakehouse, by providing two options: GENERATED ALWAYS AS IDENTITY and GENERATED BY DEFAULT AS IDENTITY. However, as per Databricks documentation, declaring an identity column on a Delta table disables concurrent transactions. They advise for using identity columns only in use cases where concurrent writes to the target table are not required. You can read more about creating identity columns in Databricks here
However, let’s focus on current options when working with Microsoft Fabric. If you’ve read my introductory article on Fabric, you might already know that the entire Fabric platform is all about the options: this means, you can perform almost every single task in multiple different ways, where using one doesn’t necessarily mean others are bad or inappropriate. Simply, it depends on various factors. Some of these include, but are not limited to:
- Where do you want to store the data in Microsoft Fabric (Lakehouse or Warehouse)? This decision might have implications for the engine that will write data into Fabric
- What is the data source? For example, notebooks can’t be used to ingest on-prem data
- Should a solution provide a low-code/no-code framework, or a code-first approach?
- What are the tools of trade of your data team (SQL, Python, or something else like Scala:))?
Essentially, it boils down to choosing between using Dataflows Gen2 as a low-code/no-code approach versus notebooks and SQL as a code-first approach. Thus, in the remaining part of the article, I’ll show you how to implement a workaround for creating identity columns with all of these three options (Dataflows Gen2, notebooks (PySpark), and T-SQL).
Please keep in mind that the key idea is always the same, regardless of which approach you choose – find the maximum current value in the column that uniquely identifies a record in the table, and assign the next value in a sequence to newly created records.
#1 Dataflows Gen2
Let’s start with the option that most citizen developers prefer – Dataflows Gen2. I’ll assume you already know how Dataflows Gen2 work. The focus here is really on understanding how to generate an identity column with Dataflows Gen2.
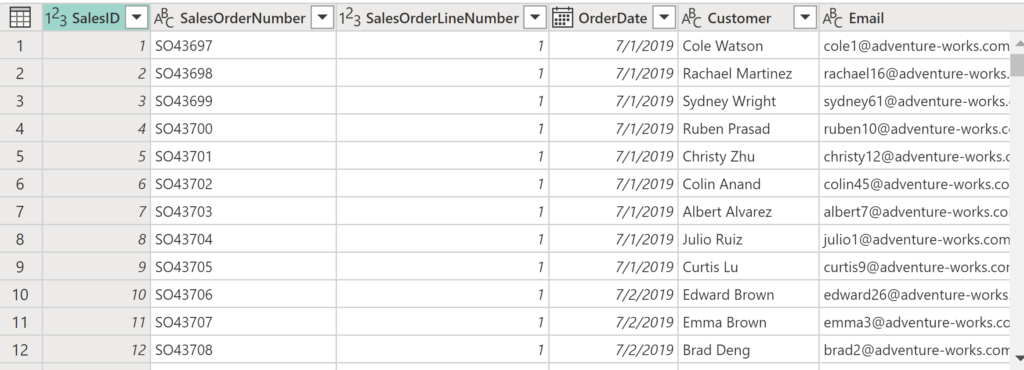
As you may notice in the screenshot above, my table contains a natural key SalesOrderNumber, which I’m using to create a surrogate key SalesID, which starts from 1 and linearly increases by 1. The question is: What happens when new rows are inserted in this table? How do we automatically assign linearly increasing values to these records?
Let’s start building a workaround solution. First, as I already mentioned, we need to figure out the maximum value in the SalesID column. This can be done by using the Number Column transformation, and then choosing the Maximum under Statistics:
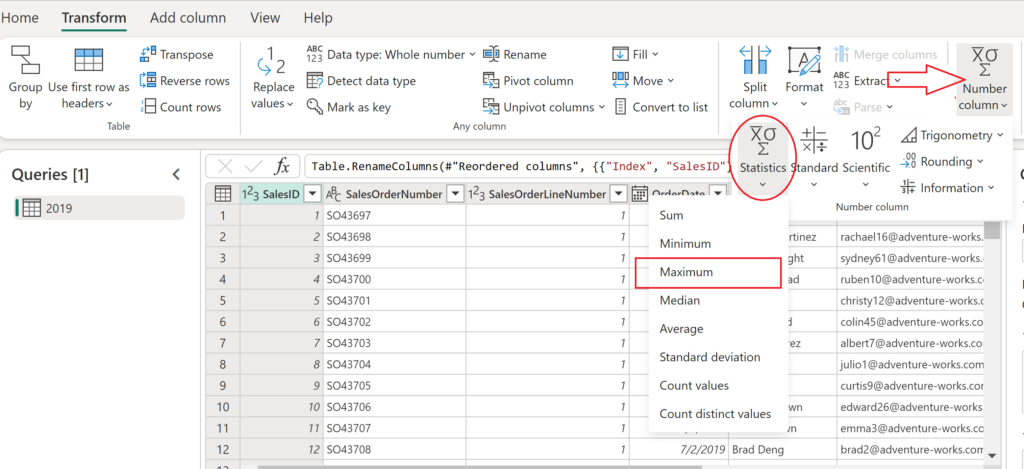
This will create a list containing the maximum value in the column, which is, in my case, 1201. Next, I’ll create a custom transformation step, by right-clicking the transformation step Calculated maximum and choosing Insert step after. Then, in the formula bar, simply add 1 to the result of the Calculated maximum step, similar to the following:
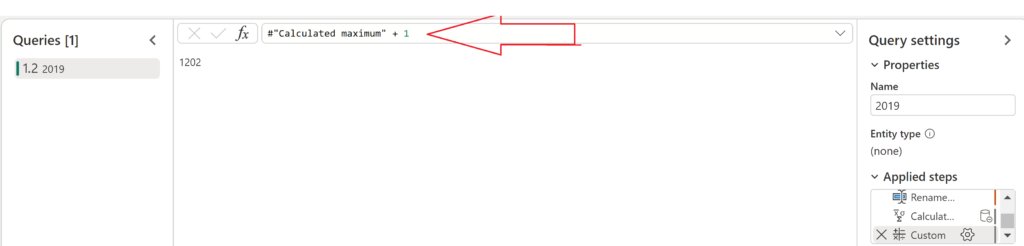
Now, imagine that new data arrives (without the SalesID value) and we need to start assigning SalesID continuously, starting from 1202. I’ll first add an Index column to my new data:
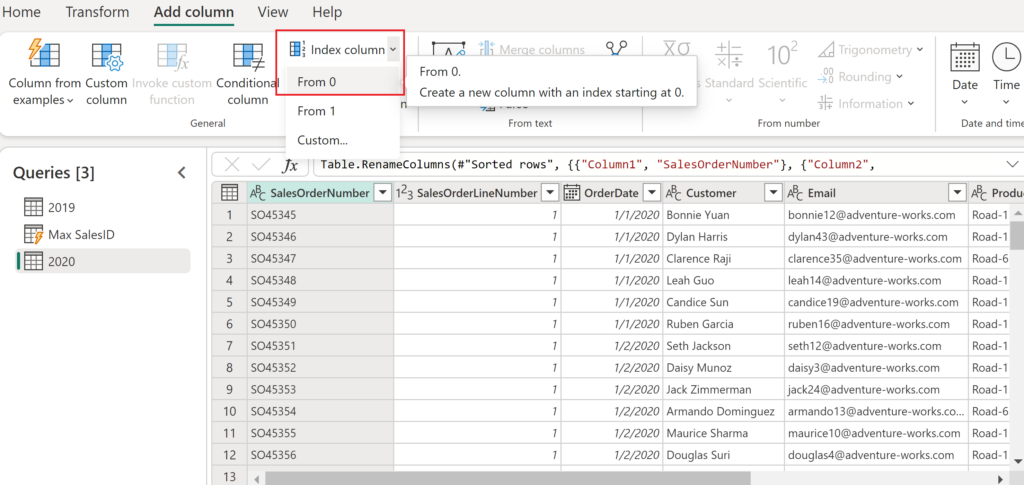
This will create a new column where values start from 0 and increase by 1. However, remember that we don’t want to start from 0, but from 1202 (that’s the maximum current SalesID value + 1). Therefore, I’ll simply replace the starting point of the index (0) with the result of the query Max SalesID:
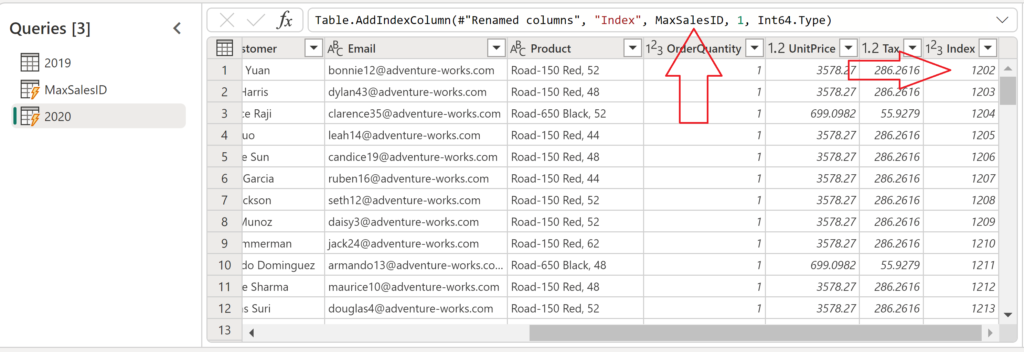
As you see, the ID values for the new records start at 1202, so we can now append these records to our existing table, without violating data integrity.
Please keep in mind that this is definitely not the most optimal solution, especially in scenarios when dealing with large amounts of data.
#2 Notebooks
Notebooks are a versatile solution for various tasks in Microsoft Fabric. Within a single notebook, you can leverage different programming languages, such as PySpark, Scala, and SparkSQL, to perform different sets of tasks. Therefore, similar to the previous scenario, let’s imagine that we have an existing table that already contains SalesID information, and our goal is to automatically assign ID values to newly inserted records.
There are multiple ways to handle this requirement, and some of the most common functions used are:
- monotonically_increasing_id()
- row_number()
- Rank OVER,
- ZipWithIndex()
- ZipWithUniqueIndex()
For this example, I’ll use the first from the list: monotonically_increasing_id(), which is a SparkSQL function. Its name is self-explanatory – it generates monotonically increasing 64-bit integers, which are guaranteed to be unique, but not consecutive. The function is non-deterministic because its result depends on partition IDs.
Let me demonstrate how this function works using a very basic example.
from pyspark.sql import functions as f spark.range(0, 20, 1, 4).select(f.monotonically_increasing_id()).show()
The code above will create a dataframe, where values start from 0 and end at 20. Values in the range increase by 1, and they are split into 4 partitions (the last argument of the range). Results might not be something you would expect to see:

Each partition has its own “counter”. And, whenever a new partition starts, the initial ID value is increased by ca. 8.5 billion. As Christian Henrik Reich nicely described in his article, a challenge with the monotonically_increasing_id() function is in those scenarios when there is a need for the scale-out processing and counting unique IDs, because it’s hard to determine the count in each of the partitions working in parallel. When processing partitions, such information is not shared.
It is not an issue if there is only one partition to process, because then the counter goes from 0 to the number of rows in the partition. However, it’s important to keep in mind that a partition is not the same as a table. A partition represents a set of data processed in Spark memory. Since Spark is a distributed architecture, sometimes it may happen that even with a small amount of data, multiple partitions are created.
The approach with Spark is the same as with Dataflows Gen2 – identify the current maximum value in the SalesID column, and then add the value generated by the monotonically_increasing_id() function to produce sequential integers as a surrogate key. The current maximum SalesID value is 1200:
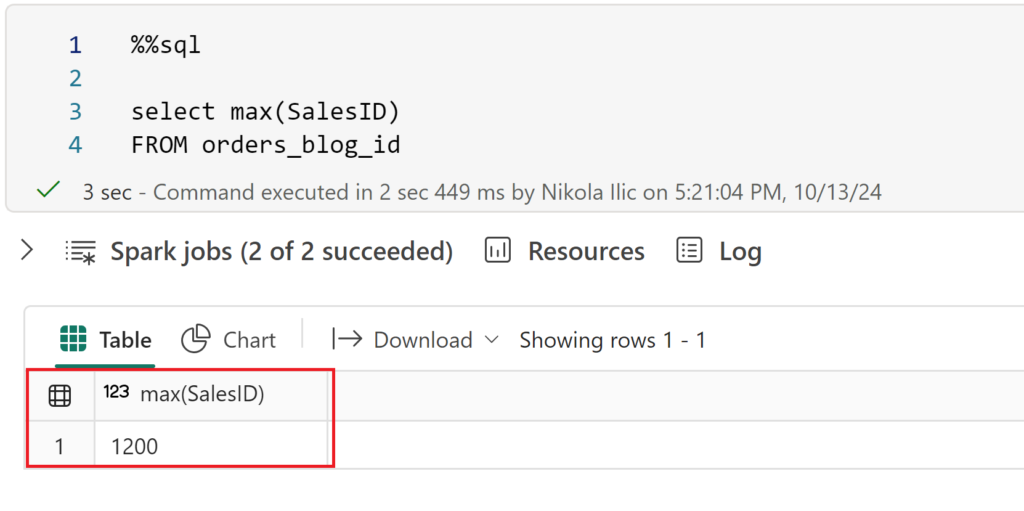
So, we now need to import a new batch of records, and assign SalesID value 1201 to the first record of the new batch. To achieve this, I’ll be using the aforementioned monotonically_increasing_id function:
from pyspark.sql.functions import *
dforders_temp = spark.read.table("orders_blog_id")
MAXSalesID = dforders_temp.select(coalesce(max(col("SalesID")),lit(0)).alias("MAXSalesID")).first()[0]
dforders = dforders.join(dforders_temp,(dforders.SalesOrderNumber == dforders_temp.SalesOrderNumber), "left_anti")
dforders = dforders.withColumn("SalesID",monotonically_increasing_id() + MAXSalesID + 1)
# Display the first 10 rows of the dataframe to preview your data
display(dforders.head(10))
And, when we take a look at the dataframe I just prepared in the notebook, you may spot that the first record has a 1201 value as SalesID:
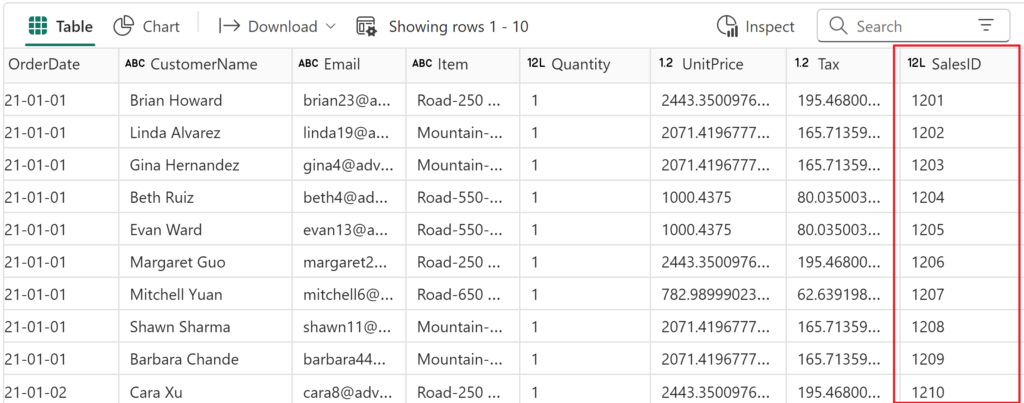
Now, when we check the table again, we’ll see that new records from the year 2020 are inserted, and SalesID sequentially increases:
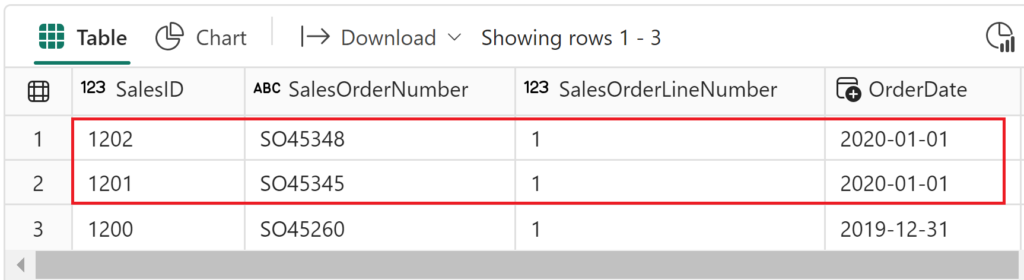
#3 T-SQL
Let’s wrap up by examining how T-SQL can be leveraged in the identity column workaround scenario. I’ll use the existing orders_blog_id table, which was created in the previous example with the notebooks. However, since we need to insert the data into the delta table in Fabric, and we plan to use T-SQL, it has to be done in the Fabric Warehouse, because Lakehouse supports read-only T-SQL statements.
Once again, we will start by identifying the current maximum value in the SalesID column:
DECLARE @MaxID AS BIGINT;
IF EXISTS(SELECT * FROM [dbo].[orders_blog_id])
SET @MaxID = (SELECT MAX([SalesID]) FROM [dbo].[orders_blog_id]);
ELSE
SET @MaxID = 0;
Currently, the maximum value in the SalesID column is 3932, so we want our newly inserted records to start from 3933.
Let’s say that there is a new batch of data for the year 2021, which has to be inserted in the orders_blog_id table:
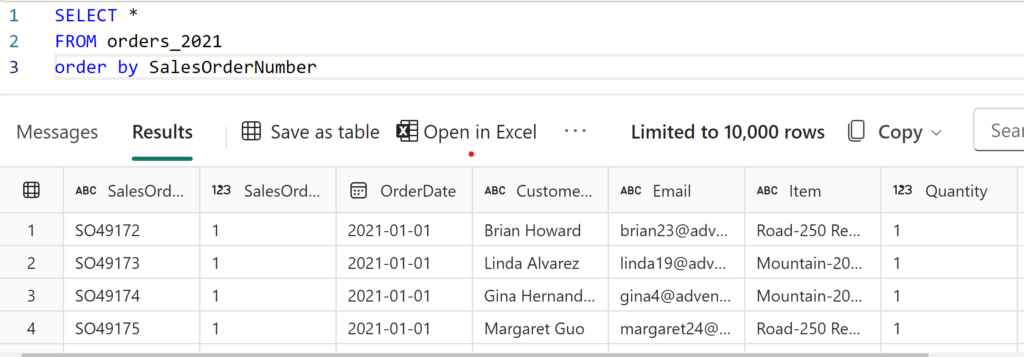
Next, I’ll use a ROW_NUMBER function in T-SQL to generate a series of sequential numbers. ROW_NUMBER always starts from the value 1, so we will essentially add the output of the ROW_NUMBER function to our current maximum SalesID value:
DECLARE @MaxID AS BIGINT;
IF EXISTS(SELECT * FROM [dbo].[orders_blog_id])
SET @MaxID = (SELECT MAX([SalesID]) FROM [dbo].[orders_blog_id]);
ELSE
SET @MaxID = 0;
--Insert new rows with unique identifiers
INSERT INTO [dbo].[orders_blog_id] (SalesID, SalesOrderNumber, SalesOrderLineNumber, OrderDate, CustomerName, Email, Item, Quantity, UnitPrice, Tax)
SELECT
@MaxID + ROW_NUMBER() OVER(ORDER BY SalesOrderNumber) AS [SalesID]
, SalesOrderNumber
, SalesOrderLineNumber
, OrderDate
, CustomerName
, Email
, Item
, Quantity
, UnitPrice
, Tax
FROM [dbo].[orders_2021] AS [o];
The code above first retrieves the current maximum SalesID value. Then, we are iterating over the table, which contains data for the year 2021 and adding the output of the ROW_NUMBER function to the current maximum value. Finally, we are inserting these records into our existing table.
Let’s check if the workaround was implemented successfully:

Worked like a charm!
Conclusion
Regardless of how fantastic the Microsoft Fabric platform is, numerous limitations remain that may hinder the implementation of data analytics solutions the way we have been doing them for years (or maybe even decades). The Identity column feature is an excellent example of the “missing puzzle” in Microsoft Fabric. Hence, we still have to rely on some workarounds and “hacks” to get the job done. Luckily, these workarounds can be implemented in Fabric in multiple different ways, and I hope this article helps you choose the solution that will play to your strengths. At least, until Microsoft hopefully resolves this limitation in the future:)
Thanks for reading!
Last Updated on October 3, 2025 by Nikola


Onur Oz
When you have concurrent parallel data loads, MAX(ID) + ROW_NUMBER() is a terrible strategy. Identity is a very basic and fundamental functionality, shipping a product without that is like shpping a car without mirrors. Yes, the car will go, irregardless of the mirrors.
Nikola
Hi Onur,
Completely agree with you that this functionality should be available out-of-the-box. I was just trying to offer some workaround solutions (hopefully temporary) to overcome this limitation.
Onur Oz
Hi Nikola,
all your workarounds are completely valid and the best alternatives to the current limitation, with one big caveat though. I suggest mentioning/highlighting this caveat (duplication in parallel run) in your post as a warning-box will help careless readers (TL;DR; practitioners :)) before they go on that path, or at least they know the side-effects before going on that path.
Thanks anyway for your work, well explained.
Nikola
This is a great point, thanks! I’ll update the post accordingly
Carsten Cohrs
Thank you for sharing!
Why do we need such numeric surrogate keys? Of course, those keys make our data management simpler. But mainly, we need it to create relationships in our sematic models later. The next thing: Are numeric surrogate keys the best way to create such relationships? As you will need look-ups to create a possibility for relationships from your fact tables also other ways may be of interest. Such as hash values for example. Here you won’t need look-ups in fact tables. But here: Hash values are not numeric. They can be converted to alphanumeric values. Another possibility is given by CHECKSUM function. This function creates numeric values of type integer (32 bit). But considering the birthday paradoxon this is only applicable for small “dimensions”.
Many questions are still open in this matter. Especially concerning semantic models. How important are numeric values to create relationships for larger models with bigger amount of data? Should those values have a continuous area of values?
Nikola
Hi Carsten,
These are all great points, thank you very much for sharing.
john
so what can be proposed here? do we need identity columns as numbers or we can use hash values?
Nikola
Hi John,
Until Microsoft provides out of the box identity column feature, we can use hash values as a workaround.
Lukas
Just use uuids?
Valentin
I used an approche from datavault by generatting a hash key for the business columns .