“We are creating a custom dashboard using code, and we need the data stored inside Microsoft Fabric. Can we access it in another way than via SQL Analytics Endpoint?”
This is a real-life customer requirement we’ve encountered recently. And the short answer is: Yes, you can! For the longer answer, we encourage you to read this article and understand how to leverage the Fabric API for GraphQL feature for enhanced data retrieval experience compared to the traditional REST API approach.
This is the excerpt from the early release of the “Fundamentals of Microsoft Fabric” book, that I’m writing together with Ben Weissman (X) for O’Reilly. You can already read the early release, which is updated chapter by chapter, here.

Honestly, the official name – Fabric API for GraphQL – sounds too scary even for experienced data professionals, let alone someone who just started their Fabric learning journey, unless you are a seasoned application developer. Hence, let’s first try to demystify core concepts of this feature.
First and foremost, GraphQL is a query language. You might have already assumed that from its name – QL stands for query language. To bring this one step further: it’s not ANY query language, it’s a query language for the API. It’s an open-source protocol and has been successfully implemented in numerous programming languages. Since GraphQL is an API query language, it isn’t bonded to any particular database engine or vendor.
From a high-level perspective, the main advantages of GraphQL compared to REST APIs are:
- Flexibility – GraphQL allows you to define individual columns that you need to extract, whereas most REST APIs provide a standard response only
- Efficiency – GraphQL enables combining multiple queries in a single call. A simple example would be the possibility of joining tables in the GraphQL query. In GraphQL, this will result in a single call, while in the REST API, this would produce multiple calls
Core GraphQL operations
GraphQL supports three operation types:
- Query – this is the essential operation type of GraphQL. To some extent, GraphQL queries remind us of SQL queries, at least from a logical point of view: we can select specific fields from the table, we can join multiple tables, we can filter and sort the data, and so on
- Mutation – this corresponds to commands that enable data modification on the server side. Think of this type as an equivalent to CREATE, UPDATE, and DELETE statements in SQL, but there are also other custom operations in addition
- Subscription – allows subscribing to real-time data. You can subscribe to a particular event, such as data deletion or user creation, and whenever the event occurs, the server will send the data to a GraphQL query
At the moment of writing (November 2024), Microsoft Fabric supports only Query and Mutation operation types for GraphQL.
Working with GraphQL in Fabric
Before we explain how to create and execute GraphQL queries in Microsoft Fabric, let’s first take a brief overview of the currently supported operations based on the Fabric item type. Table below shows which GraphQL operations can be performed in Fabric items:
| Fabric item type | GraphQL operation type |
| Warehouse | Query/Mutation |
| Lakehouse | Query |
| Mirrored database | Query |
| SQL database in Fabric | Query/Mutation |
| Azure SQL DB | Query/Mutation |
As you may notice, only Fabric Warehouse, Azure SQL DB, and SQL database in Fabric currently allow for modifying the data. If you want to learn more about the latest addition to Fabric, SQL database in Fabric, I encourage you to read this article.
A single GraphQL item can be leveraged to query multiple Warehouse, Lakehouse, Mirrored database, and SQL database items simultaneously, although it is not possible to create relationships between these items. Relationships are currently supported only in the scope of the single item.
Let’s now put the GraphQL feature into action. As you can see in the following figure, as a prerequisite, the feature has to be enabled in the Admin portal of your Fabric tenant:
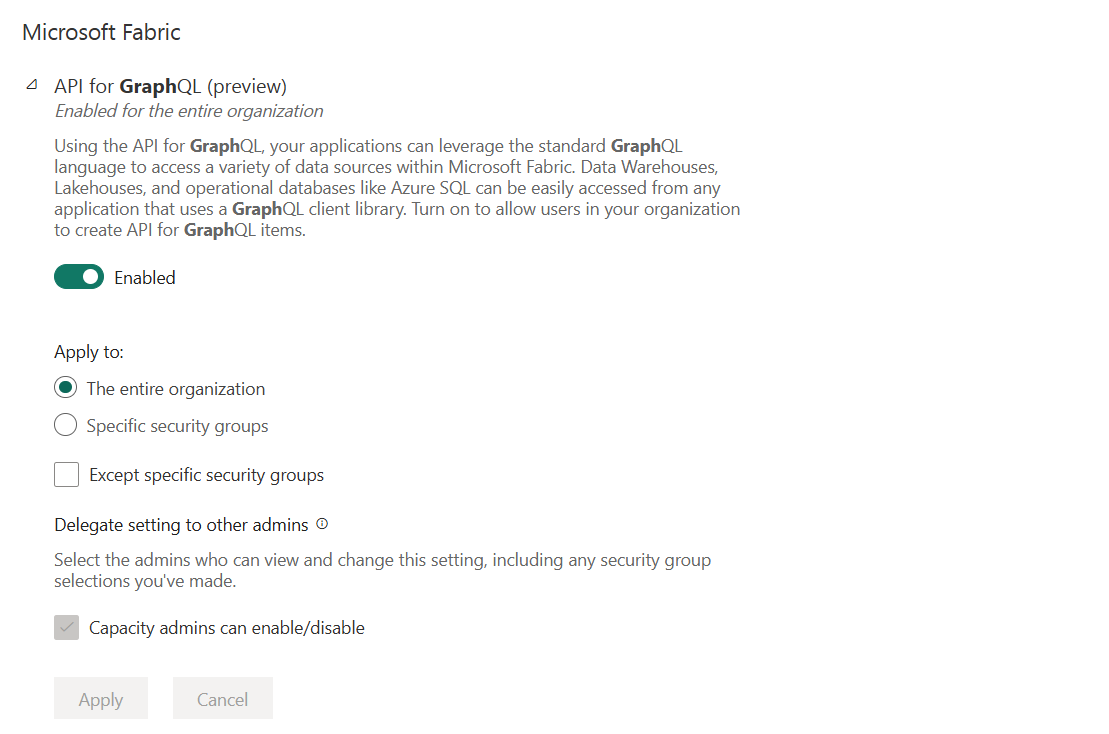
Once enabled, API for GraphQL is available for all Fabric item types that support this feature. These are the items specified in table above. This means, it’s not possible to implement a more granular control and enable GraphQL for, let’s say, lakehouses or warehouses only.
Query the data with API for GraphQL
Let’s first retrieve the data from individual Fabric Warehouse tables. The following code snippet executed from the API for GraphQL item will retrieve the data from specific columns of the dimProducts and dimCustomers tables:
query {
dimProducts { #Table 1 name
items { #Columns to be included in the query
ProductKey,
EnglishProductName,
Color,
Class
}
}
,
dimCustomers { #Table 2 name
items { #Columns to be included in the query
CustomerKey,
FirstName,
LastName,
Gender
}
}
}
This is the basic query, which will retrieve all the records from the columns we defined in the query. However, what if we are interested only in a subset of records or potentially in a single record from the table? We have bad and good news here – the bad news is that you can’t rely on traditional operators, such as “>”, “>=”, “<”, or “<=”. However, the good news is that we can still filter the data by substituting these operators with their verbose relatives. Hence, “=” becomes eq, “>” becomes gt (greater than), “<” becomes lt (lower than), and so on, as displayed in the following table:
| GraphQL operator | Operation |
| eq | equal to |
| neq | not equal to |
| gt | greater than |
| lt | Lower than |
| gte | Greater than or equal to |
| lte | Lower than or equal to |
| isNull | Check if the value is null |
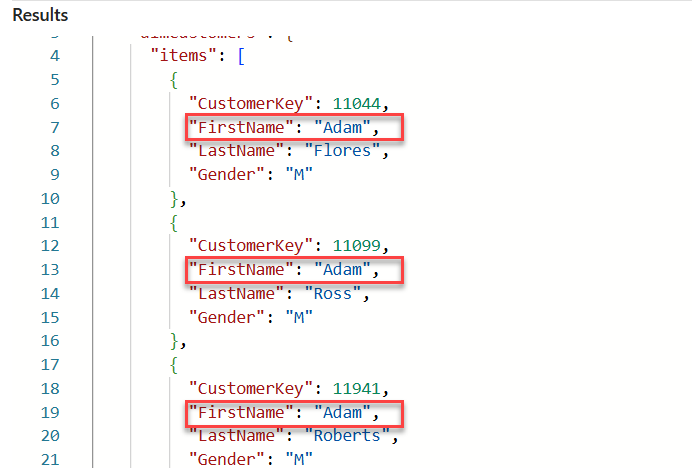
Imagine that you need to retrieve the data for customers whose first name equals Adam. Here is the code snippet that will meet this requirement:
query {
dimCustomers
(filter: {FirstName: {
eq:"Adam"
}}) {
items {
CustomerKey,
FirstName,
LastName,
Gender
}
}
}
The following illustration displays the sample of results retrieved by the query:
Creating relationships
Relationships in API for GraphQL, like those in traditional relational database management systems, allow combining data from multiple tables in the same query. Relationship properties are configured from the New relationship dialog window, as displayed in the illustration below. You should click on the three dots next to the schema name and then select the Manage relationships option:
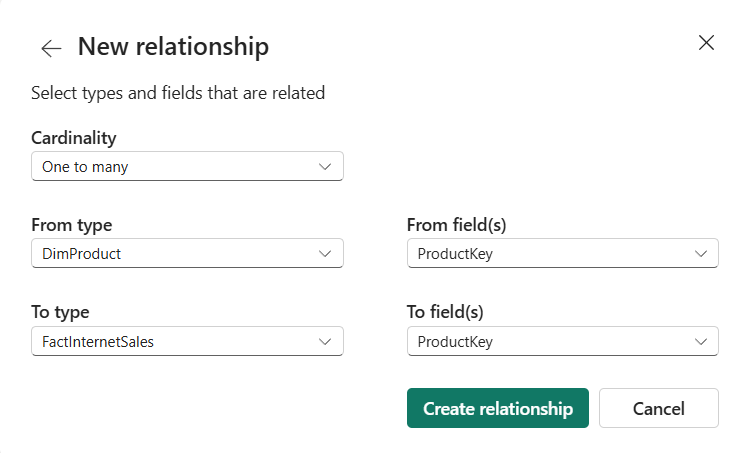
Here, we are establishing a relationship with one-to-many cardinality between the DimProduct and FactInternetSales tables on the common column ProductKey.
Let’s now generate a query that will retrieve combined data from both DimProduct and FactInternetSales tables. The following code snippet represents the query that retrieves all blue products and relevant sales order numbers from the FactInternetSales table, including the Sales Amount value. Additionally, we are sorting the data on the SalesAmount column in descending order:
query {
dimProducts
(filter: {Color:{eq:"Blue"}}) {
items {
Color,
EnglishProductName
factInternetSales
(orderBy: {SalesAmount: DESC}){
items{
SalesOrderNumber,
SalesAmount
}
}
}
}
}
Making changes by using mutations
Mutations are a very powerful feature of API for GraphQL, as they enable data manipulation in the Fabric Warehouse. As displayed in the following figure, mutations for executing the CREATE statement are automatically included in the Schema explorer of the GraphQL item:
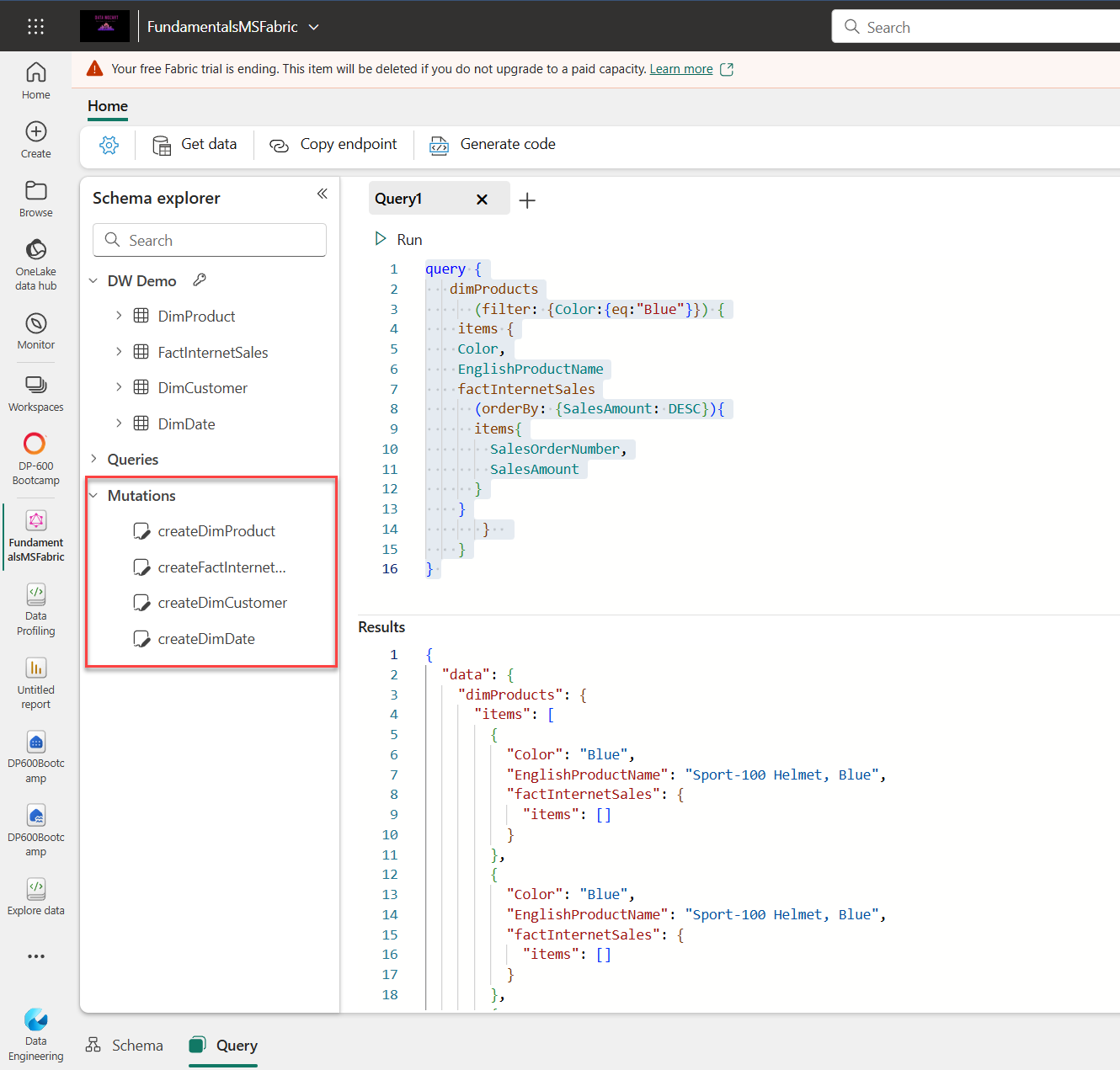
Hence, if we want to create a new record in the DimProduct table, we can leverage the existing mutation createDimProduct, as shown in the following code snippet:
mutation {
createDimProduct(
item: { ProductKey: 99999, EnglishProductName: "Fundamentals of Microsoft Fabric" }) {
result # Required to return the result of the mutation execution
}
}
The following illustration confirms that our record was successfully created in the DimProduct table:
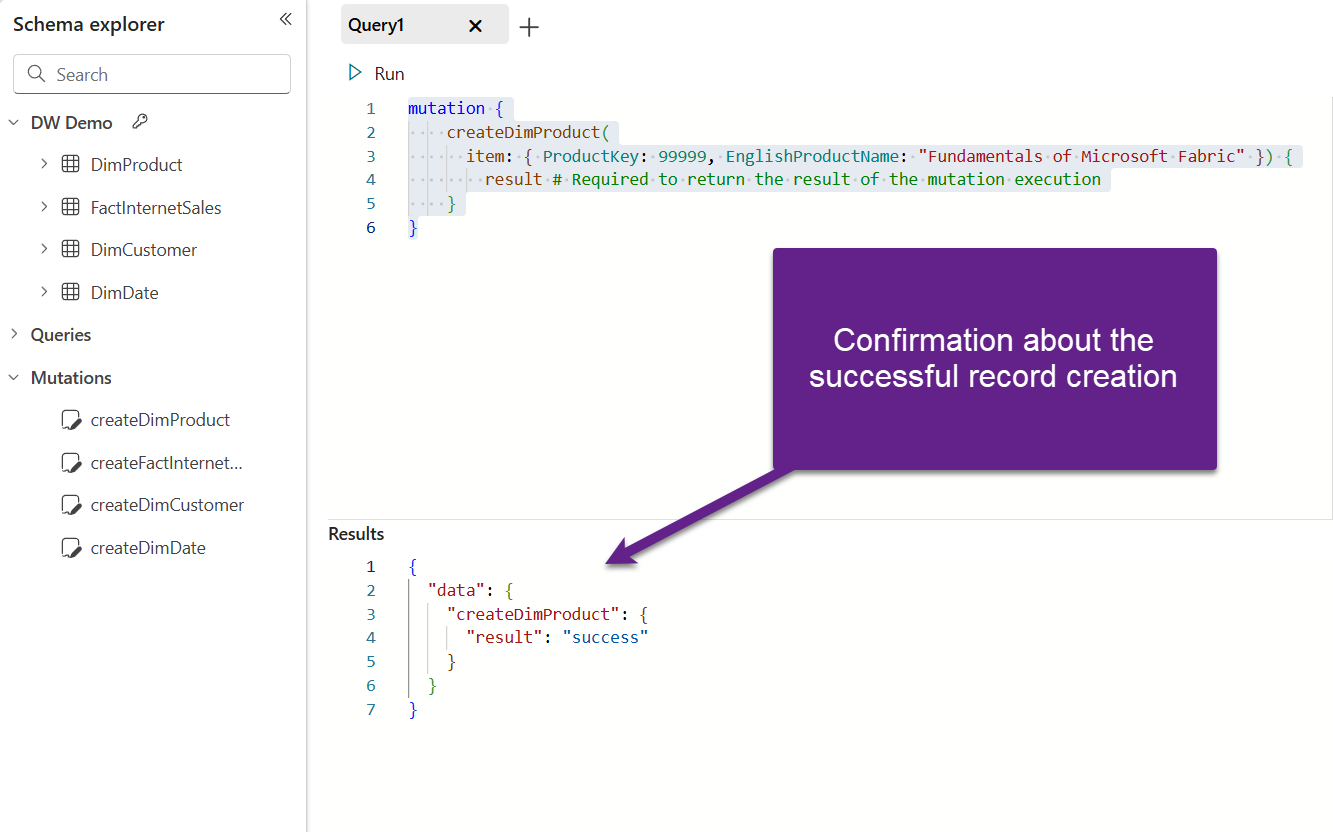
Let’s examine how to delete records from a specific table. Depending on how your table in the Fabric Warehouse was created, this may be performed in two different ways.
- If the table was created without a PRIMARY KEY constraint, UPDATE and DELETE operations are NOT available out-of-the-box
- If the table was created with a PRIMARY KEY constraint, even though this constraint must be specified as not enforced in the Fabric Warehouse, UPDATE and DELETE operations are available out-of-the-box
Let’s examine how to apply mutation operation for both scenarios.
Since DELETE mutations are not available out-of-the-box in the Schema explorer for tables without a primary key, we need to extend our toolbox and leverage stored procedures from the Warehouse. Explaining the concept of stored procedures and the benefits of using stored procedures is outside of the scope of this book.
To apply DELETE and UPDATE operations with API for GraphQL for tables with no primary key constraint, as a prerequisite, you must encapsulate transaction logic inside regular stored procedures in the Fabric Warehouse and then execute these procedures inside the GraphQL item
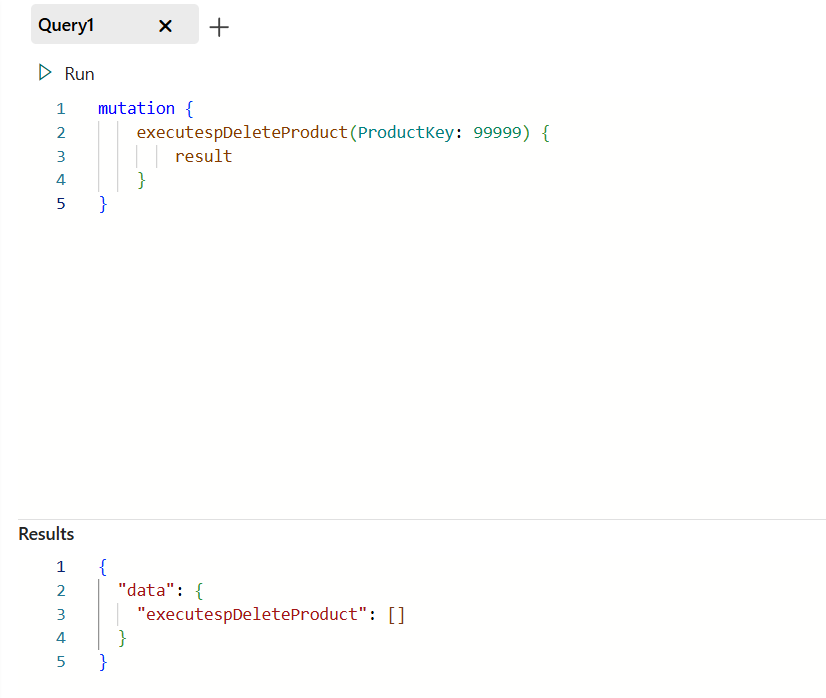
We’ve already created a basic stored procedure spDeleteProduct. This procedure takes the ProductKey input parameter and deletes the record from the DimProduct table where the ProductKey value is equal to the value defined in the parameter. The following code snippet was used to create the stored procedure:
CREATE PROC [dbo].[spDeleteProduct] @ProductKey int AS BEGIN DELETE FROM DimProduct WHERE ProductKey = @ProductKey END
We can now execute this procedure from API for GraphQL and pass the parameter value we want to use. In the illustration below, you may notice that I’m deleting the product with the ProductKey 99999 that we previously created:
Using similar logic, we can also update the existing records in the table. Again, to achieve this with the API for GraphQL, we need to create a stored procedure in Fabric Warehouse as the first step. From the GraphQL item, the execution logic and the code syntax are the same as in the previous example with the DELETE statement – it’s only the stored procedure inner logic that differs from the previous scenario, as you might want to execute the update statement instead of delete.
Let’s examine how to perform DELETE and/or UPDATE operations for tables with a primary key constraint. As you’ll notice, it’s a more straightforward process compared to the previous scenario.
Using the following code snippet, I’ll create a table DimProductWithConstraint and define a primary key constraint on the ProductKey column.
CREATE TABLE DimProductWithConstraint
(ProductKey INT NOT NULL
,ProductAlternateKey VARCHAR(100) NOT NULL
,EnglishProductName VARCHAR(100) NOT NULL
)
ALTER TABLE DimProductWithConstraint
ADD CONSTRAINT PK_Product PRIMARY KEY NONCLUSTERED (ProductKey) NOT ENFORCED;
INSERT INTO DimProductWithConstraint
SELECT ProductKey
,ProductAlternateKey
,EnglishProductName
FROM DimProduct
Please be aware that the primary key column can’t be nullable, or your query won’t work. Additionally, keep in mind that all constraints in Fabric Warehouse MUST be wrapped with the NOT ENFORCED clause. If you are coming from a traditional SQL Server world, this may come as a huge shock. However, all key constraints in Fabric Warehouse are supported only when NOT ENFORCED is used. You can read more about these requirements in the official Microsoft documentation.
Going back to our GraphQL item, when we define a table with a primary key constraint, ALL mutation operations are automatically available in the Schema explorer. Once I updated the schema, as you may see in the figure below, all three mutation operations – create, update, and delete – are available for the DimProductWithConstraint table:
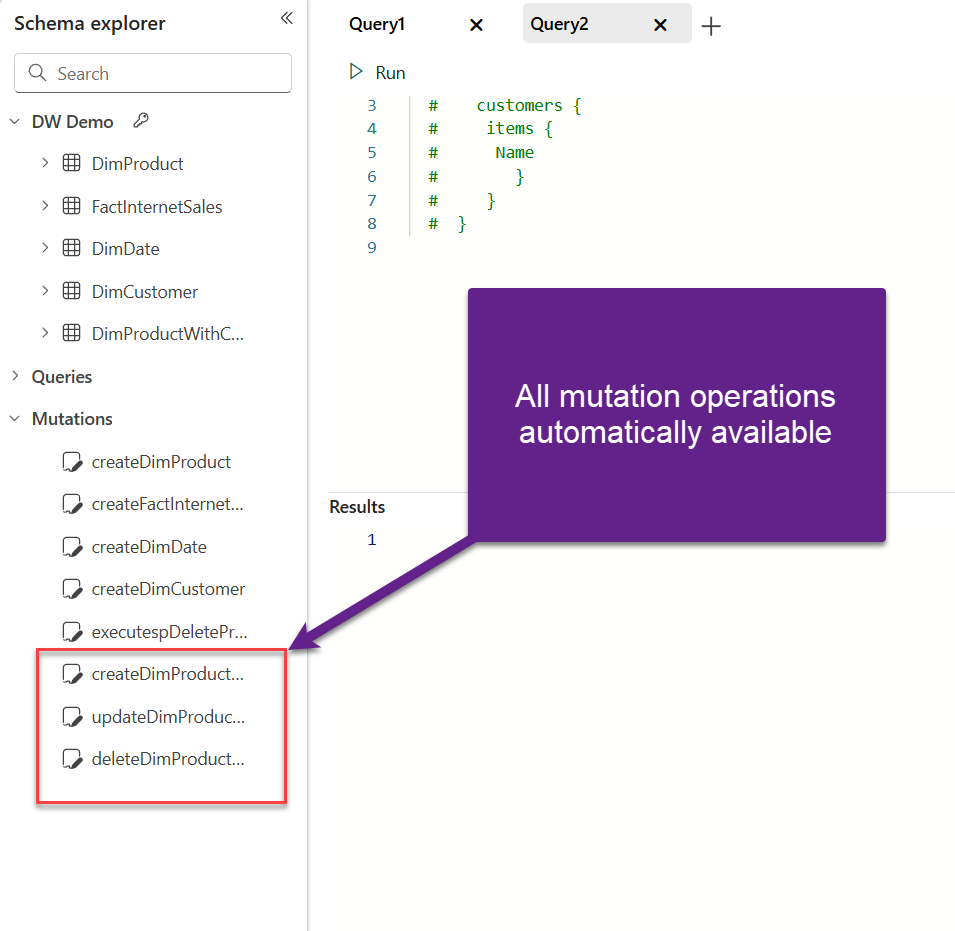
To wrap up this section – if tables in the Warehouse were created with primary key constraints, all mutation operations (create, update, and delete) in the GraphQL item would be created automatically. On the flip side, when tables don’t have a primary key explicitly defined, only the create operation is available out-of-the-box, whereas for the update and delete operations, you need to leverage stored procedures.
Going above and beyond with variables
As in other programming languages, you may find the concept of variables helpful in scenarios where you need to filter the data based on user input or when you want to reuse the same query with different parameter values.
The following illustration depicts how you can define variables within the Query variables window of the GraphQL item and pass this value to the Mutation operation:

Variables can also be leveraged in query operations. In the following example, we are dynamically setting multiple filters for the query:
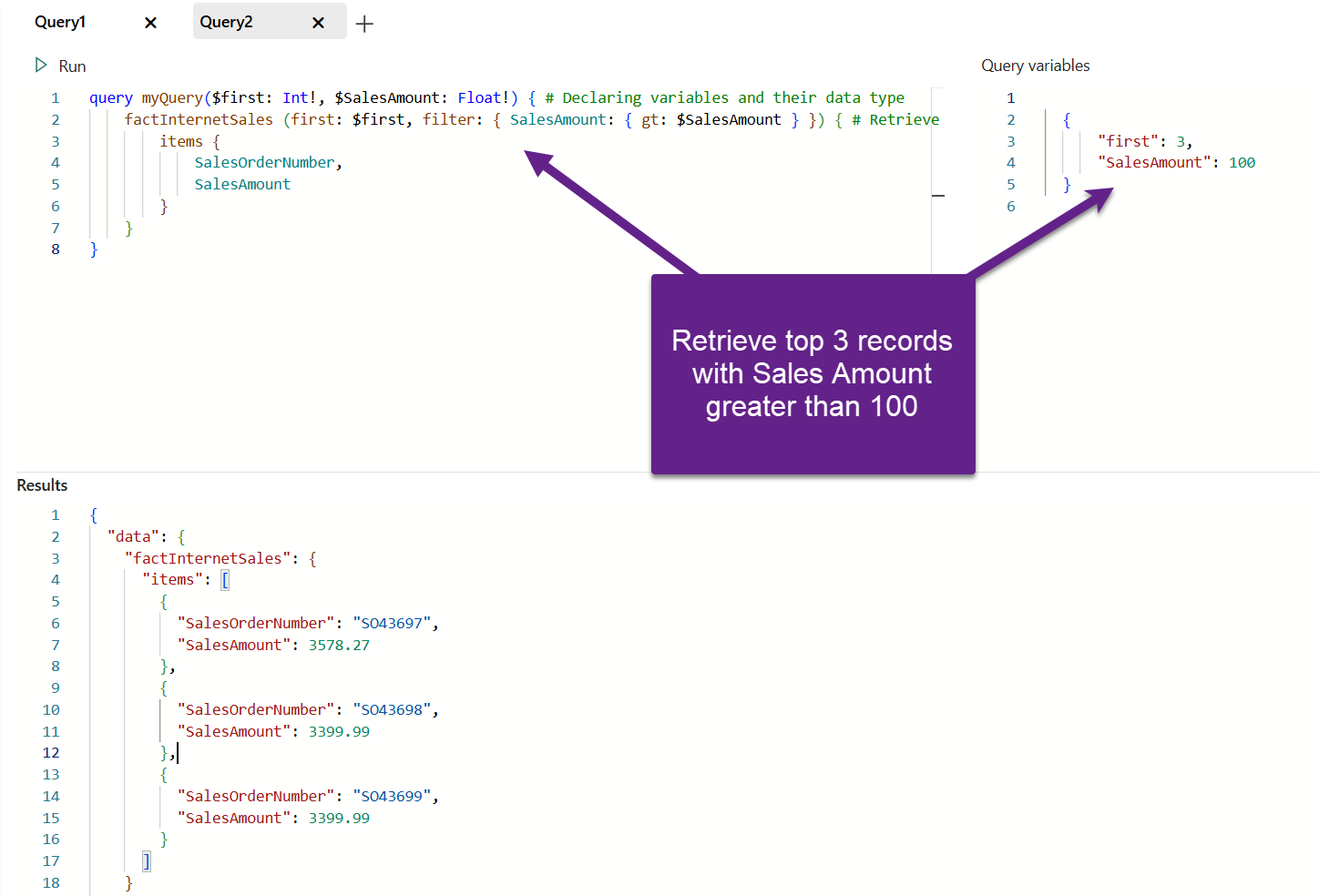
Conclusion
Although API for GraphQL might not look like a groundbreaking feature at first glance and probably won’t be frequently used by data engineers and Fabric admins, we still consider it a huge leap forward compared to the traditional way of dealing with API-related scenarios. Therefore, we are convinced that application developers, as a primary target group for this feature, will appreciate the possibility of leveraging GraphQL items in Microsoft Fabric.
Due to its portability and programming-language-independency, GraphQL opens a whole new world of options for querying and manipulating the data stored in Microsoft Fabric. Finally, by providing a rich set of features, such as querying data from multiple tables by sending a single query, creating relationships between tables, applying modifications to the data, and executing stored procedures, we are sure that GraphQL popularity will increase over time, and that it will soon become a de-facto standard when working with APIs.
Thanks for reading!
Credits:
Last Updated on November 21, 2024 by Nikola