If you’ve spent any time in the data engineering world, you’ve likely encountered this debate at least once. Maybe twice. Ok, probably a dozen times😉 “Should we process our data in batches or in real-time?” And if you’re anything like me, you’ve noticed that the answer usually starts with: “Well, it depends…”
Which is true. It does depend. But “it depends” is only useful if you actually know what it depends on. And that’s the gap I want to fill with this article. Not another theoretical comparison of batch vs. stream processing (I hope you already know the basics). Instead, I want to give you a practical framework for deciding which approach makes sense for your specific scenario, and then show you how both paths look when implemented in Microsoft Fabric.
It’s not batch vs. stream: it’s “when does the answer matter?”
Let me skip dry definitions and jump straight to what actually separates these two approaches: the value of freshness.
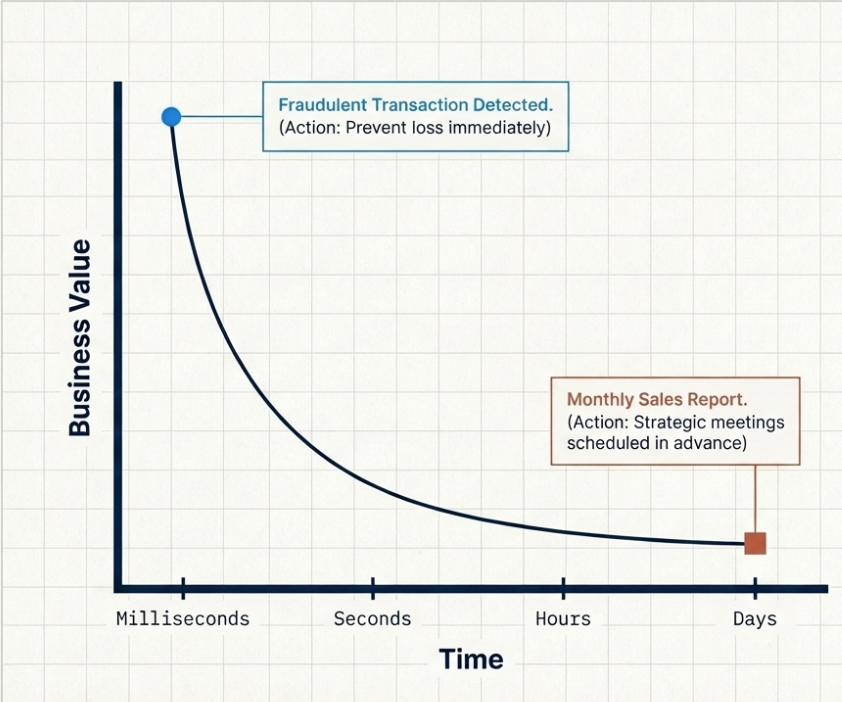
Every piece of data has a shelf life. Not in the sense that it expires and becomes useless, but in the sense that its business value changes over time. A fraudulent credit card transaction detected in 200 milliseconds? Priceless – you just prevented a loss. The same fraud detected 6 hours later in a nightly batch job? Useful for reporting, but the money is already gone.
On the flip side, a monthly sales report generated from yesterday’s data versus data that’s 3 minutes old? In most organizations, nobody can tell the difference (and probably nobody cares). The business decisions based on that report happen in meetings scheduled days in advance, not in milliseconds after the data arrives.
So, the first question isn’t “batch or stream?” The first question is: how quickly does someone (or something) need to act on this data for it to matter?
If the answer is “seconds or less”, you’re in streaming territory. If the answer is “hours or days”, batch is likely your friend. And if the answer is “somewhere in between”… Congratulations, you’re in the most interesting (and most common) gray area, which we’ll explore shortly.
The trade-offs
You know what the most uncomfortable truth about streaming is? It sounds amazing on paper. Who wouldn’t want real-time data? It’s like asking “would you prefer your coffee now or in 6 hours?” But the reality is more nuanced than that. Let’s walk through the trade-offs that actually matter when you’re making this decision.
Cost
I hear you, I hear you: “Nikola, how much more expensive is streaming?” Unfortunately, there’s no single number I can give you, but the pattern is consistent: streaming infrastructure is almost always more expensive than batch processing for the same volume of data. Why? Because streaming requires resources to be always on, listening, processing, and writing continuously. Batch processing, on the other hand, spins up, does its work, and shuts down. You pay for the compute only when the job runs.
Think of it like a restaurant kitchen. A batch kitchen opens at specific hours – the staff arrives, preps, cooks, cleans up, and goes home. A streaming kitchen is open 24/7 with staff always standing by, ready to cook the moment an order arrives. Even during the quiet hours at 3 AM when nobody’s ordering, someone is still there, waiting. That waiting costs money.
Does this mean streaming is always more expensive? Not necessarily. If your data arrives continuously and you need to process it continuously anyway, the cost difference narrows. But if your data arrives in predictable bursts (daily file drops, hourly API calls), batch processing lets you align your compute spend with those bursts.
Complexity
Batch processing is conceptually simpler. You have a defined input, a defined transformation, and a defined output. If something fails, you re-run the job. The data isn’t going anywhere, it’s sitting in a file or a table, patiently waiting.
Streaming? Things get trickier. You’re dealing with data that arrives continuously, potentially out of order, potentially with duplicates, and potentially with gaps. What happens when a sensor goes offline for 5 minutes and then dumps all its buffered readings at once? What happens when two events arrive in the wrong order? What happens when the processing engine crashes mid-stream? Do you replay from the beginning? From a checkpoint? How do you ensure exactly-once processing?
These are solvable problems, and modern streaming platforms handle most of them well. But these are additional problems that simply don’t exist in batch processing. Complexity isn’t a reason to avoid streaming, it’s simply a reason to make sure you actually need streaming before you commit to it.
Correctness
Batch processing has a natural advantage in correctness, because it operates on complete datasets. When your batch job runs at 2 AM, it has access to all the data from the previous day. Every late-arriving record, every correction, every update, it’s all there. The job can compute aggregates, joins, and transformations against the full picture.
Streaming operates on incomplete data by definition. You’re processing records as they arrive, which means your results are always provisional. That daily revenue number you computed at 11:59 PM? A few late-arriving transactions might change it by the time the clock strikes midnight. Windowing strategies and watermarks help manage this, but they add yet another layer of decision-making.
Again, this isn’t a reason to avoid streaming. It’s a reason to understand that streaming results and batch results might differ, and your architecture needs to account for that.
Latency vs. Throughput
Batch processing optimizes for throughput. This means processing the maximum amount of data in the minimum amount of time. Streaming optimizes for latency, minimizing the time between when an event occurs and when the result is available.
These two goals are often in conflict. A batch job that processes 100 million records in 15 minutes is extremely efficient, that’s roughly 111,000 records per second. A streaming pipeline processing the same data one record at a time as it arrives might handle each record in 50 milliseconds, but the overhead per record is significantly higher. You’re trading throughput for responsiveness.
The question is: does your use case value responsiveness over efficiency, or the other way around?
So, when should I use what?
Let’s examine some concrete scenarios and the reasoning behind each choice. Not just “use streaming for X” – but why.
Batch is your best bet when…
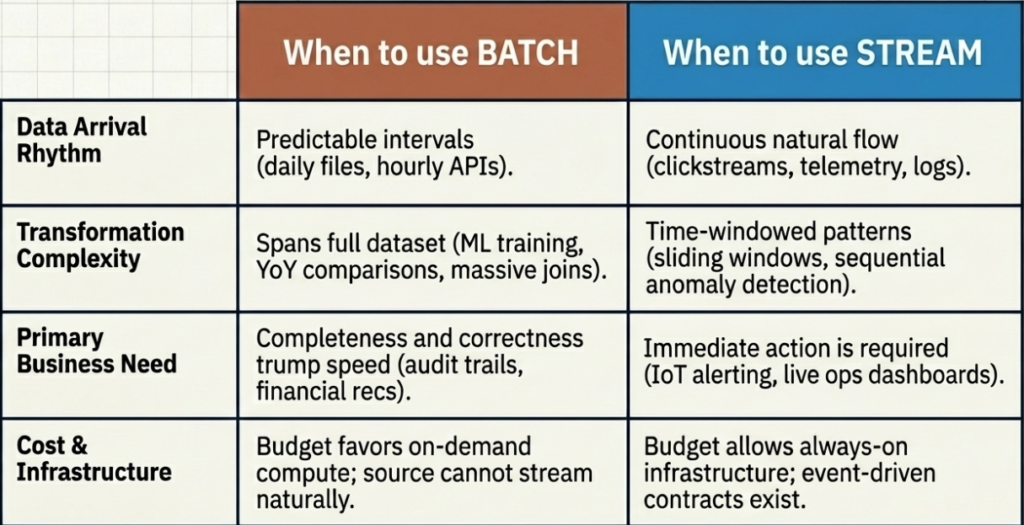
- Your data arrives in predictable intervals. Daily file drops from SFTP servers, hourly API exports, weekly CSV uploads from vendors. The data isn’t time-sensitive, and the source doesn’t support continuous streaming anyway. Forcing a streaming architecture onto data that arrives once a day is like hiring a 24/7 courier service to deliver mail that only comes on Mondays.
- You need complex transformations that span the full dataset. Think about training machine learning models, computing year-over-year comparisons, running large-scale joins between fact tables and slowly changing dimensions. These operations need the full picture, since they can’t be meaningfully decomposed into record-by-record streaming logic.
- Cost optimization is a priority. If your budget is tight and your freshness requirements are not strict (hours, not seconds), batch processing lets you run intensive compute on-demand and shut it down when it’s done. You’re paying for what you use, not for what you might use.
- Data correctness trumps speed. Financial reconciliation, regulatory reporting, audit trails… These are scenarios where being right matters more than being fast. Batch gives you the luxury of processing against complete datasets and rerunning jobs if something goes wrong.
Streaming is the way to go when…
- Someone (or something) needs to act on the data immediately. Fraud detection, anomaly monitoring, IoT alerting, live dashboards for operations teams… The value of the data decays rapidly with time. If the business response to stale data is “well, that’s useless now,” you need streaming.
- The data is naturally continuous. Clickstreams, sensor telemetry, application logs, and social media feeds are not data sources that “batch” naturally. They produce events continuously, and processing them in batches means artificially holding data that’s already available. Why wait?
- You’re building event-driven architectures. Microservices communicating through event buses, order processing systems, real-time personalization engines – the architecture itself is inherently streaming. Introducing batch processing would break the event-driven contract.
- You need to detect patterns over time windows. “Alert me if the CPU usage exceeds 90% for more than 5 consecutive minutes.” “Flag any user who makes more than 10 failed login attempts in a 2-minute window.” These are naturally streaming problems, and they require continuously evaluating conditions against a sliding window of events.
And what about the gray area?
Great! Now you know when to use what. But, guess what? Most organizations don’t fall neatly into one camp. You’ll have use cases that need streaming sitting right next to use cases that are perfectly served by batch. And that’s fine, it’s not an either/or decision at the organization level. It’s a per-use-case decision.
In fact, many mature data architectures implement both. The pattern is sometimes called the Lambda architecture (batch and streaming running in parallel, producing results that get merged) or the Kappa architecture (everything as a stream, with batch being just a special case of a bounded stream). These architectures have their own trade-offs, but the key takeaway is: you don’t have to choose one paradigm for your entire data platform. I might cover Lambda and Kappa architectural patterns in one of the future articles, but they are out of the scope of this one.
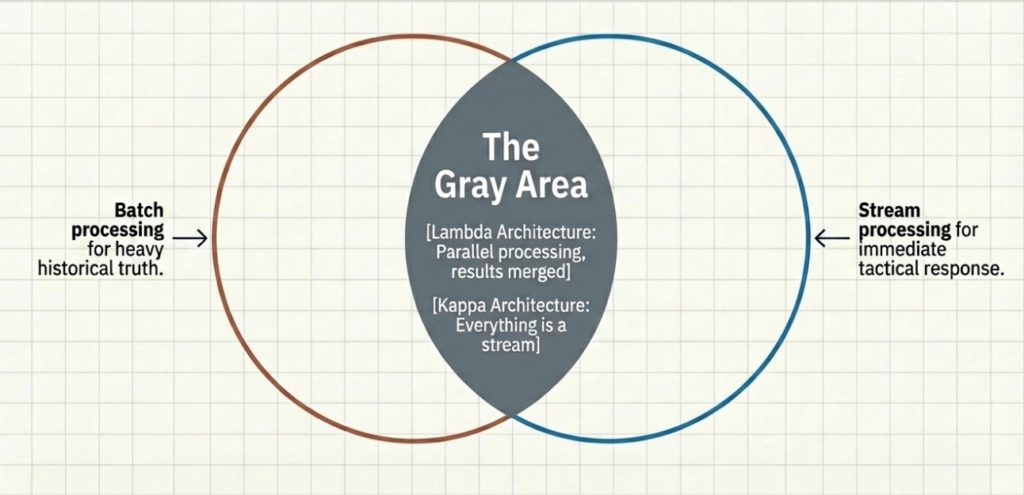
The more practical question is: does your platform support both paths without requiring you to build and maintain two entirely separate stacks? And this is where things get interesting with Microsoft Fabric…
How does this play out in Microsoft Fabric?
One of the things I genuinely appreciate about Microsoft Fabric is that it doesn’t force you into a single processing paradigm. Both batch and stream processing are first-class citizens in the platform, and, what’s even more important, they share the same storage layer (OneLake) and the same consumption model (Capacity Units). This means you’re not maintaining two disconnected worlds.
Let me walk you through how each approach is implemented.
Batch processing in Fabric
For batch workloads, Fabric gives you multiple options depending on your skill set and requirements:
- Data pipelines are the orchestration backbone. If you’re coming from something like Azure Data Factory, this will feel familiar. You can schedule pipelines to run at specific times or trigger them based on events. Pipelines coordinate the flow of data between sources and destinations, with activities like Copy Data, Dataflows, and notebook execution.
- Fabric notebooks are where the heavy lifting happens. You can write PySpark, Spark SQL, Python, or Scala code to perform complex transformations on large datasets. Notebooks are ideal for those “complex transformations spanning the full dataset” scenarios we discussed earlier, such as large joins, aggregations, and ML feature engineering. They spin up, process, and release compute resources when done.
- Dataflows Gen2 offer a low-code/no-code alternative using the familiar Power Query interface. Recent performance improvements (like the Modern Evaluator and Partitioned Compute) have made them a much more competitive option from a cost/performance standpoint. If your batch transformations are relatively straightforward, Dataflows can save you the overhead of writing and maintaining Spark code.
- Fabric Data Warehouse provides a T-SQL-based experience for those who prefer the relational approach. You can run scheduled stored procedures, create views for abstraction layers, and leverage the SQL analytics endpoint for ad-hoc queries.
All of these write their output as Delta tables in OneLake, meaning the results are immediately available to any Fabric engine downstream, whether that’s a Power BI semantic model, another notebook, or a SQL query.
Stream processing in Fabric
For real-time workloads, Fabric’s Real-Time Intelligence is where the action happens. If you want to understand the basics of Real-Time Intelligence in Microsoft Fabric, I have you covered in this article.
- Eventstreams are the ingestion layer for streaming data. You can connect to sources like Azure Event Hubs, Azure IoT Hub, Kafka, custom applications, and even database change data capture (CDC) streams. Eventstreams handle the continuous flow of events and route them to various destinations within Fabric.
- Eventhouses (backed by KQL databases) are the storage and compute engine for real-time data. Data lands in KQL tables and is immediately queryable using the Kusto Query Language. If you’ve read my previous article on update policies, you already know how powerful these can be for transforming data at the point of ingestion – no separate processing layer needed.
- Real-Time Dashboards let you visualize streaming data with auto-refresh capabilities. This way, your operations team gets a live view of what’s happening right now, not what happened yesterday.
- Activator lets you define conditions and trigger actions based on real-time data. “If the temperature exceeds 80°C, send a Teams notification.” “If the order count drops below the threshold, trigger an alert.” It’s the “act on the data immediately” capability we talked about earlier.
The key thing to keep in mind here: Real-Time Intelligence data also lives in OneLake. This means your streaming data and your batch data coexist in the same storage layer. A Spark notebook can read data from a KQL database. A Power BI report can combine batch-processed warehouse tables with real-time Eventhouse data. The boundaries between batch and stream start to blur, and that’s exactly the point I’m trying to emphasize here.
The best of both worlds
Now, let’s examine a concrete example of how batch and streaming can work together in Fabric.
Imagine a retail company monitoring its e-commerce platform. On the streaming side, clickstream data flows through Eventstreams into an Eventhouse, where update policies parse and route the events in real-time. Operations dashboards show live metrics: active users, cart abandonment rate, error rates. Activator triggers alerts when the checkout failure rate spikes above 2%.
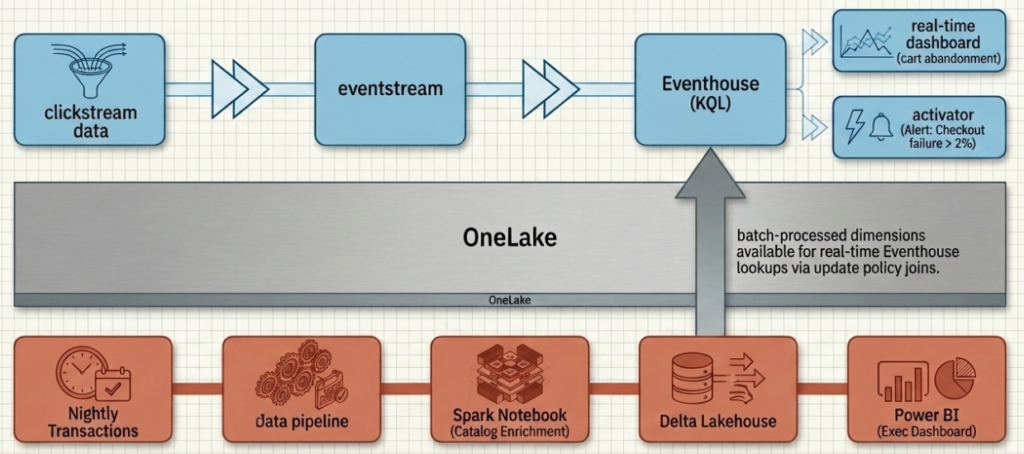
On the batch side, a nightly pipeline pulls the day’s transaction data, enriches it with product catalog information and customer segments using a Spark notebook, and writes the results to a Lakehouse. A Power BI semantic model built on top of these Delta tables powers the executive dashboard that gets reviewed in the Monday morning meeting.
Both paths feed from and into OneLake. The streaming data is available for batch enrichment. The batch-processed dimensions are available for real-time lookups (remember those update policy joins we covered in the previous article?). Two processing paradigms, one unified platform.
A practical decision framework
To wrap things up, here’s a simple set of questions you can ask yourself for each use case. Think of it as your “streaming vs. batch vs. both” decision tree:
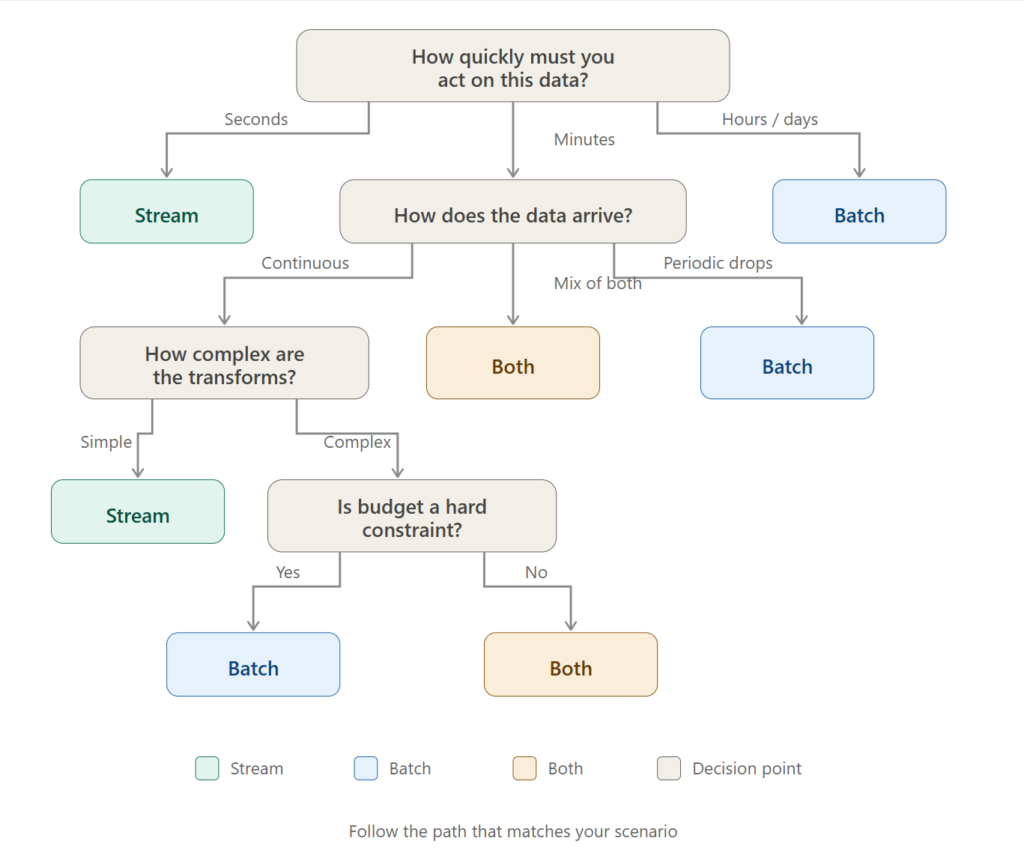
- How quickly does someone need to act on this data? If seconds -> stream. If hours/days -> batch. If “it depends on the scenario” -> read on😊
- How does the data arrive? Continuous events -> streaming is natural. Periodic file drops -> batch is natural. Don’t fight the data’s natural rhythm.
- How complex are the transformations? Record-by-record parsing and filtering -> either works. Large joins, ML training, full-dataset aggregations -> batch has an edge.
- What’s your budget tolerance? Always-on compute for streaming vs. on-demand compute for batch. Calculate both and compare.
- How important is data completeness? If you need the full picture before making decisions -> batch. If provisional results are acceptable -> streaming works.
- Does your platform support both? If yes (and Fabric does), use the right tool for each use case rather than forcing everything through one paradigm.
The best data architectures aren’t the ones that are purely batch or purely streaming. They’re the ones that use each approach where it makes the most sense, and have a platform underneath that makes both paths feel natural.
Thanks for reading!
Note: Visuals in this article have been created using Claude and NotebookLM.
Last Updated on March 26, 2026 by Nikola