

In my recent blog post, I was investigating “pros” and “cons” between using DATETIME and DATETIME2 data types. This investigation appeared to be eye-opening for me, because, while reading documentation about those data types and potential drawbacks when using DATETIME2, I’ve discovered a whole new set of stuff I need to take care of!
What is Implicit Conversion?
In most simple words, Implicit conversion occurs when SQL Server needs to automatically convert some portion of data from one data type to another.
In some cases, when you are performing JOINs, or filtering results using WHERE clause, you are comparing “apples” and “oranges” – therefore, SQL Server needs to convert “apples” to “oranges”, or vice versa.
Why is Implicit Conversion bad?
In order to resolve inconsistencies between data types, SQL Server must put additional effort and consume more resources. Thus, performance will suffer, leading to inefficient usage of indexes and extensive usage of CPU.
But, enough theory, let’s check how implicit conversion kills performance in reality.
Real use case
I have a table that contains data about chats initiated by customers. This table has around 8.6 million rows. One of the columns is “SourceID”, which is chat ID from the source system. In my table, this column is VARCHAR(20) type, despite all values contain only numbers.
I have a unique non-clustered index on the SourceID column, and index on the DatetmStartUTC column (this index includes all other foreign key columns), so let’s run few queries to check what’s happening in the background.
I’ve also turned on statistics for IO and time, to be able to compare results. Finally, I’ve turned on the Actual Execution Plan to get more insight into every specific step in query execution.
Query #1 AKA “Killer”
When someone performs simple data profiling within this table and see only numbers in SourceID column, it is completely expected to write a query like this:
DECLARE @sourceIDi INT = 8000000 SELECT sourceID FROM factChat WHERE sourceID >= @sourceIDi
SQL Server returns around 822.000 rows, which is approximately 10% of data in the whole table.
One would expect that SQL Server uses an index on SourceID, but let’s check if that’s the case:
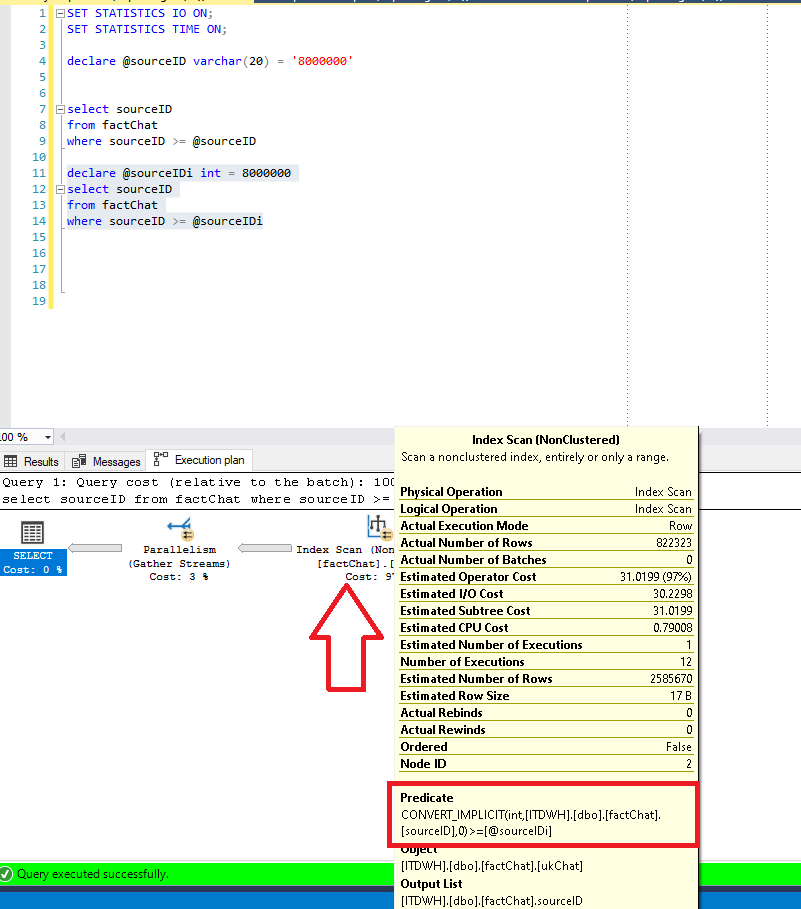
As we can notice, SQL Server uses our index, but instead of choosing to perform expected Index Seek operation, it scans the index. And if we hover over the Index Scan step, we will see in Predicate pane that implicit conversion occurred, since SQL Server had to apply data conversion behind the scenes during the query process.
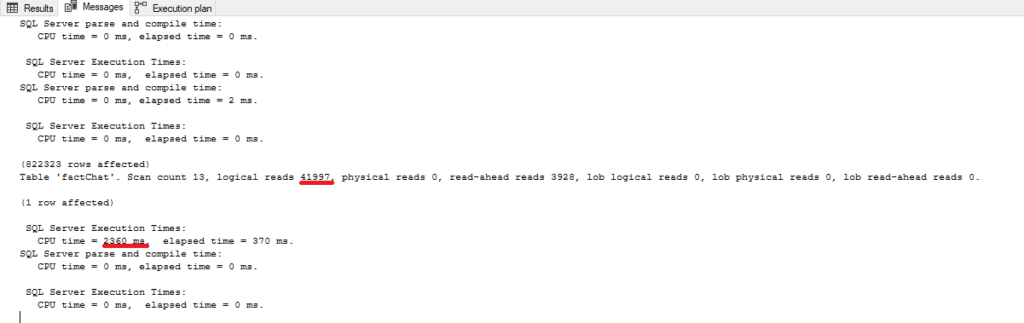
That action has many additional impacts on performance – just looking at a number of logical reads and CPU costs, we can conclude that this is far from the optimal performance:
Query #2 AKA “Good Guy 1”
Now, let’s check how SQL Server reacts when we provide it with matching data type:
DECLARE @sourceID varchar(20) = '8000000' SELECT sourceID FROM factChat WHERE sourceID >= @sourceID
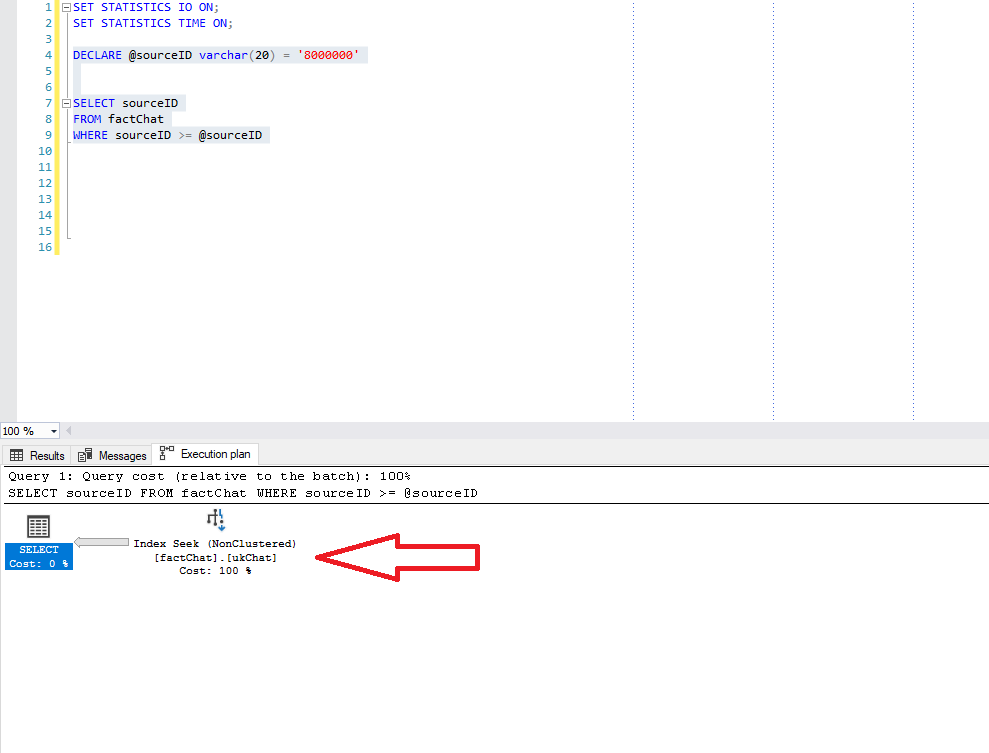
Now, SQL Server performs Index Seek as expected, so let’s additionally check what SQL Server did in the background to get our results back:
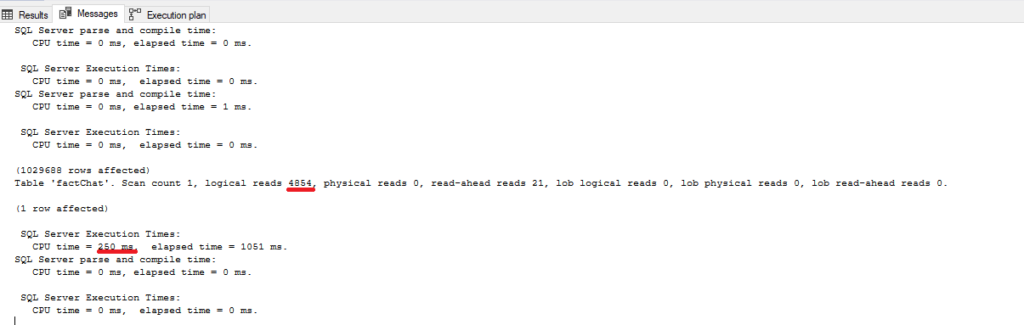
Woohoo, almost 10 times less logical reads and CPU time! And just because SQL Server didn’t have to push hard to apply implicit conversion during the query process.
Now, just imagine the difference in performance on a larger portion of data (remember, this query returned only 10% of data within the table), or on larger tables.
Query #3 AKA “Good Guy 2”
Now, I want to show you another way of helping SQL Server to do what it best does – choose an optimal plan for executing our queries.
Instead of giving SQL Server proper data type in our variable definition, we can still use INT data type, but we can later EXPLICITLY tell SQL Server that we want to compare “apples” with “apples” (in our case, VARCHAR with VARCHAR):
DECLARE @sourceIDi INT = 8000000 SELECT sourceID FROM factChat WHERE sourceID >= CAST(@sourceIDi AS VARCHAR(20))
What we did here? We explicitly notified SQL Server what we want him to do: compare VARCHAR(20) column SourceID with VARCHAR(20) value of the variable.
And SQL Server is grateful, as we can see if we look at the results:
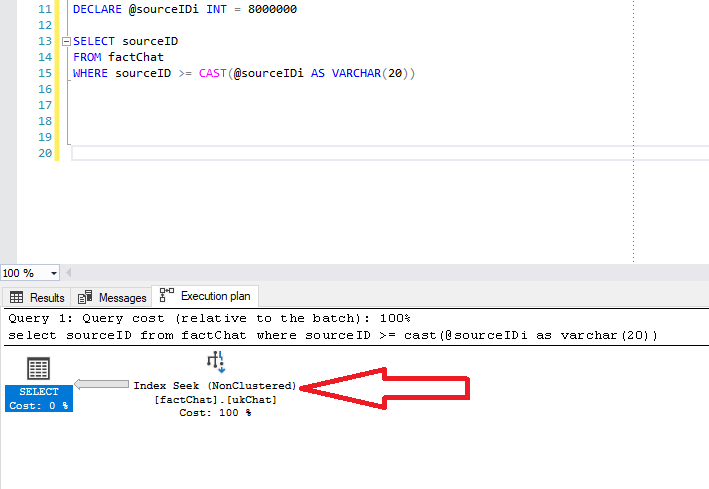
For the beginning, Index Seek operation is there. Let’s check statistics:
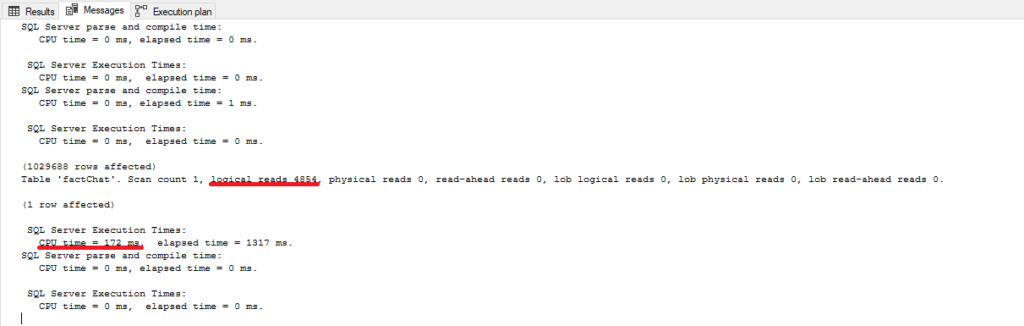
Numbers are similar as in the previous run, so we can conclude that these two perform almost identical.
Conclusion
Implicit Conversion can be a huuuuge performance killer and it is especially dangerous because it’s not so obvious and easy to spot.
Therefore, I recommend checking this article written by Jonathan Kehayias, where he provides a very useful script for identifying implicit conversions in your plan cache.
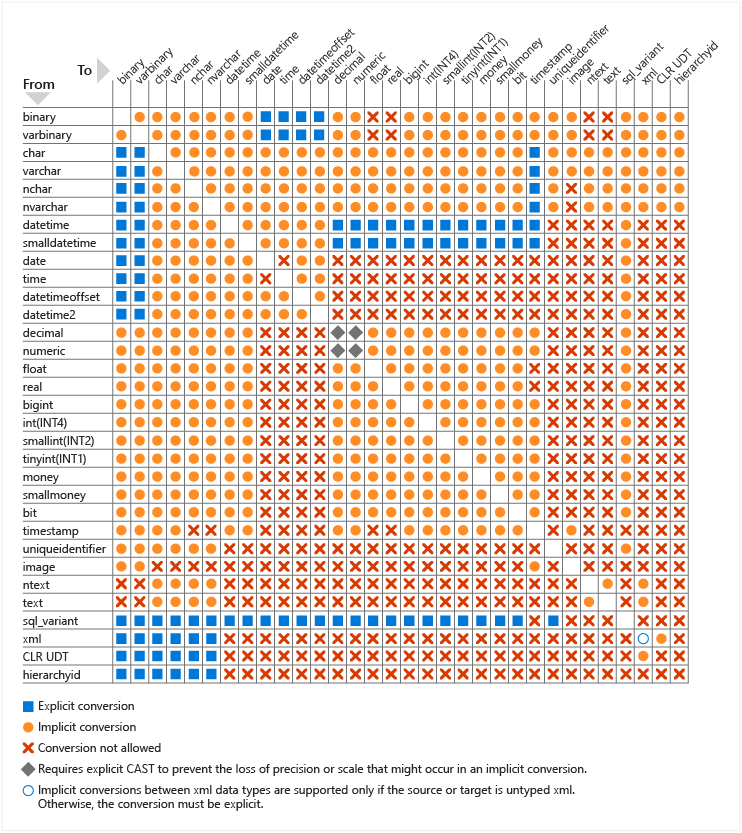
Additionally, if you want to be sure when an implicit conversion occurs, check this super useful table provided by Microsoft directly:
Update:
Thanks to a suggestion from Milos Radivojevic, whom I consider one of the greatest SQL Server experts around, I need to expand on the explanation of data type precedence, which affects implicit conversion.
Data type precedence can be found here and it helps to understand how SQL Server will handle data type conversions. For example, INT has higher precedence than VARCHAR, which means that SQL Server will convert VARCHAR to INT, not the other way around.
Therefore, if you compare a column of type INT with values of type VARCHAR, your index can still be used, because the column for comparison doesn’t need transformation.
Additionally, when comparing types from the same “family” (for example, INT and BIGINT) SQL Server will still prefer Index Seek operation, since it is smart enough to recognize those cases and use an appropriate index.
To conclude, as a general rule of thumb: one should not count on SQL Server “mercy” or scratching his head with data type precedence – data types should match whenever possible, or comparison should be eventually handled using explicit conversion.
Last Updated on July 6, 2020 by Nikola


