

The wait is over – Microsoft Fabric is now officially generally available! If you want to learn more about the latest SaaS solution from Microsoft, I get you covered – go and read this article to understand all the details and nuances around Fabric.
I’ve also written an article about different pricing models for Fabric. One of these models, Pay-as-you-go, works in a slightly different way compared to the reserved instance pricing model. In the “pricing” article, I’ve mentioned two key concepts behind Fabric capacity workloads – bursting and smoothing.
Thanks to my fellow MVPs, Tristan Malherbe and Just Blindbaek, as well as Alex Barbeau and Mimoune Djouallah (Alex and Mim are not “officially” MVPs, but they are both super-knowledgeable guys) for demistyfing these concepts
Let’s try to break down these concepts and explain them as simple as possible:
Bursting lets you use more power than you purchased (within the specific timeframe)! Smoothing takes care that this power is “under control” within that same timeframe. Easy, right:)? I know, I know, so let’s break this further down…

Bursting brings the power!
When you purchase, let’s say, F2 Fabric capacity, which provides 2 CUs (this was taken as an example for the sake of simplicity), you get a certain number of seconds you can use these two CUs. Since you get 2 CUs, you can use each of them 24h x 60mins x 60sec = 86.400 sec during a 24h timeframe. Which is 172.800 sec in total (2 CUs x 86.400 sec). Now, let’s say that every morning you perform some heavy workloads on the capacity – what the engine will do – it will automatically increase the power of your setup and “give” you more CUs to complete these workloads (this is called bursting). So, it may happen that instead of 20 minutes, your workload completes in 5 minutes! Then, these 15-minute difference will be smoothed later during the 24-hour timeframe. Since there is no free lunch, if no smoothing can be applied in the specific 24-hour timeframe, you’ll either get throttled or have to pay for using more power (for example, if you pause the capacity right after bursting occurs).
To illustrate: if you took advantage of bursting for 1 hour, and then immediately paused the Fabric capacity, you will still be charged at the time of pause for all “bursted” CU time that was smoothed into the future (but couldn’t be materialized because of pausing the capacity):
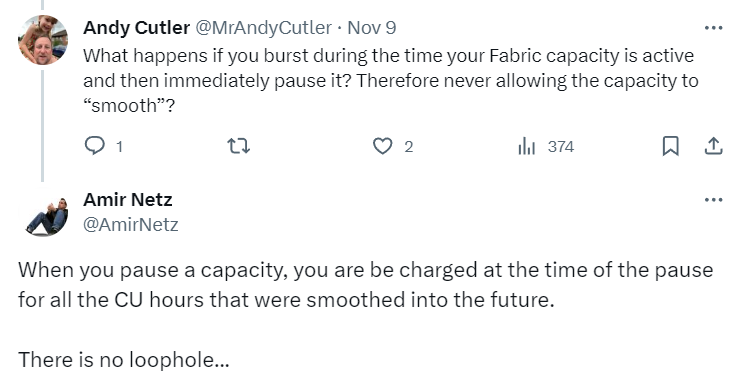
Tristan (t) described his tests in the Twitter thread, so I encourage you to take a look.
Can you jump in and impact the bursting/smoothing behavior? Not at all! That’s the “beauty” of SaaS:) Everything is handled automatically in the background.
The next fair question would be: why do we need bursting? Well, by having the ability to automatically scale out heavy workloads, Fabric essentially prevents throttling and provides a smoother experience in peak periods.

Smoothing keeps the power under control!
Even after smoothing takes place, there may be periods of additional heavy operations – Fabric capacity will then “carry forward” above the limit usage into future periods when the capacity resources are available.
Here, there is a difference in how the capacity handles ad-hoc interactive user queries vs scheduled jobs:
- Ad-hoc interactive queries are typically smoothed in the next 5 minutes, to avoid many short-term spikes
- Scheduled workloads are smoothed in the next 24 hours
Why do we need smoothing? Simply said, by understanding the average workload behavior instead of peak, we can plan capacity size more realistically (thus, saving some money along the way).
If the workload exceeds the limit, there are three possible outcomes, depending on the “future” availability of the capacity:
- Next 10 minutes full – ad-hoc interactive queries will be delayed
- Next 60 minutes full – ad-hoc interactive queries will be rejected
- Next 24 hours full – scheduled workloads will be rejected
The next fair question would be: what are my options in case of the constant capacity overload?
- “M” is for Money – throw more cash and purchase a more powerful capacity
- “P” is for Patience – in other words, wait until the overload is over
- “P” is also for Performance (tuning) – align with users whose workloads consume most of the resources and check possible improvement options
Bursting and Smoothing are like Yin and Yang!

In my opinion, finding that “tipping point” between bursting and smoothing, and the right balance for Fabric workloads, will be one of the biggest challenges and this is the area where potential tuning may bring some significant cost-performance optimization
To wrap up the “Yin-Yang” story about bursting and smoothing – these concepts are more relevant to the Pay-as-you-go pricing model (because of potential additional costs). When you choose the reserved instance model, costs are fixed and the worst thing that may happen is throttling, but there will be no additional costs attached to your monthly bill.
Thanks for reading!
Last Updated on November 16, 2023 by Nikola


