
This article is the part of the series related to mastering DP-500/DP-600 certification exam: Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI and Implementing Analytics Solutions Using Microsoft Fabric
Table of contents
How many times have you bragged about the following: oh, no, I need to refresh my fact table, but it takes soooo long…Maybe it was happening because you haven’t used one of the key performance features when it comes to the data refresh process.
Let’s try to briefly explain the concept of the incremental refresh. If you think that incremental refresh is something exclusively related to Power BI, you couldn’t be more wrong! This approach has been here for decades and is implemented in basically every traditional data warehousing solution.
Incremental refresh is the process of loading new or updated data, after the previous data loading cycle!
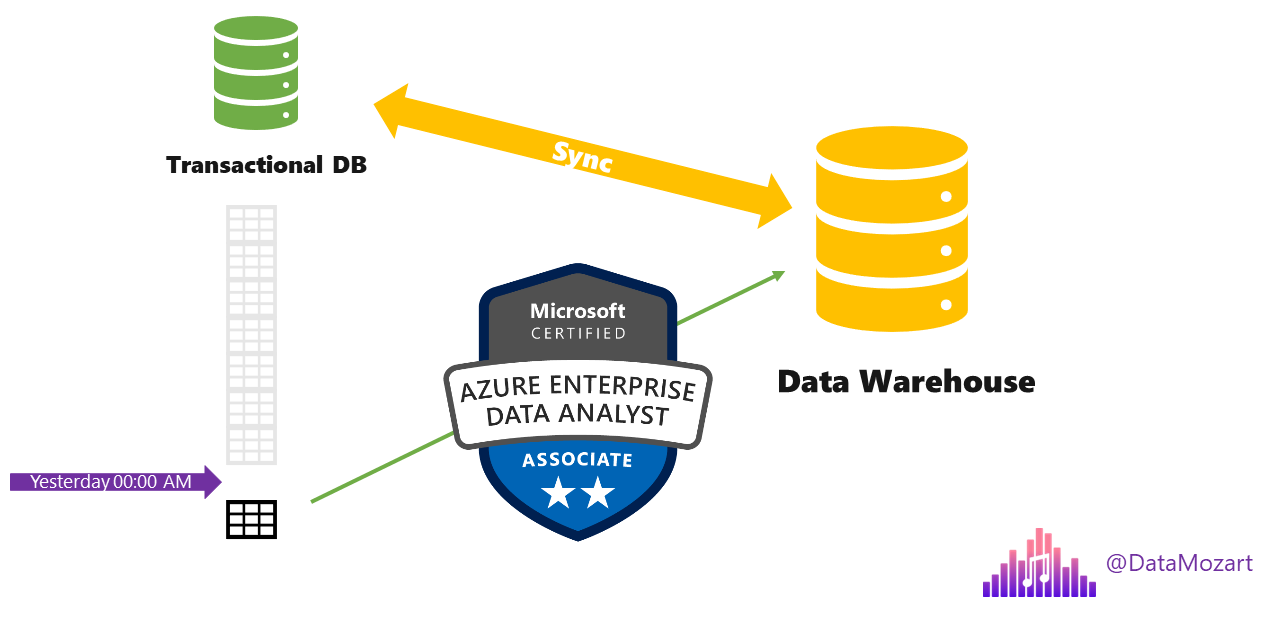
Behind this definition, there are various important aspects to understand. First, why is incremental refresh so important? Well, imagine that you have a huge transactional database, where the main table contains millions of rows. In order to keep your analytic workloads in sync, you need to load the data from that transactional database into the data warehouse. So, imagine what would happen if you load the whole giant table each and every time?! Exactly, it will consume a lot of resources and may also have an impact on the transactional database:
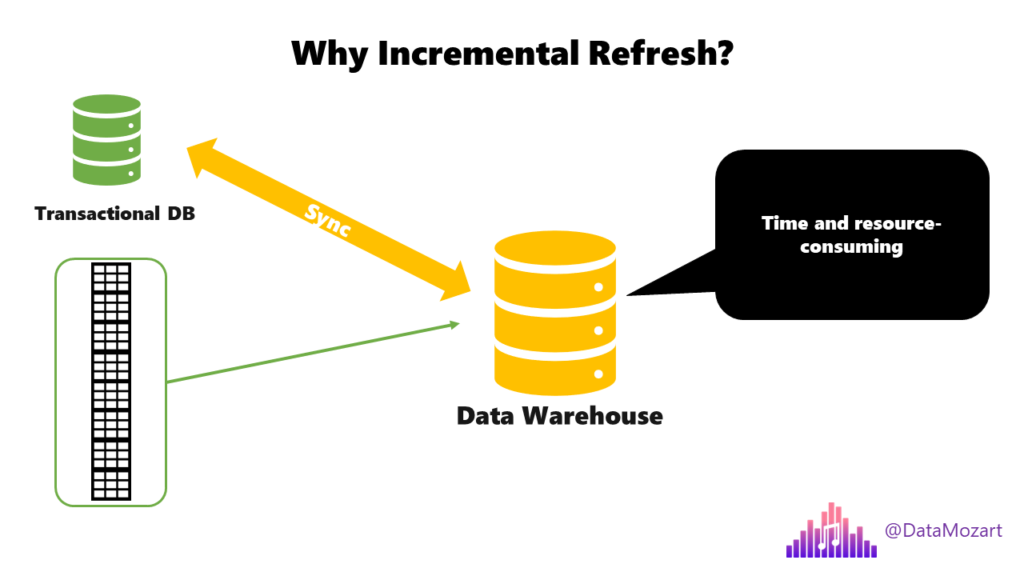
Therefore, you should check and consume only those records that arrived or changed AFTER the last refresh process! This significantly reduces the pressure on the transactional database, as only a small chunk of data needs to be handled.
Let’s say that you synchronized your data yesterday at midnight. Instead of pulling the whole multimillion table again, we will check only the records that were updated or inserted in the meantime, which can be a few thousand rows, and then synchronize only this small portion!
Benefits of Incremental refresh
There are multiple advantages of implementing incremental refresh in your Power BI solution:
- Refreshes are faster – obviously, as you operate with a smaller amount of data, the data loading process will run faster
- Reduced resource consumption – again, handling a smaller chunk of data will help you decrease memory consumption and use other Power BI and data source system resources more efficiently
- Reliable refresh process – if you decide to go “all-in” and against Incremental refresh, it may happen that long-running connections become vulnerable and non-reliable. Incremental refresh eliminates this challenge
- Easy setup – in literally few clicks, you can define incremental refresh policies for your Semantic Model
Incremental refresh in Power BI
Once you publish your data model to Power BI Service, each table contains one single partition. That partition contains all the rows, which for large tables data refresh, as we’ve already explained, may be overwhelming.
When you configure incremental refresh, Power BI will automatically partition your table – one partition will contain data that has to be refreshed frequently, while the other partition will hold rows that are not changing.
In the most simplified way, this is how the workflow should look with the incremental refresh in place:
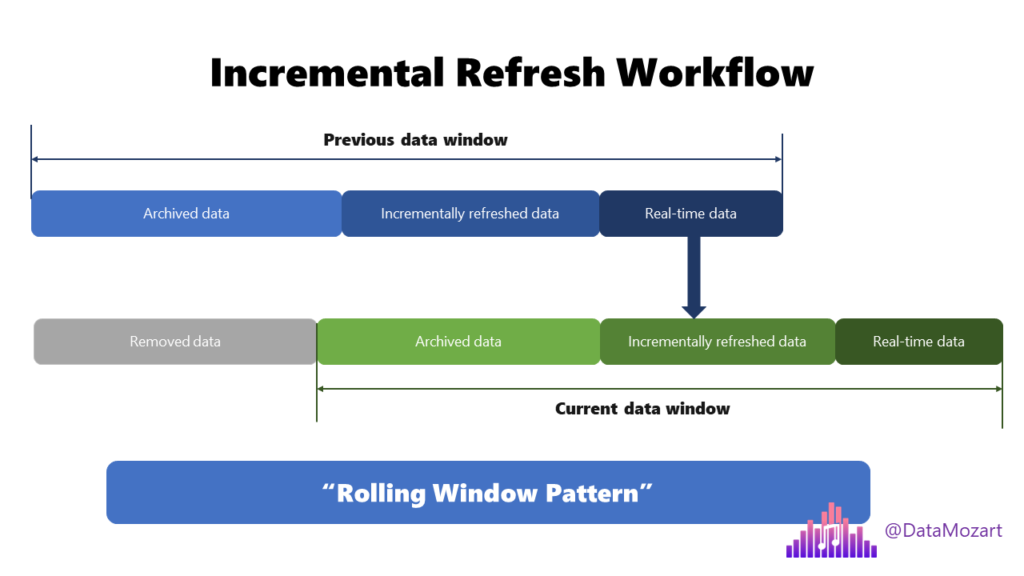
As you may notice comparing the previous and current data window, the window is rolling and data that was considered real-time in the previous window, now becomes part of the incrementally refreshed partition. This is an ongoing process and is known as a “rolling window pattern”.
Prerequisites for Incremental refresh
To be able to implement an incremental refresh feature in your Power BI solution, some prerequisites need to be in place:
- Date column – a table to which you want to apply Incremental refresh, must contain a date column, that can be either date/time or integer data type. This is because you need to set up parameters for separating the data between partitions
- Query folding – now, you’re probably asking yourself: what is query folding? So, let’s first explain this one. I’ve already written about it in more detail in this article, but, in a nutshell, query folding is the ability of Power Query to generate a single SQL query that will be executed on the SQL data source side. Why does query folding matter for the incremental refresh? Well, your date range parameters need to be translated to a WHERE clause in SQL, in order to separate data in relevant partitions. Therefore, without query folding, there is no WHERE clause, no partitioning possible, and consequentially no incremental refresh possible
- Single data source – means, all your partitions must query data from a single source
Wait…There is more!
By leveraging a Hybrid tables feature, you can enhance a data refresh process even more! Essentially, the idea is to set the incremental refresh for the table, but set up the partition with the most recent data in DirectQuery mode, while keeping the older data in the partition that uses Import mode.
This way, you are getting the best of both worlds: blazing-fast performance for analytic queries over older data, and real-time synchronization with the latest data from the original data source! However, at this moment, the Hybrid tables feature is available only with Power BI Premium licenses.
Setting up Incremental refresh in Power BI
The first step in the configuration process is to define parameters and set their default values to be applied when filtering the data that should be loaded into the Power BI Desktop. You should keep this range short and include only the most recent data (3 days in my case), as these values will be anyway overridden once you configure the incremental refresh policy.
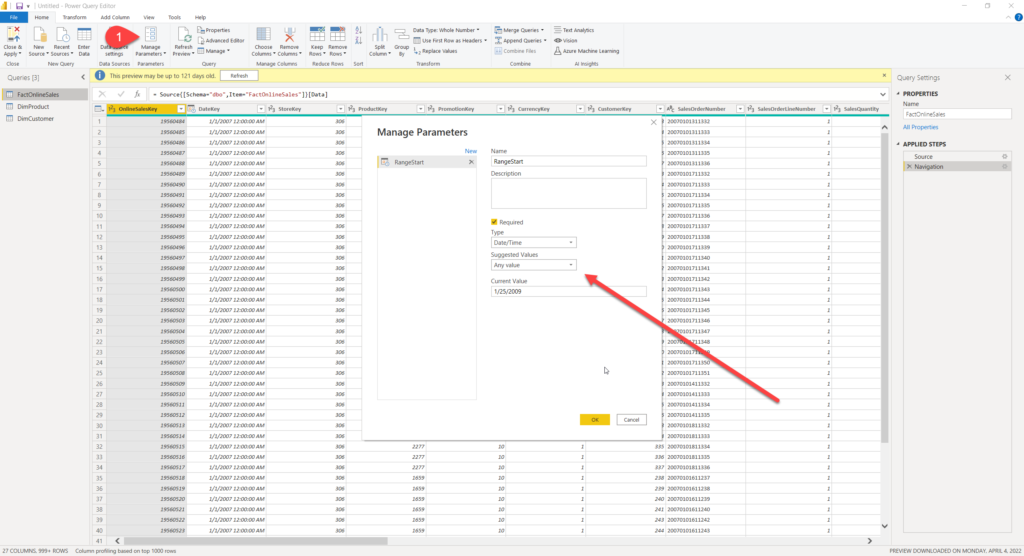
Please keep in mind that you should use predefined RangeStart and RangeEnd names for your parameters. That way, Power BI “knows” that these parameters will be used for setting up the Incremental refresh.
The next step is to filter the data, based on our newly created parameters:
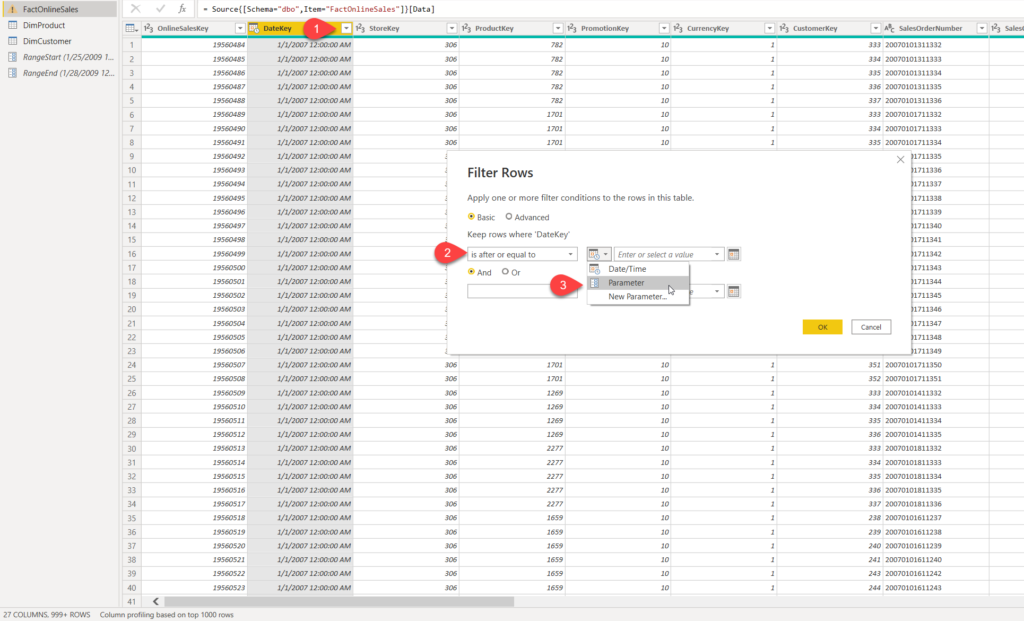
Watch out when setting the filter conditions – you should avoid using equality on both parameters (i.e. is after or equal to/is before or equal to), because that can fetch duplicated data and produce incorrect results in your report!
I can now hit Close&Apply in Power Query Editor and you may notice that Power BI will load only a small portion of data – in my case, instead of the original 12.6 million rows, this time only 36.000 rows will be loaded.
Now comes the crucial part of the workflow – we will define the incremental refresh policy for our giant fact table:

Once the Incremental refresh dialog window pops up, there are various options to choose from:
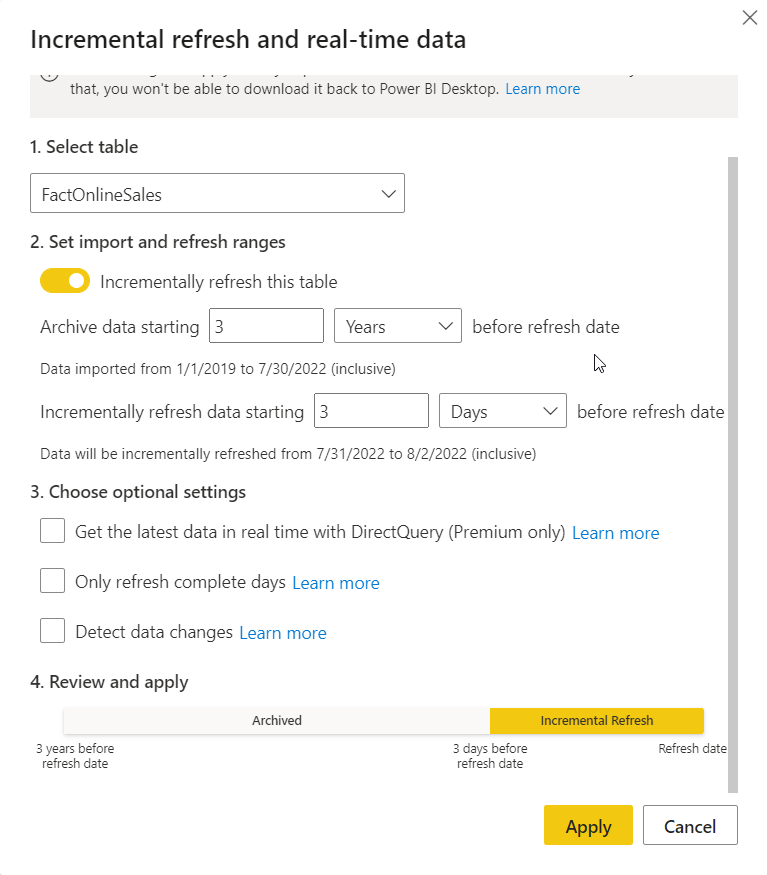
After I toggled on Incrementally refresh this table property, I’ll define the archive period (3 years in my example) and the period for which my incremental refresh policy will be applied (3 days). The cool thing is that you immediately see which dates will be included in which partition!
Under the optional settings, if you tick the box next to Get the latest data in real time with DirectQuery, you can take advantage of the Hybrid tables feature that we’ve already described in one of the previous articles.
Only refresh complete days option comes in very handy if you have your data refresh process scheduled for, let’s say, 3 AM (assuming that at that time there is less pressure on the underlying data source), but you don’t want to import into Power BI only these records that were inserted in the source system between midnight and 3 AM. With this option enabled, only records for completed days will be loaded.
Detect data changes may bring an even greater performance boost to the data refresh process because it enables the processing of only those records that were changed since the previous run. For this option to work, you need to have a specific column in the data source containing the information when the specific record was last time updated (for example, LastUpdated, LoadDate, and so on). This column must be the date/time data type and should not be the same column that you use for partitioning the fact table (in our case, it should not be the DateKey column).
Finally, if you scroll down, you can see your incremental refresh rolling window visualized:

Hit Apply and now I’m ready to publish the report and the Semantic Model. Once the Semantic Model is in the Power BI workspace, you must refresh it. The first refresh will load both historical data for the selected stored period, and the new and updated data defined in the incremental refresh policy.
This first data loading may take a while depending on the amount of data, but all subsequent refreshes should run much faster, as only the data from the period specified in the incremental refresh policy will be loaded.
Conclusion
When you’re dealing with relatively small data models, you may sneak without implementing an Incremental refresh for your data. However, once the data volumes begin to scale, Incremental refresh will quickly become your best friend in optimizing the data refresh process.
And, it’s not only about the time needed for bringing the fresh data into your Power BI Semantic Models, but also the resources needed to reprocess the whole gigantic tables.
Thanks for reading!
Last Updated on December 17, 2023 by Nikola


Rani
Hi Nikola,
Very helpful post as always 🙂
Will be helpful if you could please let me know if incremental refresh can be implemented when data source is AWS RDS for MySQL on import mode ? Also where can we see the partitions created ?
Nikola
Hi Rani,
I don’t have any experience with AWS RDS for MySQL as a data source, so I can’t tell you “yes” or “no”…But, I believe the incremental refresh can be implemented with it as well, because essentially any data source that supports SQL can potentially benefit from IR. You can check partitions created either in Tabular Editor, or in SSMS.
Mayi
Hello Nikola, I have an odata source (from sap) where the values from that odata only gets data from previous day. I added the necessary incremental refresh settings (parameters and such) but when I refresh, it does not add data. Instead, it replaces the data in service, making it not incremental at all. No transformations have been made in the power query.
Is there anything else that I need to look into?
Vivek
Thanks for this wonderful post! I’m enjoying this series a lot. Always look forward to the next… Just like a good Netflix series. 🙂
I have one question… If the source data is in a Azure Data Lake in csv format, is incremental refresh of any particular use given I suppose there is no query folding applicable?
Nikola
Hi Vivek,
Haha, thanks for this Netflix analogy, I love that:)
Regarding your question: you’re right, csv files don’t support query folding and it will always be a full scan.
Cheers,
Nikola
Donald Parish
Got my hopes up for an article on “incremental refresh” of Direct Lake tables in Microsoft Fabric using Dataflow gen2 or Notebooks.
Nikola
There is no incremental refresh available for Direct Lake semantic models. You can only configure incremental data loading into Delta tables (by using Dataflows Gen2, pipelines, or notebooks). Direct Lake behaves more or less as a Direct Query, so it will always pick up the latest data from delta tables.