

In the ocean of announcements from the recent FabCon Europe in Vienna, one that may have gone under the radar was about the enhancements in performance and cost optimization for Dataflows Gen2.
Before we delve into explaining how these enhancements impact your current Dataflows setup, let’s take a step back and provide a brief overview of Dataflows. For those of you who are new to Microsoft Fabric – a Dataflow Gen2 is the no-code/low-code Fabric item used to extract, transform, and load the data (ETL).
A Dataflow Gen2 provides numerous benefits:
- Leverage 100+ built-in connectors to extract the data from a myriad of data sources
- Leverage a familiar GUI from Power Query to apply dozens of transformations to the data without writing a single line of code – a dream come true for many citizen developers
- Store the output of data transformation as a delta table in OneLake, so that the transformed data can be used downstream by various Fabric engines (Spark, T-SQL, Power BI…)
However, simplicity usually comes with a cost. In the case of Dataflows, the cost was significantly higher CU consumption compared to code-first solutions, such as Fabric notebooks and/or T-SQL scripts. This was already well-explained and examined in two great blog posts written by my fellow MVPs, Gilbert Quevauvilliers (Fourmoo): Comparing Dataflow Gen2 vs Notebook on Costs and usability, and Stepan Resl: Copy Activity, Dataflows Gen2, and Notebooks vs. SharePoint Lists, so I won’t waste time discussing the past. Instead, let’s focus on what the present (and future) brings for Dataflows!
Changes to the pricing model
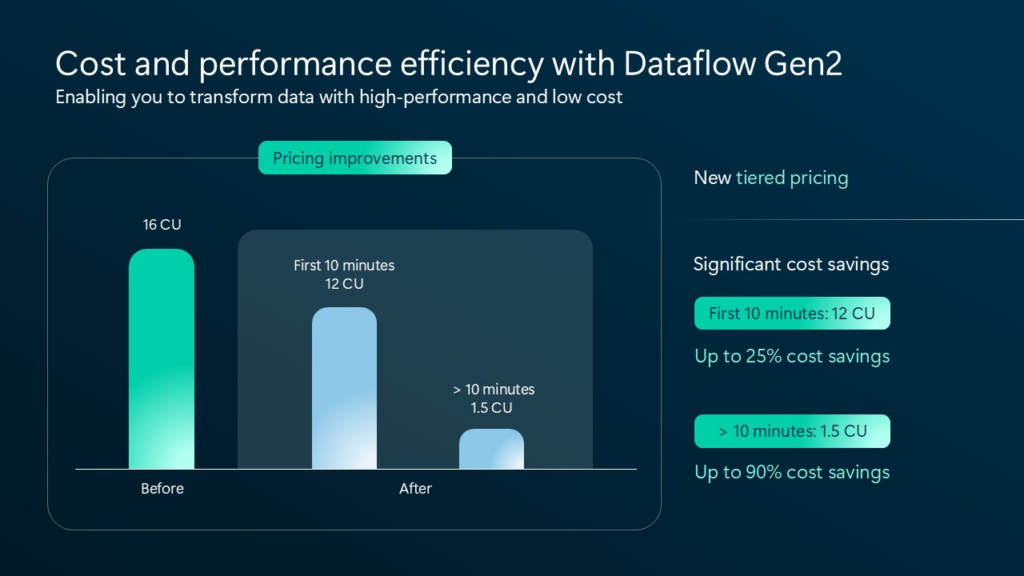
Let’s briefly examine what’s displayed in the illustration above. Previously, every second of the Dataflow Gen2 run was billed at 16 CU (CU stands for Capacity Unit, representing a bundled set of resources – CPU, memory, and I/O – used in synergy to perform a specific operation). Depending on the Fabric capacity size, you get a certain number of capacity units – F2 provides 2 CUs, F4 provides 4 CUs, and so on.
Going back to our Dataflows scenario, let’s break this down by using a real-life example. Say you have a Dataflow that runs for 20 minutes (1200 seconds)…
- Previously, this Dataflow run would have cost you 19.200 CUs: 1200 seconds * 16 CUs
- Now, this Dataflow run will cost you 8.100 CUs: 600 seconds (first 10 minutes) * 12 CUs + 600 seconds (after first 10 minutes) * 1.5 CUs
The longer your Dataflow needs to execute, the bigger the savings in CUs you potentially make.
This is amazing on its own, but there is still more to that. I mean, it’s nice to be charged less for the same amount of work, but what if we could make these 1200 seconds, let’s say, 800 seconds? So, it wouldn’t save us just CUs, but also reduce the time-to-analysis, since the data would have been processed faster. And, that’s exactly what the next two enhancements are all about…
Modern Evaluator
The new preview feature, named Modern Evaluator, enables using the new query execution engine (running on .NET core version 8) for running Dataflows. As per the official Microsoft docs, Dataflows running the modern evaluator can provide the following benefits:
- Faster Dataflow execution
- More efficient processing
- Scalability and reliability
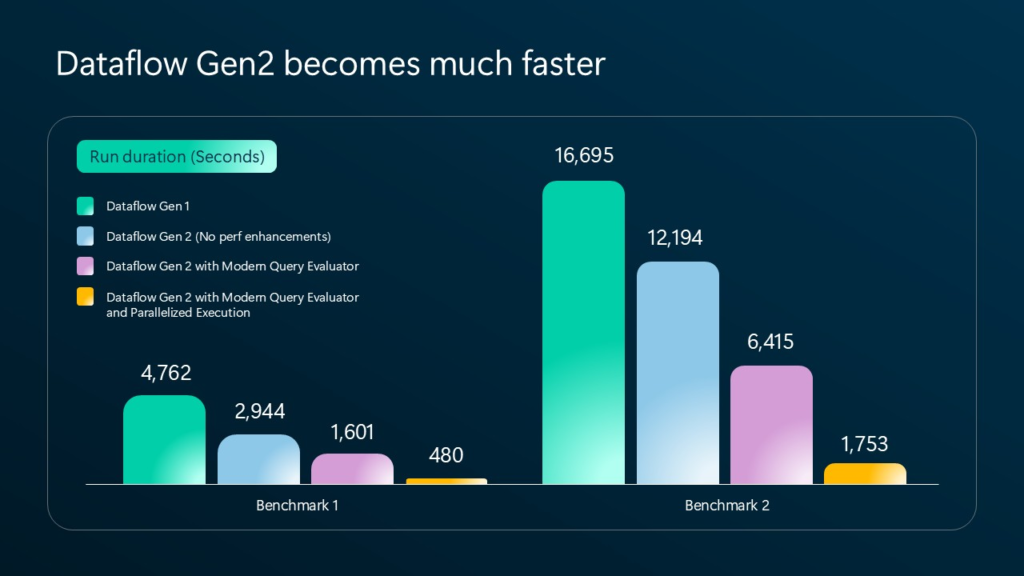
The illustration above shows the performance differences between various Dataflow “flavors”. Don’t worry, we will challenge these numbers soon in a demo, and I’ll also show you how to enable these latest enhancements in your Fabric workloads.
Partitioned Compute
Previously, a Dataflow logic was executed in sequence. Hence, depending on the logic complexity, it could take a while for certain operations to complete, so that other operations in the Dataflow had to wait in the queue. With the Partitioned Compute feature, Dataflow can now execute parts of the transformation logic in parallel, thus reducing the overall time to complete.
At this moment, there are certain limitations on when the partitioned compute will kick in. Namely, only ADLS Gen2, Fabric Lakehouse, Folder, and Azure Blob Storage connectors can leverage this new feature. Again, we’ll explore how it works later in this article.
3, 2, 1…Action!
Ok, it’s time to challenge the numbers provided by Microsoft and check if (and to what degree) there is a performance gain between various Dataflows types.
Here is our scenario: I’ve generated 50 CSV files that contain dummy data about orders. Each file contains approximately 575.000 records, so there are ca. 29 million records in total (approximately 2.5 GBs of data). All the files are already stored in the SharePoint folder, allowing for a fair comparison, as Dataflow Gen1 doesn’t support OneLake lakehouse as a data source.
I plan to run two series of tests: first, include the Dataflow Gen1 in the comparison. In this scenario, I won’t be writing the data into OneLake using Dataflows Gen2 (yeah, I know, it defeats the purpose of the Dataflow Gen2), as I want to compare “apples to apples” and exclude the time needed for writing data into OneLake. I will test the following four scenarios, in which I perform some basic operations to combine and load the data, applying some basic transformations (renaming columns, etc.):
- Use Dataflow Gen1 (the old Power BI dataflow)
- Use Dataflow Gen2 without any additional optimization enhancements
- Use Dataflow Gen2 with only the Modern evaluator enabled
- Use Dataflow Gen2 with both the Modern evaluator and Partitioned compute enabled
In the second series, I’ll compare three flavors of Dataflow Gen2 only (points 2-4 from the list above), with writing the data to a lakehouse enabled.
Let’s get started!
Dataflow Gen1
The entire transformation process in the old Dataflow Gen1 is fairly basic – I simply combined all 50 files into a single query, split columns by delimiter, and renamed columns. So, nothing really advanced happens here:
The same set of operations/transformations has been applied to all three Dataflows Gen2.
Please keep in mind that with Dataflow Gen1 it’s not possible to output the data as a Delta table in OneLake. All transformations are persisted within the Dataflow itself, so when you need this data, for example, in the semantic model, you need to take into account the time and resources needed to load/refresh the data in the import mode semantic model. But, more on that later.
Dataflow Gen2 without enhancements
Let’s now do the same thing, but this time using the new Dataflow Gen2. In this first scenario, I haven’t applied any of these new performance optimization features.
Dataflow Gen2 with Modern Evaluator
Ok, the moment of truth – let’s now enable the Modern Evaluator for Dataflow Gen2. I’ll go to the Options, and then under the Scale tab, check the Allow use of the modern query evaluation engine box:
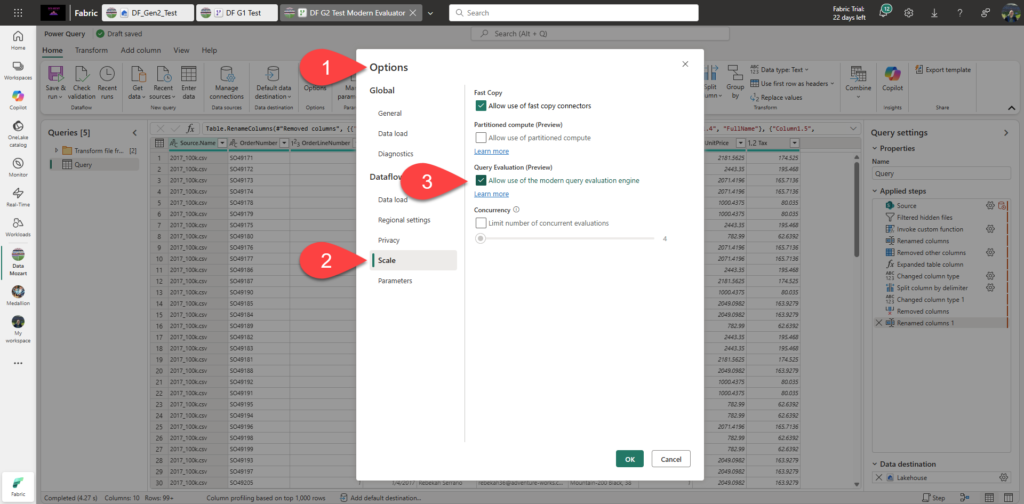
Everything else stays exactly the same as in the previous case.
Dataflow Gen2 with Modern Evaluator and Partitioned Compute
In the final example, I’ll enable both new optimization features in the Options of the Dataflow Gen2:
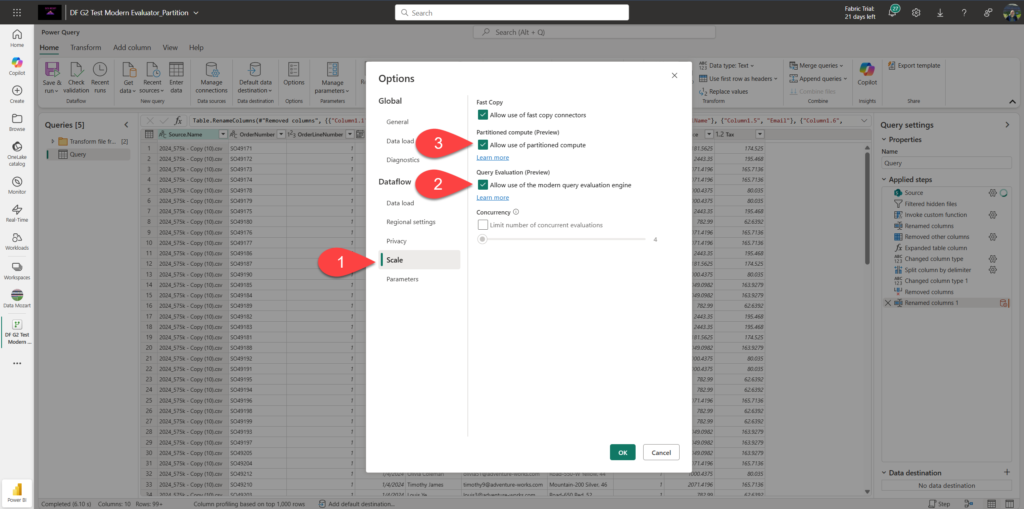
Now, let’s proceed to the testing and analyzing results. I will execute all four dataflows in sequence from the Fabric pipeline, so we can be sure that each of them runs in isolation from the others.
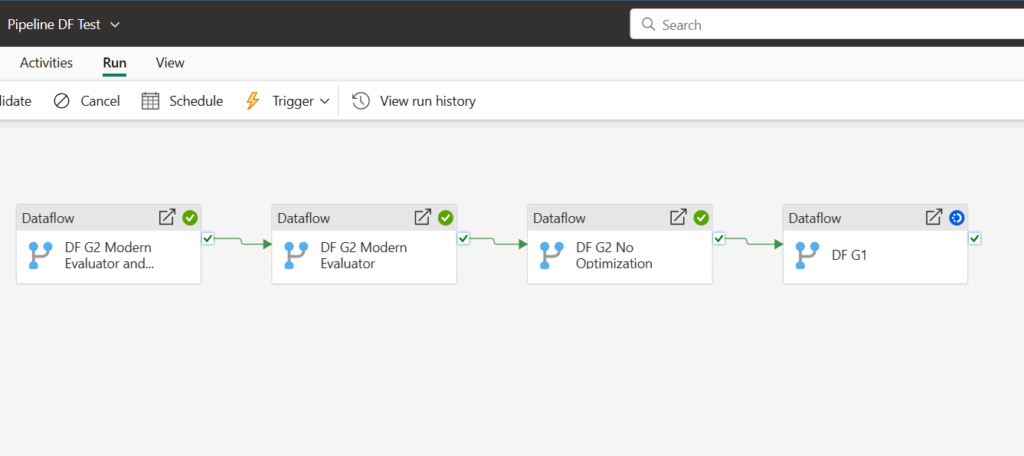
And, here are the results:
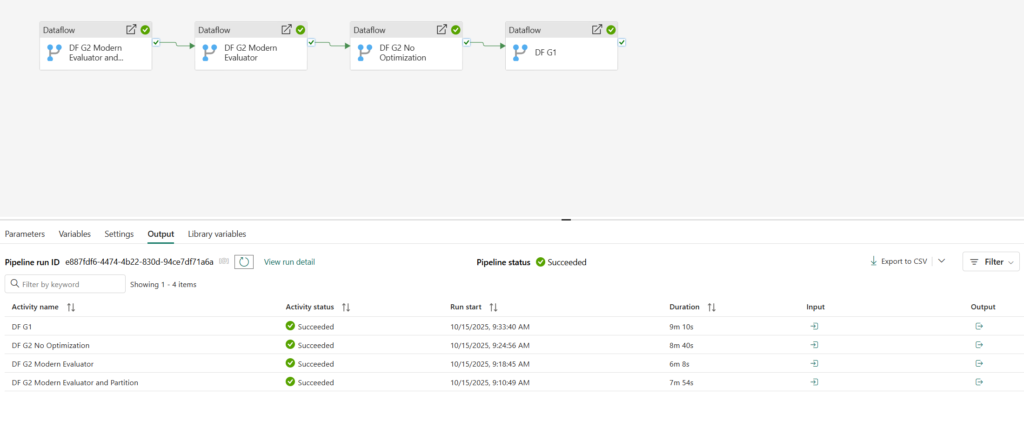
Partitioning obviously didn’t count much in this particular scenario, and I will investigate how partitioning works in more detail in one of the following articles, with different scenarios in place. Dataflow Gen2 with Modern Evaluator enabled, outperformed all the others by far, achieving 30% savings compared to the old Dataflow Gen1 and ca. 20% time savings compared to the regular Dataflow Gen2 without any optimizations! Don’t forget, these savings also reflect in the CU savings, so the final CU estimated cost for each of the used solutions is the following;
- Dataflow Gen1: 550 seconds * 12 CUs = 6.600 CUs
- Dataflow Gen2 with no optimization: 520 seconds * 12 CUs = 6.240 CUs
- Dataflow Gen2 with Modern Evaluator: 368 seconds * 12 CUs = 4.416 CUs
- Dataflow Gen2 with Modern Evaluator and Partitioning: 474 seconds * 12 CUs = 5.688 CUs
However, I wanted to double-check and confirm that my calculation is accurate. Hence, I opened the Capacity Metrics App and took a look at the metrics captured by the App:
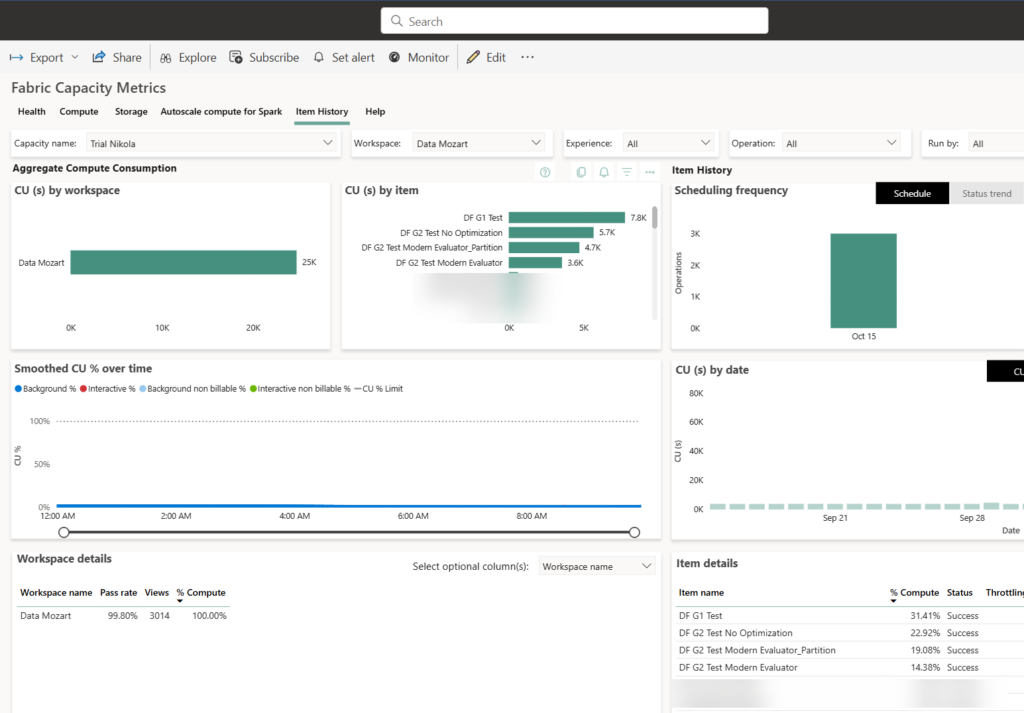
Although the overall result accurately reflects the numbers displayed in the pipeline execution log, the exact number of used CUs in the App is different:
- Dataflow Gen1: 7.788 CUs
- Dataflow Gen2 with no optimization: 5.684 CUs
- Dataflow Gen2 with Modern Evaluator: 3.565 CUs
- Dataflow Gen2 with Modern Evaluator and Partitioning: 4.732 CUs
So, according to the Capacity Metrics App, a Dataflow Gen2 with Modern Evaluator enabled consumed less than 50% of the capacity compared to the Dataflow Gen1 in this particular scenario! I plan to create more test use cases in the following days/weeks and provide a more comprehensive series of tests and comparisons, which will also include a time to write the data into OneLake (using Dataflows Gen2) versus the time needed to refresh the import mode semantic model that is using the old Dataflow Gen1.
Conclusion
When compared to other (code-first) options, Dataflows were (rightly?) considered “the slowest and least performant option” for ingesting data into Power BI/Microsoft Fabric. However, things are changing rapidly in the Fabric world, and I love how the Fabric Data Integration team makes constant improvements to the product. Honestly, I’m curious to see how Dataflows Gen2’s performance and cost develop over time, so that we can consider leveraging Dataflows not only for low-code/no-code data ingestion and data transformation requirements, but also as a viable alternative to code-first solutions from the cost/performance point of view.
Thanks for reading!
Update: Thanks to my friend Sandeep Pawar from Fabric CAT team, I’ve been pointed to the great video by Pat Mahoney (Sandeep’s colleague from Microsoft), that provides more details about configuring the partitioning in Dataflows Gen2.
Last Updated on October 16, 2025 by Nikola



Mateus
Nice post!
I’ll be testing all my DF’s perfomance in the next week.