THE Strongest Link! 5 Reasons why Semantic Link IS the Fabric big deal
by Nikola
3 Comments
Since Microsoft Fabric was publicly unveiled in May 2023, there has been an ocean of announcements around this new platform. In full honesty, plenty of those were just a marketing or rebranding of the features and services that already existed before Fabric. Hence, in this ocean of announcements, some features went under the radar, with their true power still somehow hidden behind the glamour of those “noisy neighbors”.
Semantic Link is probably one of the best examples of these hidden Fabric gems.
This is the excerpt from the early release of the “Fundamentals of Microsoft Fabric” book, that I’m writing together with Ben Weissman (X) for O’Reilly. You can already read the early release, which is updated chapter by chapter, here.
Despite all of the other data science and machine learning tools and features, such as MLFlow, SynapseML, and AutoML, I sincerely consider Semantic Link as one of the revolutionary features in the entire Microsoft Fabric realm, because it opens a whole new world of possibilities when creating a unified view of data across multiple disparate sources.
If you take a look at the official documentation, you’ll learn that “Semantic link is a feature that allows you to establish a connection between semantic models and Synapse Data Science in Microsoft Fabric”. Doesn’t sound too exciting, right?
But, what if we tell you that you can leverage this feature to optimize your Power BI semantic models quickly? Or to visualize all dependencies between tables, columns, and measures in the semantic model? How about running the DAX code from the Fabric notebook? These are only some of the Semantic Link use cases. And this is just for the starter.
In this article, we’ll examine some handy implementations of the Semantic Link feature in real-life scenarios.
A short journey through the evolution of a data scientist <-> BI developer collaboration
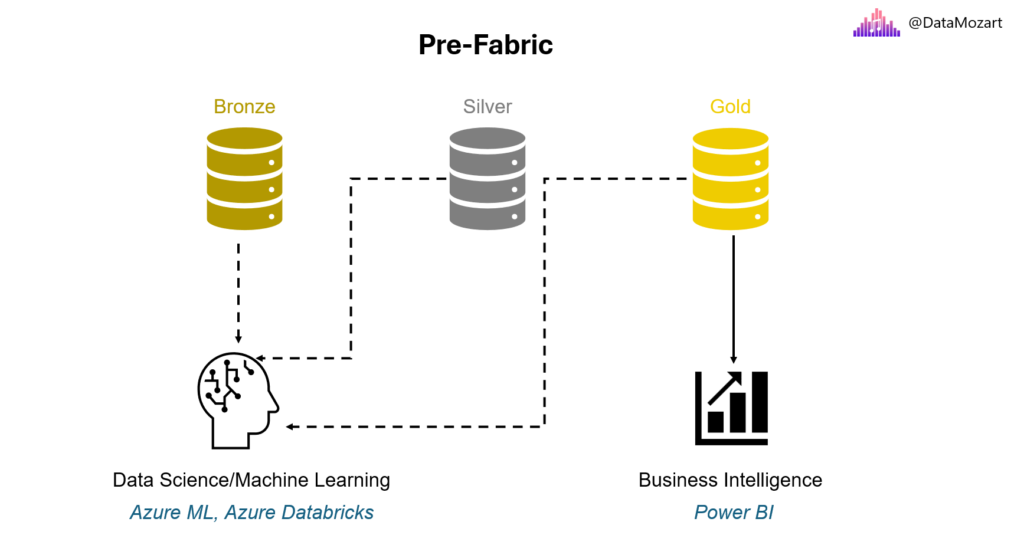
However, let’s first take a short ride through the evolution of collaborative work between a data scientist and a BI developer – if something like that had even existed in the past.
In the following illustration, you may notice how these two personas were totally isolated in the pre-Fabric era:
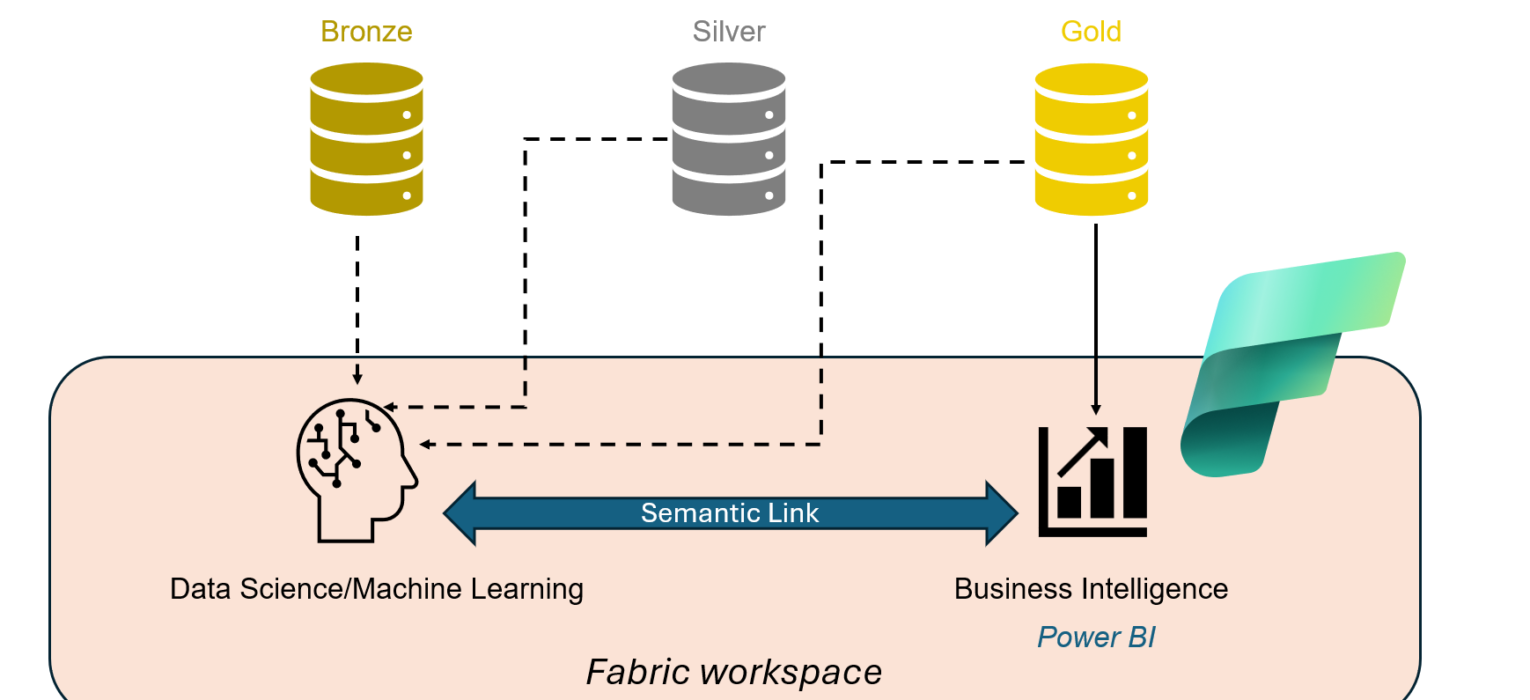
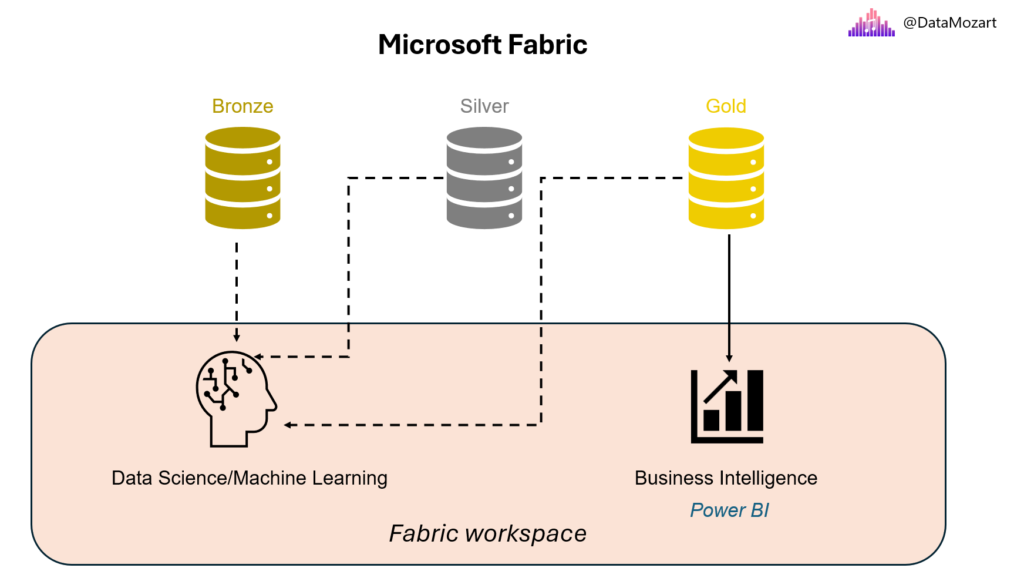
As you’ve already learned, Microsoft Fabric was introduced as an end-to-end analytics solution, where all data personas can seamlessly collaborate and access the “one copy” of the data stored in OneLake. The following figure depicts how Fabric provided a unified location for all data professionals in the form of the Fabric workspace:
Fabric workspace as a unified container for various items
However, regardless of how big a step this was in the direction of unification, these workloads were still isolated and seen as separate solutions. There was no way of unifying data science workloads with BI reporting and vice versa. Well, not before Semantic Link entered the stage.
The next figure shows how Semantic Link creates a bridge between data science and Business Intelligence by providing the possibility to leverage semantic model data in data science using a familiar set of tools: Notebooks, Python, and Spark, to name a few of the most popular.
Semantic Link as a bridge between data science and BI
Semantic Link relies on a special Python library called sempy. This library enables connecting to any Power BI semantic model and accessing all the information about the model – including, but not limited to – relationships, measures, calculated columns, and many more.
What’s even more powerful, if the Read/Write for XMLA Endpoint in the Admin Portal is enabled, you can also apply changes to existing semantic models directly from the Fabric notebook! This opens a whole new world of possibilities, as previously, writing via XMLA Endpoint was an exclusive privilege of various external tools, such as Tabular Editor, VS Code, and similar.
5 Real-life Semantic Link implementations
Let’s now examine five real-life scenarios where Semantic Link may be used to enhance the development process.
Writing Python code is not something you would expect from every data professional. Hence, the credit for the ease of use of various Semantic Link implementations goes to Michael Kovalsky. Michael works at Microsoft, and he created and maintains an entire library called Semantic Link Labs: https://github.com/microsoft/semantic-link-labs. This library extends the generic sempy library and consists of multiple ready-made functions you can use out-of-the-box to leverage Semantic Link feature in Microsoft Fabric
#1 Visualize dependencies in the semantic model
How many times have you had to deal with monster semantic models – you know, those models consisting of tens or even hundreds of tables, with spaghetti relationships all over the place, and hundreds of measures and calculated columns implemented to enrich the model with additional business logic? Yes, I know, we’ve all been there.
Wouldn’t it be great if we could somehow visualize all dependencies between various structures in the model?
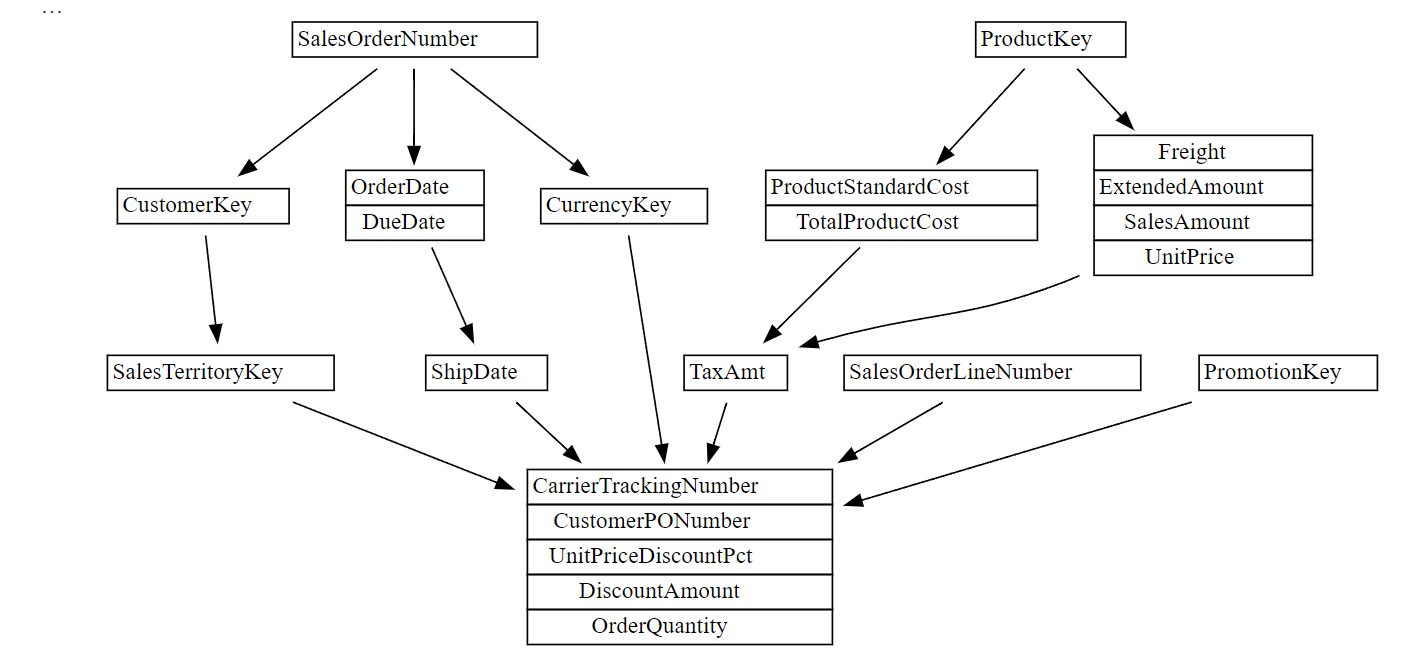
The following figure illustrates a dependency tree of the FactInternetSales table from the sample Adventure Works database. I was able to plot the dependency tree by executing literally six lines of Python code.
import sempy.fabric as fabric
from sempy.dependencies import plot_dependency_metadata
dataset = "S1"
sales = fabric.read_table(dataset, "aw_FactInternetSales")
dependencies = sales.find_dependencies()
plot_dependency_metadata(dependencies)
Similarly, I could have also visualized measure dependencies, as shown in the next illustration:
There are also plenty of other built-in functions that enable you to analyze and understand all the details of the semantic model.
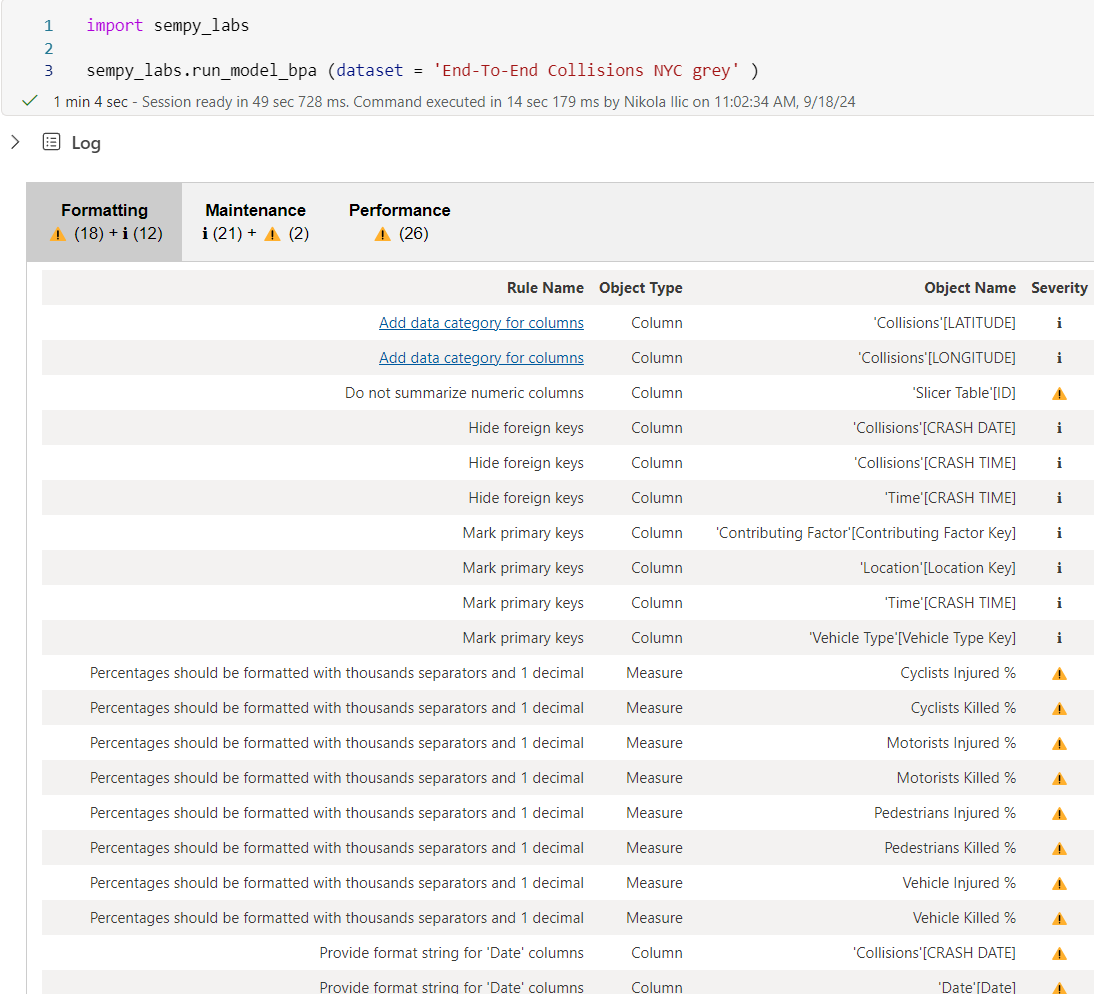
#2 Optimize semantic models with Best Practice Analyzer rules
For all of you who consider yourself a professional Power BI developer, Best Practice Analyzer (BPA) probably sounds familiar. In a nutshell, BPA scans the semantic model and flags all the issues found in the model. Think of finding the inappropriate usage of data types, bad practices in writing DAX code, and sub-optimal relationship types, all the way to alerting if the columns are missing descriptions. Based on the findings, you may decide to apply fixes to the model directly, or to ignore the warning simply.
Before Semantic Link, this task could have been performed exclusively by using the external tool Tabular Editor. Best Practice Analyzer is essentially the extension that one needs to install within Tabular Editor. With Semantic Link, the same outcome can be achieved directly from the Fabric notebook.
Figure below shows the result of the semantic model scan using the Best Practice Analyzer in the notebook:
What’s even more powerful – and this is one of the huge advantages compared to the “old-fashioned” BPA in Tabular Editor – you can now run Best Practice Analyzer rules in bulk! This means, with a single line of code, you can scan all semantic models in a workspace. This was not possible before Semantic Link, because in Tabular Editor, BPA can scan one model at a time.
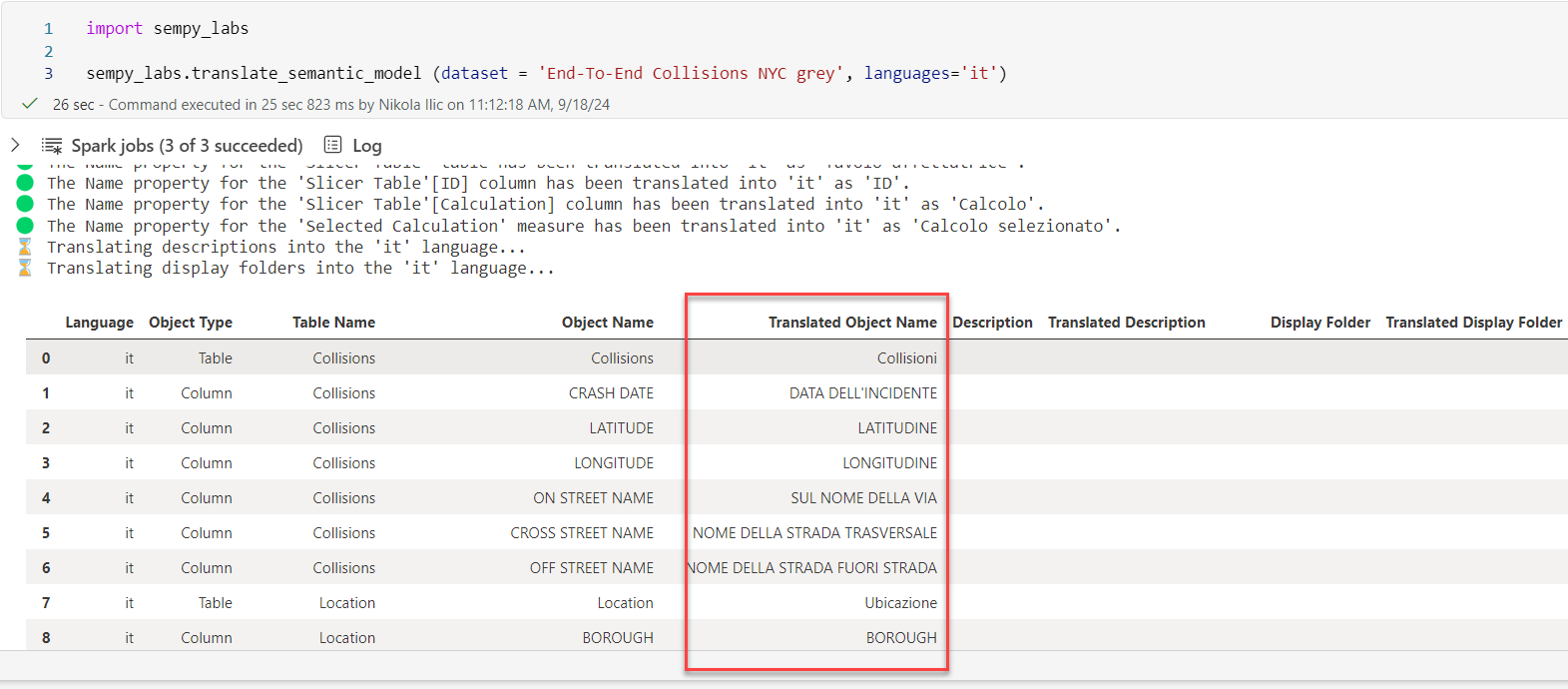
#3 Translate semantic models
In real life, it’s common to have users speak different languages. This is especially relevant in enterprises doing their business in different countries, where each subsidiary prefers to have the data in their local language.
Let’s imagine that our company has a subsidiary in Italy, and users from Italy want to see the data in their language.
To achieve this fairly simple requirement, before Semantic Link, someone who is proficient in both, let’s say, English and Italian had to stroll through the model and manually translate each object! Many workarounds were also introduced over time, but the sad truth is that translating model metadata was a tedious and daunting task.
With Semantic Link, it requires a single line of code. I know that this sounds too-good-to-be-true, so please take a look at the following figure, which shows how the model objects were translated into Italian:
The only thing you need to do is to provide the model name and the desired language. Semantic Link will take care of all the hard work in the background.
#4 Migrate existing semantic models to Direct Lake
Currently, most Power BI semantic models are using either Import or DirectQuery storage mode, or are built as composite models. Don’t worry, I also cover all these options in depth in the Power BI chapter of the book. However, chances are that with the expected growth in Fabric adoption, more and more Power BI semantic models will be using Direct Lake mode.
While creating a Direct Lake model from scratch is fairly easy and straightforward process, the legitimate question would be: what happens with thousands of existing Import and DirectQuery models? Do we need to recreate the entire model from zero, including establishing all relationships, recreating tens or hundreds of measures, and rebuilding hierarchies and calculation groups?
And I also wrote a detailed blog post on how to do it step-by-step, which you can find here.
By leveraging various Semantic Link Labs built-in functions, you can extract the entire model structure and business logic implemented into a model and recreate the model to use Direct Lake mode, without any manual intervention or need to rebuild from scratch. Not only that, but you can easily rebind all the existing reports to new Direct Lake models. Do I need to tell you how powerful it is? And, the best thing is that it’s feasible by running a single line of Python code:
This will probably be one of the most common use cases for Semantic Link in the coming months, as many organizations seek the most convenient way to migrate their existing Import and DirectQuery models to Direct Lake.
#5 Augmenting the gold layer
If we agree that the gold layer contains business-reporting-ready data, usually implemented as a Star schema data model, and all the necessary, verified business logic (calculations that are checked and verified by domain experts), the common scenario is to use a reporting tool of choice, such as Power BI, to consume the data from this gold layer.
In real life, we usually create data marts to support individual departments or business groups (i.e. Financials, Marketing, HR), so we end up having multiple reports – for example, Sales, Forecast, Customer Retention, etc. – each connecting to a particular semantic model. Now, imagine the following scenario: you get the requirement from a user, and let’s pretend that it’s a very important user, like a CFO, for example, who needs to have both sales and forecast data at their disposal. We can either create a dashboard and pin visuals from both reports or design another semantic model, Sales+forecast, to combine information from the existing models. Let’s now discard the “dashboard option” and focus on the option to merge info from multiple semantic models.
At first glance, this might look like a trivial task – grab tables from here and there, and there you go. But, let’s stop for a moment and consider the following:
This approach requires the serious involvement of someone responsible for creating semantic models. This means, there is a dependency on the availability of these individuals
What about the calculations that were already verified and are part of the existing semantic models? If we create a new semantic model by simply combining tables from the existing ones, calculations need to be defined from scratch. That is fine if you have just a few of them…But, what if your semantic model contains hundreds of calculations?
In this case, we want to focus on the following scenario: let’s imagine that you have an existing semantic model with a 1 billion rows fact table on a day level of granularity. The semantic model contains 100+ verified calculations. Now, a small group of users needs to analyze the data on a monthly level (budgeting, forecasting, etc.). To satisfy this requirement, you have a few options at your disposal:
Extend the existing semantic model with the aggregated table on a monthly level—this approach may work very well until the queries hit your aggregated tables. If not, performance will probably suffer. In addition, someone needs to create those aggregated tables, add them to a semantic model, establish relationships, set the proper storage mode for each table, and finally manage aggregations from Power BI
Create a new semantic model with a fact table on a monthly level – the performance of this model should definitely be better than the previous one, but what happens with 100+ calculations? Yes, you’re right, you would have to re-create them in the new semantic model
Augment the existing data model by leveraging the Semantic Link – this would be a mix of the previous two approaches: you’ll create a new semantic model, assuming that we store the SQL query results in the Delta table, but this semantic model may also include 100+ verified calculations available out-of-the-box
%%sql
SELECT
YEAR(`Dates[Date]`) as _Year
, MONTH(`Dates[Date]`) as _Month
, CAST(SUM(`Sales Amt`) AS DECIMAL (18,2)) as SalesAmt
, CAST(SUM(`Sales Qty`) AS DECIMAL (18,2)) as SalesQty
FROM pbi.`S1`.`_Metrics`
GROUP BY YEAR(`Dates[Date]`)
, MONTH(`Dates[Date]`)
When run from a Fabric notebook, this query will change the granularity – we are moving from the individual date to the year/month level – while keeping the existing measures available.
Word of warning: Being able to do something doesn’t necessarily mean that you SHOULD do it. Leveraging Semantic Link for the purpose of creating a new semantic model as a combination of multiple existing semantic models, although it looks very handy, is far from the best practice, and it should definitely not be your default choice. However, it’s good to have the possibility to choose between different options and, based on the specific scenario, decide which one works in the most efficient way in that particular use case.
Conclusion
All of the standard, built-in data science capabilities, such as MLFlow, SynapseML, and AutoML, undoubtedly have their place in regular data science workloads. However, there is one special ingredient for data science in Microsoft Fabric. The Semantic Link feature is that “X factor”, something that gives a whole new dimension to the data science experience and opens an infinite number of use cases. I firmly believe that what was a missing link before, now with Semantic Link becomes the strongest link, as this feature finally enables bridging the gap between data science and Business Intelligence.
Credits:
Michael Kovalsky (Microsoft) – for his tremendous work on the Semantic Link implementation scenarios
Markus Cozowicz (Microsoft) – for introducing me to a Semantic Link feature a year ago
Sandeep Pawar (MVP) – for his guidance through data science experience in Fabric and for writing many, many great blogs about Semantic Link. Check Sandeep’s work here
Ruixin Xu (Microsoft) – for spending her time to provide invaluable feedback on this article





The Importance of Semantic Link – Curated SQL
[…] Nikola Ilic excerpts from a forthcoming book: […]
Muhammad Hasnain
I am getting this error “No module named ‘sempy_labs'” as I already installed the semantic-link
Nikola
Hi Muhammad,
You also need to install semantic link labs:
! pip install semantic-link-labs
Or add them to your environment.
Hope this helps.