

My dear Microsoft Fabric and Power BI friends – if you were confused or felt lost with the Direct Lake mode in Microsoft Fabric, I have “great” news for you – things just got even worse😀😀😀
Before you proceed, in case you don’t know what Direct Lake is, I’ve got you covered in this article, where you can learn and understand various Direct Lake concepts, as well as in which scenarios you might consider implementing Direct Lake semantic models. Now that you know what Direct Lake is, let’s digest the latest news…
A couple of days ago, I was reading the official blog post about the latest enhancement to the Direct Lake storage mode for semantic models in Microsoft Fabric. The official blog post can be found here.
TL:DR; We now have TWO different Direct Lake mode “flavors” (the flavor is just my phrase, and not the official one by Microsoft) – Direct Lake on OneLake and Direct Lake on SQL.
For the sake of clarity – Direct Lake on SQL is just the “good old” Direct Lake that we’ve known, and was the only Direct Lake option since the introduction of Microsoft Fabric. So, if you ever created or played around with Direct Lake before April 2025, this experience has now been renamed to Direct Lake on SQL. And, to cut the story short, it works and it will go on working exactly the same as before April 2025 – the only difference is the name…
The brand new “thingy” is the Direct Lake on OneLake!
After reading the official blog, I have to be honest and admit that I didn’t understand why this new Direct Lake “flavor” might be a big deal, so I reached out to my fellow community experts, whose opinion I deeply respect, and asked if I was missing something obvious. I got a bunch of helpful hints, but nevertheless, I decided to play around on my own and share my personal thoughts about this new feature.
Direct Lake on OneLake vs. Direct Lake on SQL
But, first things first. Let’s kick it off by exploring the key differences between the two Direct Lake implementation options. First and foremost, when using Direct Lake on OneLake, you are connecting directly to OneLake delta tables, whereas if you choose a SQL flavor, the data is being accessed via the SQL analytics endpoint of the lakehouse or warehouse. This distinction impacts many of the available functionalities of Direct Lake semantic models.
Probably the most significant difference is that with Direct Lake on OneLake, a semantic model may contain tables coming from more than a single Fabric item. Let’s illustrate this on a simple real-life example. Imagine you have a Customer table stored in Lakehouse A, a Product table stored in Lakehouse B, and a Sales table stored in Warehouse C. All these tables can be part of the single Direct Lake on OneLake semantic model.
This is not the case with the Direct Lake on SQL semantic models, which may contain tables only from a single Fabric item. Going back to our previous example: you would have to create a shortcut in Lakehouse A that points to the Product table in Lakehouse B, and bring Sales table data into Lakehouse A as well, in case you want to use all of them in the Direct Lake on SQL semantic model.
Next, the Direct Lake behavior, which determines what happens in case Direct Lake queries don’t work, is completely different between these two flavors. In Direct Lake on OneLake models, there is no possibility to leverage DirectQuery mode for queries that can’t use Direct Lake mode. It’s simply Direct Lake or nothing, whereas with Direct Lake on SQL, queries can still “talk” with the SQL analytics endpoint, thus DirectQuery fallback behavior is still a viable option.
Last but not least, Direct Lake on OneLake models are authored and managed in the Power BI Desktop. On the flip side, Direct Lake on SQL models can be created from the Fabric web interface exclusively, although once created, they can be edited in the Power BI Desktop afterward.
A decision on which Direct Lake flavor to use depends on various criteria. Here is the list of some of the common considerations:
| Criteria | Direct Lake on OneLake | Direct Lake on SQL |
| Number of data sources to create a semantic model | Multi-source | Single-source |
| DirectQuery requirements | Not supported | Supported |
| Use database views as a data source | Not supported | Supported (will fall back to DirectQuery) |
| Permission model | Depends on each data source itself | Depends on the SQL analytics endpoint of the data source |
| Model authoring | Power BI Desktop | Fabric Web UI |
Direct Lake on OneLake in action
Creating a Direct Lake on OneLake semantic model starts by opening the OneLake Catalog from Power BI Desktop and choosing the Fabric item you want to use from the dropdown menu, as displayed in the following illustration:

The next step is crucial, because it determines if you are going the OneLake or SQL route. The following screenshot illustrates two available options when connecting to the Fabric lakehouse:

Let’s imagine that I’ve decided to create a Direct Lake on OneLake semantic model. Once I pick the tables from the selected lakehouse, the entire process of creating and managing a semantic model doesn’t vary much from the regular process of creating any other semantic model type, such as Import or DirectQuery.
The only difference is that, once created, you don’t need to publish the model to the Fabric workspace – it will be automatically saved in the workspace you specified during the model creation. You can also enhance the semantic model by creating typical model objects, such as relationships, measures, or calculation groups, to name a few. However, bear in mind that all the changes you apply to the model in Power BI Desktop are immediately saved back to the model in the service, so all Power BI reports that are live connecting to that model will instantly include all the updates – for better or for worse…
On the other hand, if you try to create a brand-new Direct Lake on SQL semantic model from Power BI Desktop, by selecting the same lakehouse item, you won’t be allowed to do that, since Power BI will prompt you to choose between the Import and DirectQuery modes in that case. However, you can connect and edit the existing Direct Lake on SQL semantic model, which was previously created and saved in the Fabric workspace.
The interesting thing may be adding new tables to the model from the multiple Fabric items, since this is not available in the SQL version. It really is as simple as opening the OneLake catalog in Power BI Desktop and picking the tables from multiple Fabric items:
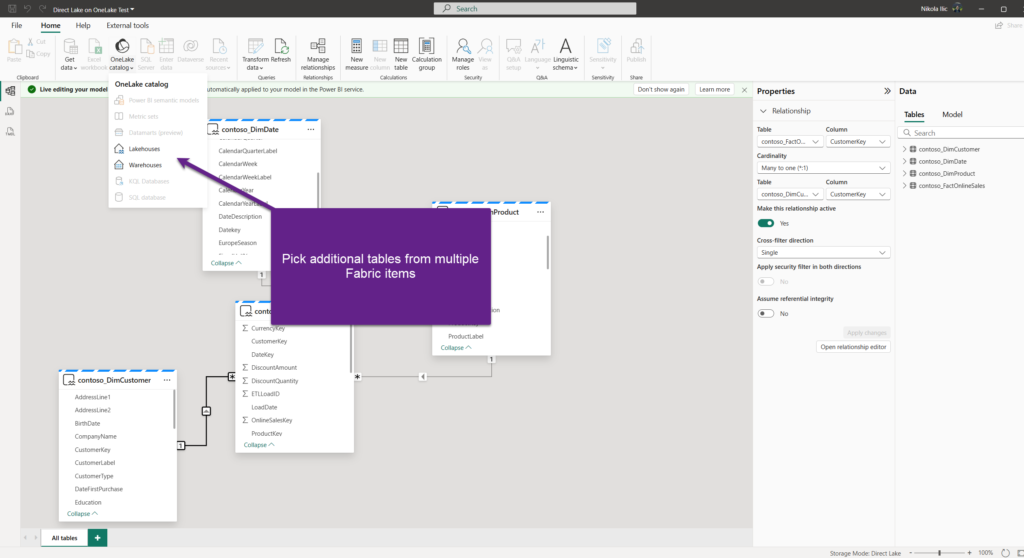
As you may notice, it’s only lakehouses and warehouses supported at the moment of writing, so you can’t add, let’s say, tables from KQL databases (in case you enabled OneLake integration) or SQL databases to the existing model. However, we should expect other Fabric items to be supported in the future as well.
The nice thing is that both TMDL and DAX query views are available for Direct Lake on OneLake semantic models, providing additional capabilities for developers working on these models.
Why Direct Lake on OneLake is (not) a big deal?
In full honesty, I’m still trying to get my head around this new enhancement. Is it a groundbreaking feature? No, it’s definitely not. Is it a natural evolution thing (that’s what my friend Tom Martens and I concluded when discussing it internally)? Yes, absolutely! Does it make our lives as Power BI and Fabric professionals easier? Oh, yes, for sure! I’ll give you two reasons from the top of my head (probably there are many more, and I would like to hear others’ opinions as well):
- We don’t need to create shallow lakehouses/warehouses that serve a sole purpose of being a blueprint for the Direct Lake semantic model(s), and create all these internal shortcuts to bring the data from multiple lakehouses. Now, you can mix tables from multiple Fabric items in a single Direct Lake semantic model. This is HUGE!
- We can use Power BI Desktop for creating and managing Direct Lake models, the same as we were doing for years with Import and DirectQuery
What does the future bring for Direct Lake in general? Will we see the “SQL flavor” slowly dying and becoming obsolete now that we have a new hero in town? Honestly, I don’t know the answer, but here is my personal opinion: I don’t see why someone would go the “SQL route” starting from today! The only viable reason would be to have a DirectQuery fallback as a “Plan B” in case Direct Lake doesn’t work. Don’t forget, there is no possibility to use DirectQuery in Direct Lake on OneLake.
Performance-wise, I would also assume (but this is just my assumption, which I couldn’t confirm by running some initial tests and comparisons) that the OneLake version will provide a better experience in syncing between the OneLake and semantic model data, since there is no “man-in-the-middle” AKA SQL analytics endpoint anymore. But, this is yet to be confirmed.
Additionally, once we have OneLake Security in place (and this is a significant shift in how security is handled in Microsoft Fabric), this new option should provide even more advantages, because the security rules will be enforced directly on the delta table, and automatically propagated to the Direct Lake semantic models (you don’t need to worry about the SQL analytics endpoint permissions).
Looking forward to hearing others’ thoughts and opinions.
Thanks for reading!
Last Updated on April 28, 2025 by Nikola


Bob
Great article! Should have used comic sans.
Filip
I noticed one difference today, if made the correct conclusion: If the datatype of a column in a Primary key relationship changes, this will rendering an unspecified error in OneLake mode (cannot connect) when trying to Edit tables. In SQL Endpoint mode, this is actually explicitly stated and gives you some valuable information.